






一、为什么要进行误差分析
进行误差分析是为了理解和改进模型的性能。误差分析可以帮助我们了解模型在预测新数据时的准确性,以及模型在特定数据集上的表现如何。这对于以下几个方面至关重要:
1.模型评估
误差分析使我们能够评估模型的预测能力,了解模型在何种程度上捕捉到了数据的真实关系
2.模型优化
通过分析误差,我们可以识别模型的不足之处,并据此调整模型结构或算法,以减少预测误差,提高模型的准确性和可靠性
3.泛化能力
误差分析有助于评估模型对未知数据的泛化能力,即模型在新数据集上的表现如何。这对于实际应用中的模型部署至关重要
4.决策支持
在商业和科研决策过程中,了解模型的误差情况可以帮助决策者更好的理解模型的局限性和适用范围,从而做出更明智的决策
所以说,误差分析是机器学习和数据分析中的一个重要环节,它不仅帮助我们对现有模型进行评估和优化,也为我们提供了关于模型性能的重要信息,以便我们在实际应用中做出合理的决策。
二、分析线性回归模型的误差与样本容量之间的关系
1.错误度量
使用均方误差(MSE)作为评估模型性能的指标。MSE量化了预测值与实际值之间平均平方差。为了在图表上更容易阅读,实际上绘制了MSE的平方根(即均方根误差,RMSE)
train_errors.append(mean_squared_error(y_train_predict, y_train[:m]))
val_errors.append(mean_squared_error(y_val_predict, y_val))2.学习曲线
学习曲线是表示随着使用的样本数量的增加,模型的训练和验证错误率如何变化的图表。他们有助于可视化模型性能随着数据量的增加而如何提高
plt.plot(np.sqrt(train_errors), "r-+", linewidth=2, label="train")
plt.plot(np.sqrt(val_errors), "b-", linewidth=3, label="val")3.模型拟合
代码使用scikit-learn中的linear_model.LinearRegression()类创建线性回归模型。在循环中多次调用fit方法,每次使用不同数量的训练样本,从只有一个样本开始。
from sklearn import linear_model # 导入scikit-learn库中的线性模型模块4.数据分割
train_test_split函数将数据集分割成训练集和验证集。这里的分割比例是80/20。训练集用于拟合模型,而验证集用于评估其性能。
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2)5.逐步拟合
循环range(1, len(X_train))通过一次增加一个样本的方式逐步增大训练集的大小。这允许我们观察在更多数据被纳入训练过程时,模型的误差如何变化。
for m in range(1, len(X_train)):
6.绘图
使用Matplotlib的pyplot模块绘制学习曲线。x轴代表训练集的大小(以训练样本的数量表示)
plt.xlabel("Training set size")
plt.ylabel("RMSE")7.数据生成
代码首先生成一个100行1列的随机数组作为特征矩阵X,每个元素的值在-3到3之间。然后生成一个目标向量y,它是X的非线性函数加上一些随机噪音。
m = 100 # 设置样本容量为100
X = 6 * np.random.rand(m, 1) - 3 # 生成一个100×1的随机数组作为特征矩阵X 每个元素的范围是[-3.3]
y = 0.5 * X ** 2 + X + 2 + np.random.randn(m, 1) # 生成一个目标向量y 它是X的非线性函数加上一些随机噪声8.模型实例化
代码实例化一个线性回归模型对象,准备用于拟合和预测。
lin_reg = linear_model.LinearRegression() # 创建一个线性回归模型对象9.绘制学习曲线
调用plot_learning_curves函数,传入线性回归模型、特征矩阵和目标向量,并显示绘制出的学习曲线图。
plot_learning_curves(lin_reg, X, y) # 传入线性回归模型、特征矩阵和目标向量
plt.show() # 显示绘制出的学习曲线图
通过以上分析,我们可以了解到随着训练样本数量的增加,线性回归模型的性能是如何变化的,从而帮助我们判断在实际应用中需要多少数据才能达到满意的模型性能。
三、模型实现
总代码:
import numpy as np # 导入numpy库 提供数学计算的支持
import matplotlib.pyplot as plt # 导入matplotlib的pyplot模块 用于绘图
from sklearn import linear_model # 导入scikit-learn库中的线性模型模块
from sklearn.metrics import mean_squared_error # 导入误差评估库
from sklearn.model_selection import train_test_split # 导入用于分割训练集和验证集的库
# 评估梯度下降法的线性回归模型的误差与样本容量之间的关系。
def plot_learning_curves(model, X, y): # 定义绘制曲线的函数 用于绘制学习曲线
# 将数据集分为训练集和验证集 测试集的比例是20%
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2)
# 初始化两个空列表 用于存储训练误差和验证误差
train_errors, val_errors = [], []
# 循环遍历训练集数据点
for m in range(1, len(X_train)):
# 使用前m个数据点来训练模型
model.fit(X_train[:m], y_train[:m])
# 使用训练好的模型预测训练集的目标值
y_train_predict = model.predict(X_train[:m])
# 使用训练好的模型预测验证集的目标值
y_val_predict = model.predict(X_val)
# train_errors表示训练误差,val_errors表示验证误差
# 将训练集的均方误差添加到train_errors列表中
train_errors.append(mean_squared_error(y_train_predict, y_train[:m]))
# 将验证集的均方误差添加到val_errors列表中
val_errors.append(mean_squared_error(y_val_predict, y_val))
# 使用matplotlib绘制训练误差的曲线 使用红色的虚线加加号标记 线宽为2
plt.plot(np.sqrt(train_errors), "r-+", linewidth=2, label="train")
# 使用matplotlib绘制验证误差的曲线 使用蓝色的虚线加加号标记 线宽为3
plt.plot(np.sqrt(val_errors), "b-", linewidth=3, label="val")
# 设置x轴标签为 Training set size
plt.xlabel("Training set size")
# 设置y轴标签 RMSE(均方根误差)
plt.ylabel("RMSE")
plt.legend() # 显示图例
m = 100 # 设置样本容量为100
X = 6 * np.random.rand(m, 1) - 3 # 生成一个100×1的随机数组作为特征矩阵X 每个元素的范围是[-3.3]
y = 0.5 * X ** 2 + X + 2 + np.random.randn(m, 1) # 生成一个目标向量y 它是X的非线性函数加上一些随机噪声
lin_reg = linear_model.LinearRegression() # 创建一个线性回归模型对象
plot_learning_curves(lin_reg, X, y) # 传入线性回归模型、特征矩阵和目标向量
plt.show() # 显示绘制出的学习曲线图
运行结果:
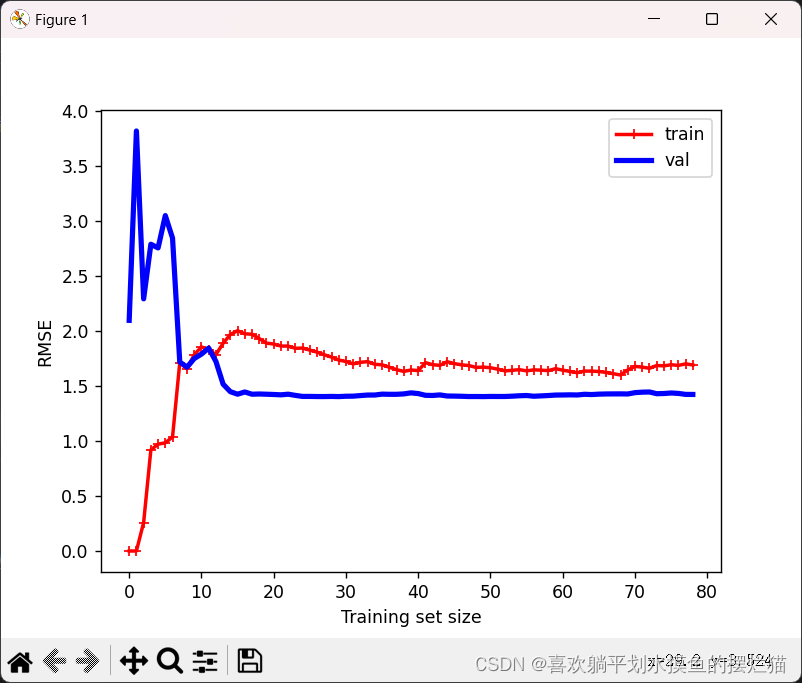
结果分析:
可以看出,随着样本数量的增加,尤其是当样本达到一定数量时,验证误差迅速减小,训练误差和验证误差之间的差距不大且基本维持稳定。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









