






全年无故障率(非计划内故障停机)
99.9% 0.001*365*24*60 525.6Min
99.99% 0.0001*365*24*60 52.56Min
99.999% 0.00001*365*24*60 5.256Min 金融级别
高可用架构方案
- 负载均衡:有一定的高可用性
LVS、Nginx、haproxy
- 主备系统:有高可用性,但是需要10-30s切换,是单活的架构
Keepalived、MHA、MMM
- 真正高可用(多活系统)
NDB Cluster、Oracle RAC、Sybase cluster、InnoDB Cluster(MGR)、PXC(percona)、MGC(mariadb)
MySQL Replication(主从复制)
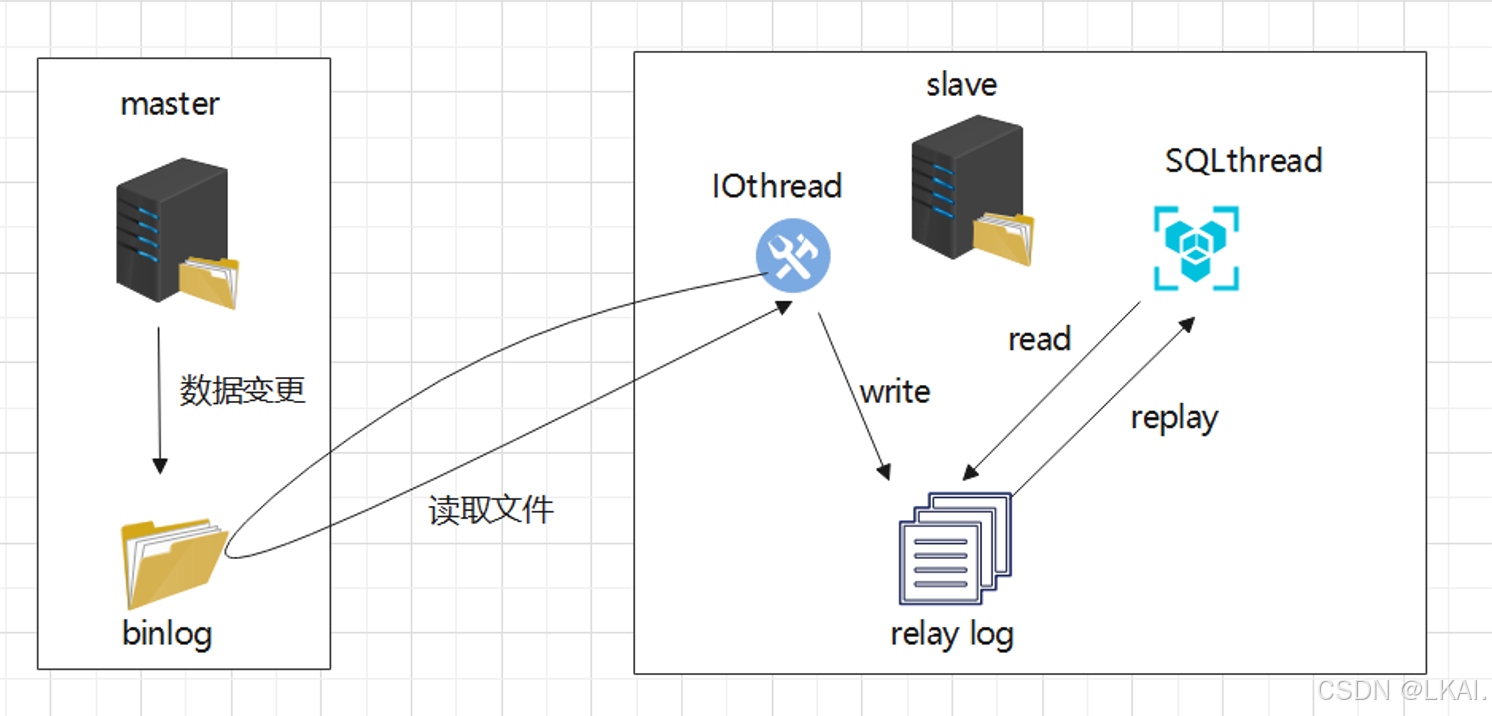
io线程负责抓取master的二进制,放到自己的日志文件(中继日志)。日志文件有了新数据,那么sql线程就会起作用。sql线程执行中继日志,从而和master保持一致。
DBA职责(关于主从复制)
搭建主从复制
主从原理熟悉
主从的故障处理
主从延时,同步不及时
主从的特殊架构(过滤复制、延时从库)的配置使用
主从架构的演变(读写分离、高可用、分布式架构)
主从复制介绍
主从复制基于binlog来实现的
主库发生新的操作,都会记录binlog
从库取得主库的binlog进行回放
主从复制的过程是异步
主从复制的前提 (搭建主从复制)
2个或以上的数据库实例
主库需要开启二进制日志
server_id要不同,区分不同的节点
主库需要建立专用的复制用户 (replication slave)
从库应该通过备份主库、恢复的方法进行复制历史数据
人为告诉从库一些复制信息(ip port user pass,二进制日志起点)
从库应该开启专门的复制线程
实验环境

安装MySQL5.7
实验步骤
1、修改配置文件
Master:
vim /etc/my.cnf
修改添加:
log_bin=/data/binlog/master-bin
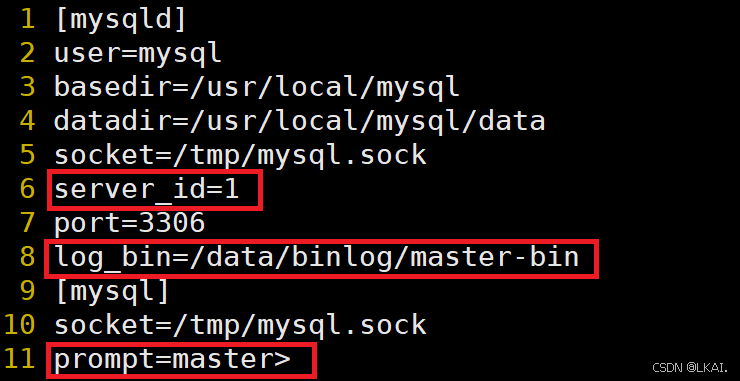
mkdir -p /data/binlog
chown -R mysql.mysql /data
systemctl restart mysqld
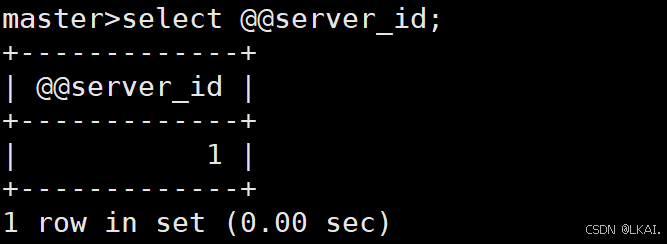
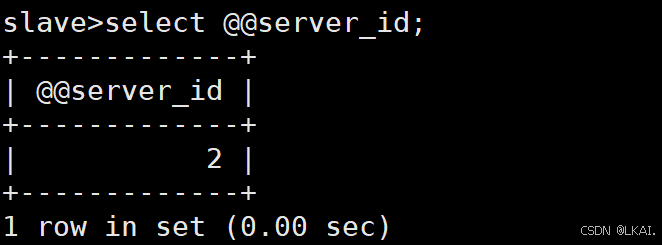
查询server_id:
select @@server_id;
Slave:
vim /etc/my.cnf
修改添加:
log_bin=/data/binlog/slave-bin
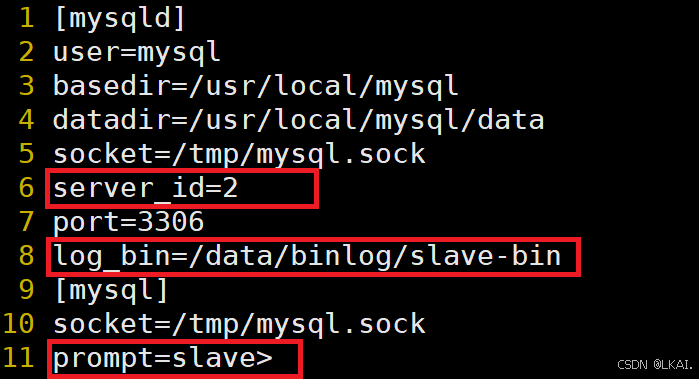
mkdir -p /data/binlog
chown -R mysql.mysql /data
systemctl restart mysqld
查询server_id:
select @@server_id;
2、Master库创建复制用户(Master)
grant replication slave on *.* to ‘repl’@'192.168.8.%' identified by '123.com';

3、模拟Master数据库有数据(Master)
导入数据:
将world.sql和t100w.sql拖入/root目录
source world.sql
create database t100w;
use t100w;
source t100w.sql
4、备份Master数据库(Master)
mysqldump -uroot -p123.com -A --master-data=2 --single-transaction -R -E --triggers > /tmp/full.sql

5、导入数据
Master:
scp /tmp/full.sql root@192.168.8.6:/root
Slave:
set sql_log_bin=0;
source /root/full.sql
set sql_log_bin=1;
6、查看Master库的二进制日志名和Position号(Master)
show master status;

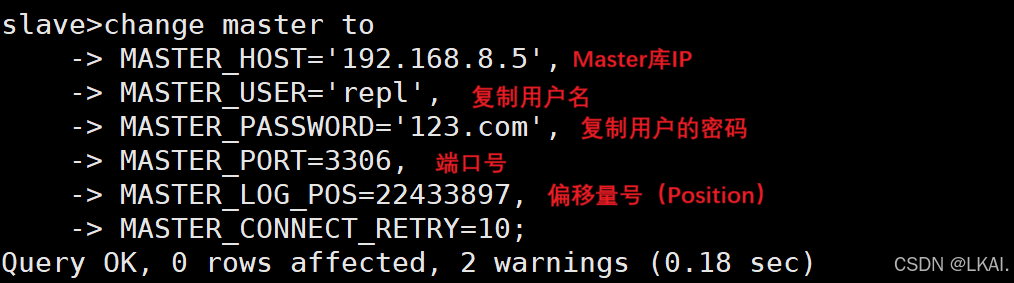
7、Slave库使用命令连接Master库(Slave)
change master to
MASTER_HOST='192.168.8.5',
MASTER_USER='repl',
MASTER_PASSWORD='123.com',
MASTER_PORT=3306,
MASTER_LOG_POS=22433897,
MASTER_CONNECT_RETRY=10;
8、Slave开启复制线程(IO、SQL)(Slave)
start slave;

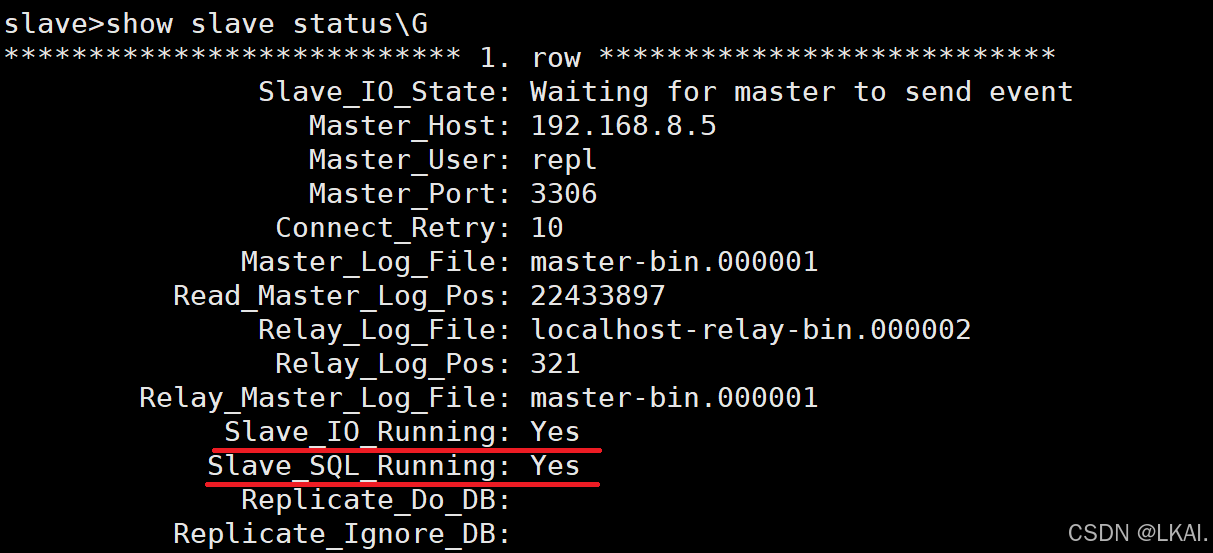
9、查看主从复制状态(Slave)
show slave status\G
测试:
Master:
写入数据
create database ms;
use ms;
create table t1(id int,name varchar(20));
insert into t1 values(1,'aa'),(2,'bb'),(3,'cc');
查看二进制日志
show master status;

Slave:
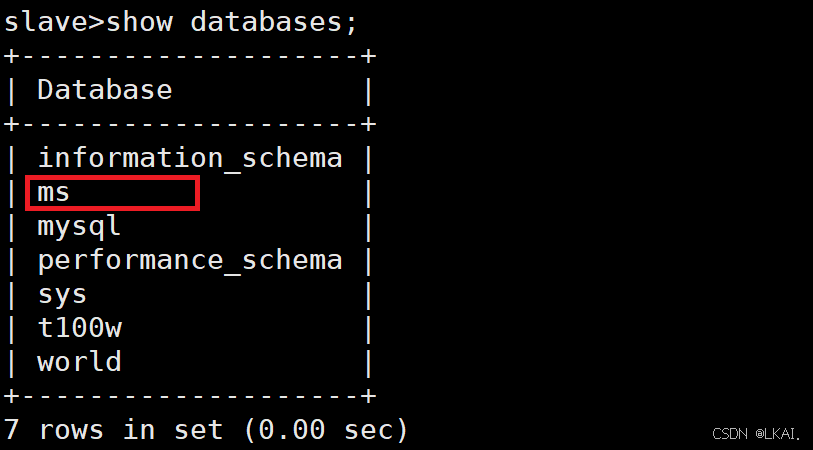
查看数据
show databases;
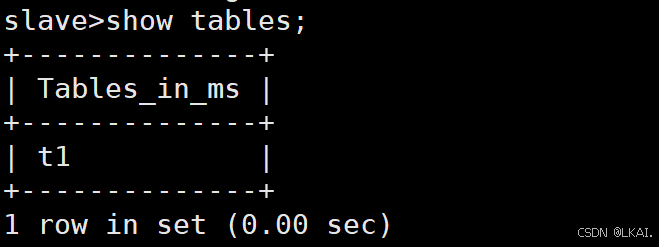
use ms;
show tables;
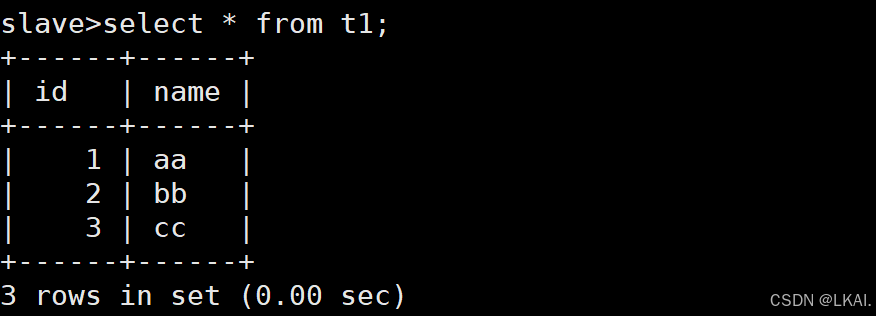
select * from t1;
主从复制原理
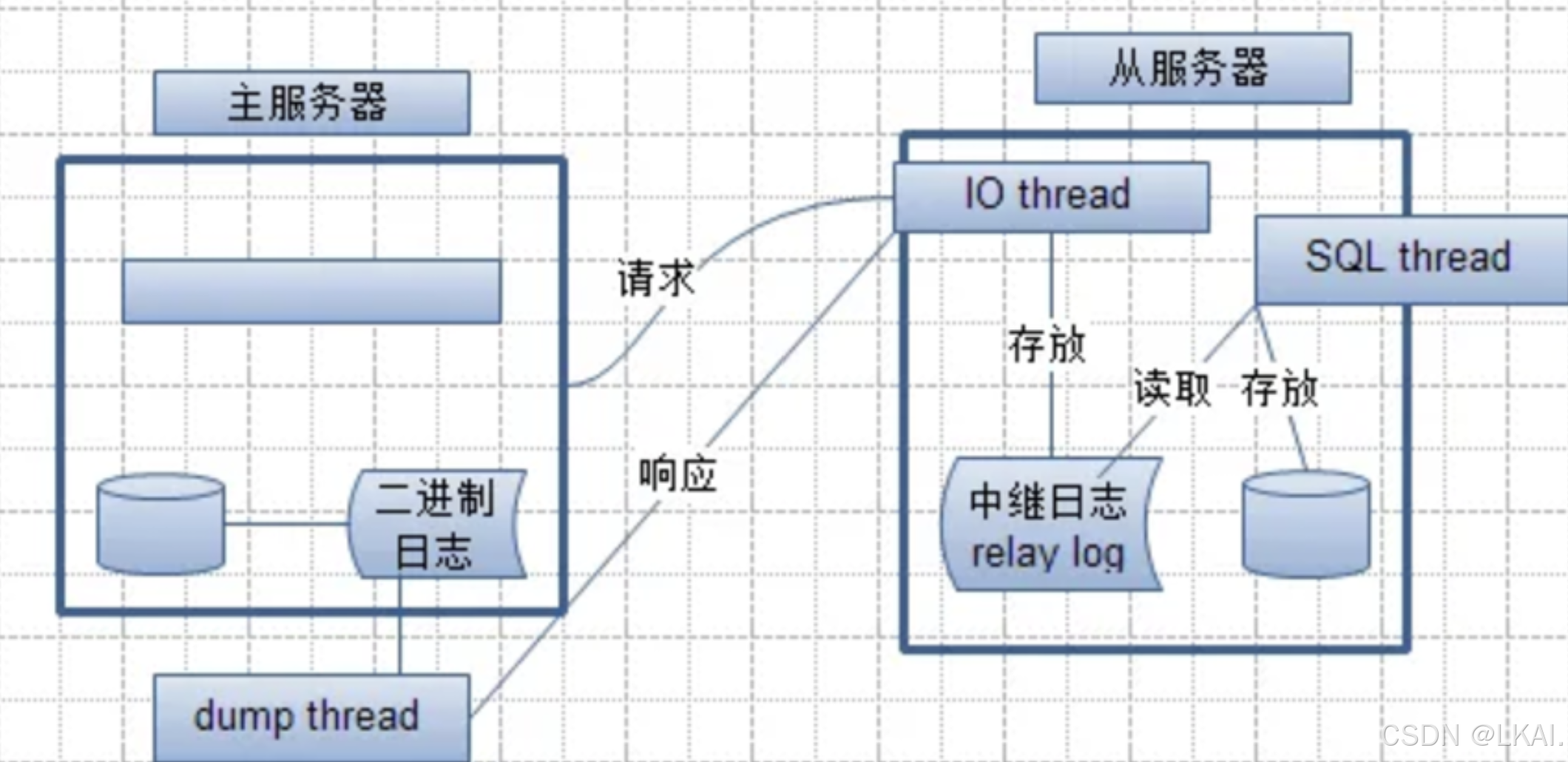
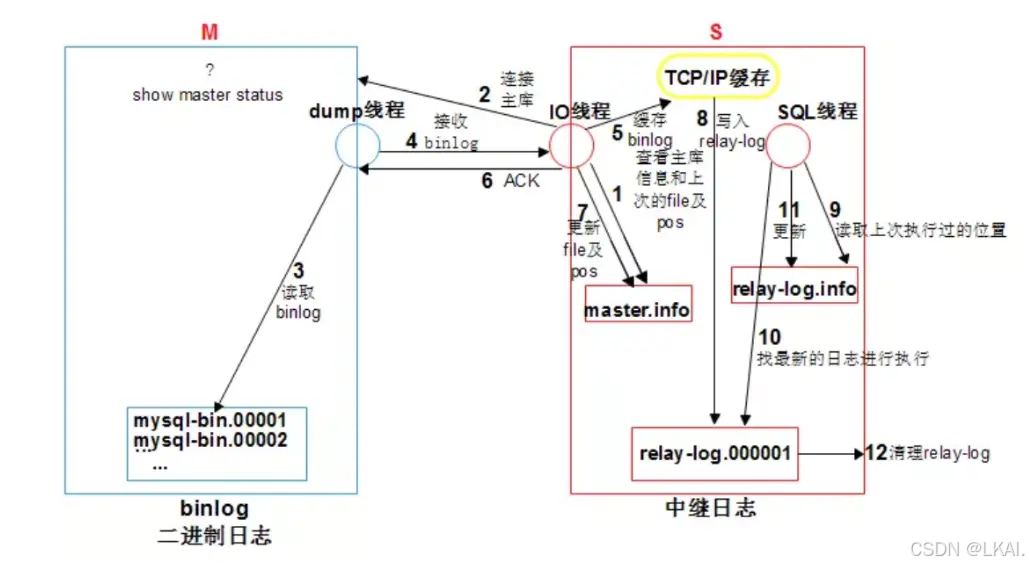
- 主从复制中涉及的文件
Master库:
binlog 二进制日志
Slave库:
relaylog 中继日志
master.info 主库信息文件(主从建立联系)
relaylog.info relaylog应用的信息(存储从服务器日志执行的进度,执行过的不再执行)
日志存储在以下位置:
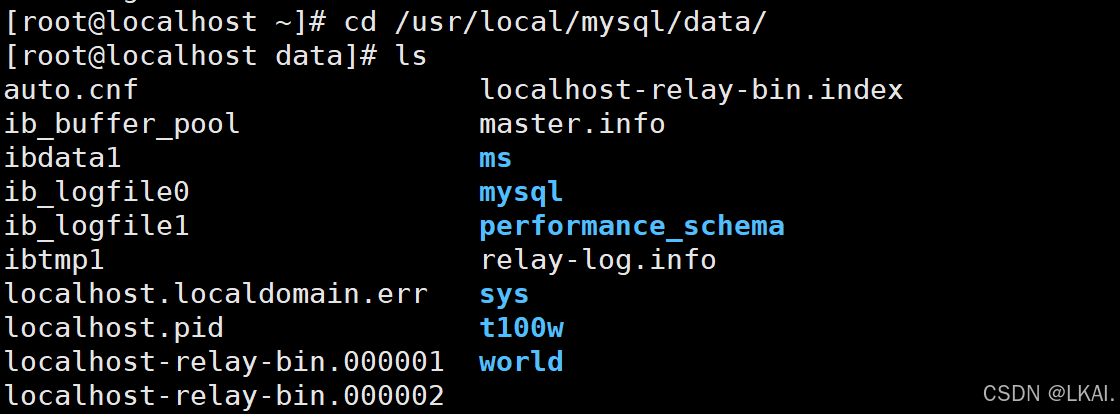
- 主从复制中涉及的线程
Master库:
Binlog_Dump Thread : DUMP_T(检测主主服务器有没有数据变化,就是二进制有没有变化,有变化就会主动通知io线程)
Slave库:
SLAVE_IO_THREAD : IO_T
SLAVE_SQL_THREAD : SQL_T
- 主从复制工作(过程)原理
1.从库执行change master to 命令(主库的连接信息+复制的起点)
2.从库会将以上信息,记录到master.info文件(系统重启便于下次重连)
3.从库执行 start slave 命令,立即开启IO_T和SQL_T
4.从库IO_T读取master.info文件中的信息,获取到IP、PORT、User、Pass、binlog的位置信息(联系主库)
5.从库IO_T请求连接主库,主库专门提供一个DUMP_T,负责和IO_T交互
6.IO_T根据binlog的位置信息(mysql-bin.000004 , 444),请求主库新的binlog
7.主库通过DUMP_T将最新的binlog,通过网络TP给从库的IO_T
8. IO_T接收到新的binlog日志,存储到TCP/IP缓存,立即返回ACK给主库,并更新master.info
9.IO_T将TCP/IP缓存中数据,转储到磁盘relaylog中
10. SQL_T读取relay.info中的信息,获取到上次已经应用过的relaylog的位置信息
11.SQL_T会按照上次的位置点回放最新的relaylog,再次更新relay.info信息
12.从库会自动purge应用过relay进行定期清理
补充说明:
一旦主从复制构建成功,主库当中发生了新的变化,都会通过dump_T发送信号给IO_T,增强了主从复制的实时性
- 主从复制监控
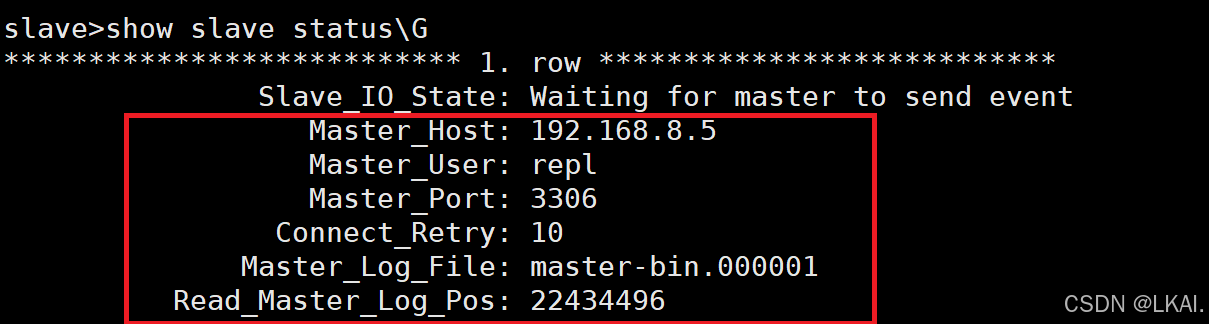
show slave status\G
主库有关的信息(master.info):
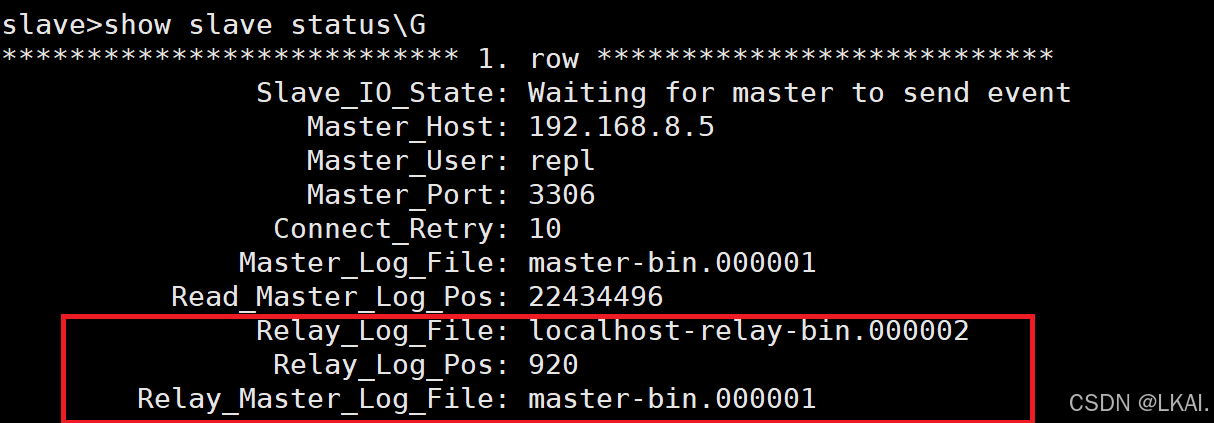
从库relay应用信息有关的(relay.info)::
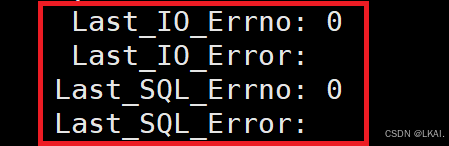
从库线程运行状态(排错):

过滤复制有关的信息:
从库延时同步主库的时间(秒):
![]()
测试
Master:
drop database t100w;

create database t100w;

use t100w;
source t100w.sql
Slave:
show slave status\G
![]()
延迟一秒,但是如果服务器性能好,延迟可能也会显示0
延时从库(延时误操作):
show slave status\G

SQL_Delay: 0 (秒)及时还原数据(例如master误删除数据,从服务器经过7200秒才会同步)
GTID复制有关的状态信息:

主从复制故障
- IO线程故障
(1)连接主库: connecting
网络、连接信息错误或变更了,防火墙,连接数上限
排查思路:
使用复制用户手工登录
测试是否用户名、密码、IP出错
解决:
Slave
1. stop slave ——停止同步
2. reset slave all; ——清空master.info
3. change master to ... ——重新查看master,再次连接master
4. start slave ——再次开启同步
(2)请求Binlog
binlog 没开
binlog 损坏,不存在
解决:
主库开启binlog
终极解决方案:
主库 reset master 处理
从库
stop slave ;
reset slave all;
CHANGE MASTER TO
MASTER_HOST='192.168.8.5',
MASTER_USER='repl',
MASTER_PASSWORD='123.com',
MASTER_PORT=3306,
MASTER_LOG_FILE='master-bin.000001',
MASTER_LOG_POS=154,
MASTER_CONNECT_RETRY=10;
start slave;
(3)存储binlog到relaylog
- SQL线程故障
relay-log损坏
回放relaylog
研究一条SQL语句为什么执行失败?
insert delete update ---> t1 表 不存在
create table t1 ---> t1 已存在
约束冲突(主键,唯一键,非空…)
合理处理方法:
把握一个原则,一切以主库为准进行解决
如果出现问题,尽量进行反操作
最直接稳妥办法,重新构建主从
暴力的解决方法:
方法一:
stop slave;
set global sql_slave_skip_counter = 1;
start slave;
#将同步指针向下移动一个,如果多次不同步,可以重复操作。
start slave;
方法二:
/etc/my.cnf
slave-skip-errors = 1032,1062,1007
常见错误代码:
1007:对象已存在
1032:无法执行DML,可能对象不存在
1062:主键冲突或约束冲突
但是,以上操作有时是有风险的,最安全的做法就是重新构建主从。把握一个原则,一切以主库为主(都在主库上改,除非有读写分离)
为了避免SQL线程故障
(1)从库只读
read_only
super_read_only
(2)使用读写分离中间件
amoeba(淘宝)
atlas (奇虎360)
mycat
ProxySQL
MaxScale
主从延时监控及原因
- 主库方面原因
(1)binlog写入不及时
sync_binlog=1
(2)默认情况下dump_t 是串行传输binlog
在并发事务量大时或者大事务,由于dump_t是串型工作的,导致传送日志较慢
如何解决问题?
必须GTID,使用Group commit方式,可以支持DUMP_T并行(同时打开多个DUMP_T)
(3)主库极其繁忙
慢语句
锁等待
从库个数
网络延时
- 从库方面原因
(1)传统复制(Classic)中
如果主库并发事务量很大,或者出现大事务
由于从库是单SQL线程,导致不管传的日志有多少,只能一次执行一个事务
5.6 版本有了GTID,可以实现多SQL线程,但是只能基于不同库的事务进行并发回放.(database)
5.7 版本中有了增强的GTID,增加了seq_no,增加了新型的并发SQL线程模式(logical_clock)MTS技术(多版本并发技术)
(2)主从硬件差异太大
(3)主从的参数配置
(4)从库和主库的索引不一致
(5)版本有差
- 主从延时的监控
![]()
主库方面原因的监控
主库:
show master status;

从库:
show slave status\G
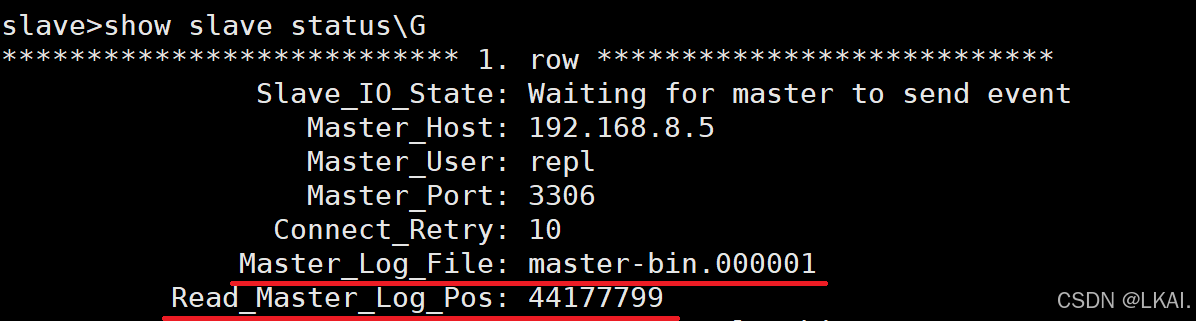
从库方面原因监控
拿了多少:
Master_Log_File: mysql-bin.000001
Read_Master_Log_Pos: 691688
执行了多少:
Relay_Log_File: db01-relay-bin.000004
Relay_Log_Pos: 690635
Exec_Master_Log_Pos: 691000
Relay_Log_Space: 690635


















 322
322

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









