






错误日志
- 作用
排查MySQL运行过程的故障
- 错误日志默认存放位置
错误日志默认名为:主机名.err
cd /usr/local/mysql/data/

- 设置错误日志存放位置
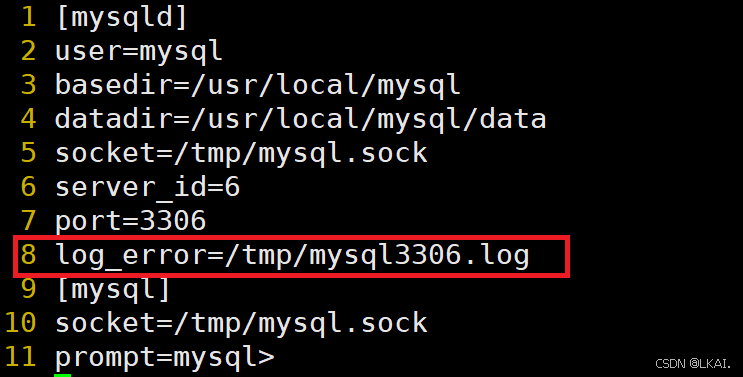
vim /etc/my.cnf
添加:
log_error=/tmp/mysql3306.log
重启MySQL
systemctl restart mysqld
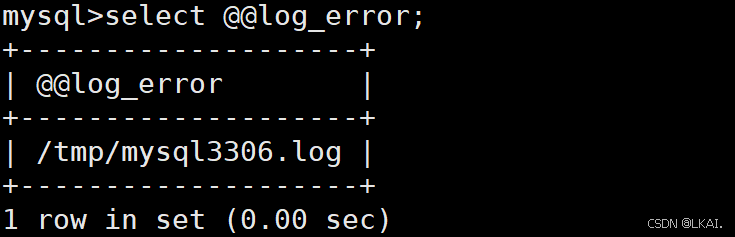
查看错误日志存放路径
select @@log_error;
二进制日志(binlog)
- 作用
主从要依赖二进制日志
数据恢复时需要依赖于二进制日志
- 配置二进制日志
默认未开启
查看当前二进制日志状态
show master status;

开启二进制日志
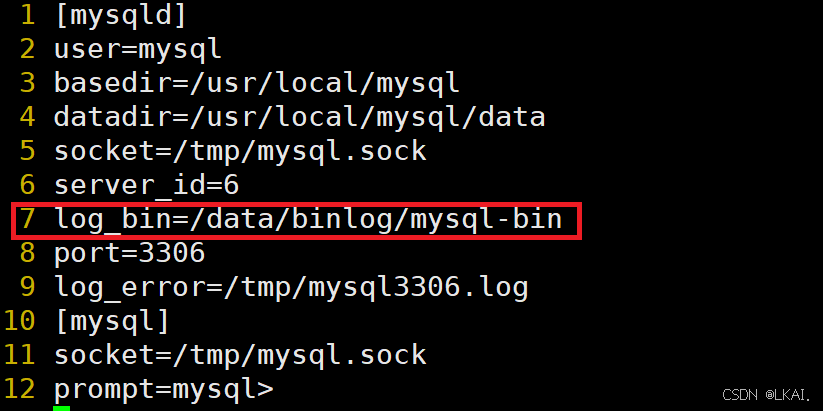
vim /etc/my.cnf
添加:
log_bin=/data/binlog/mysql-bin
创建目录并授权
mkdir -p /data/binlog
chown -R mysql.mysql /data
重启MySQL
systemctl restart mysqld
查看二进制日志文件
cd /data/binlog/

查看当前二进制日志状态
show master status;

- 二进制日志记录的内容
1)概括
记录的数据库所有变更类的操作日志
DDL: create drop alter
DCL: grant revoke
DML: insert update delete
2)DDL 和 DCL
以语句的方式原模原样的记录
3)DML
他记录的已提交的事务
DML记录格式(statement,row,mixed),通过binlog_format=row参数控制
说明:
statement:SBR,语句模式记录日志,做什么命令,记录什么命令
row:RBR,行模式,数据行的变化(默认为行级)
mixed:MBR,混合模式
SBR和RBR什么区别?怎么选择?
SBR:可读性较强,对于范围操作日志量少,但是可能会出现记录不准确的情况(语句中出现now())
RBR:可读性较弱,对于范围操作日志大,不会出现记录错误。高可用环境中的新特性要依赖于RBR
为什么用RBR?
公司对数据的严谨性要求较高,也用到了新型的架构,所以选择RBR
- 二进制日志记录单元
1)event事件
DDL:对于DDL语句是每一个语句就是一个事件
create database event; 事件1
DML:一个事务包含了多个语句
begin; 事件1
a 事件2
b 事件3
commit; 事件4
2)event事件的开始和结束号码
作用:
方便我们从日志中截取我们想要的日志事件(快速还原数据库)
- 二进制日志的管理
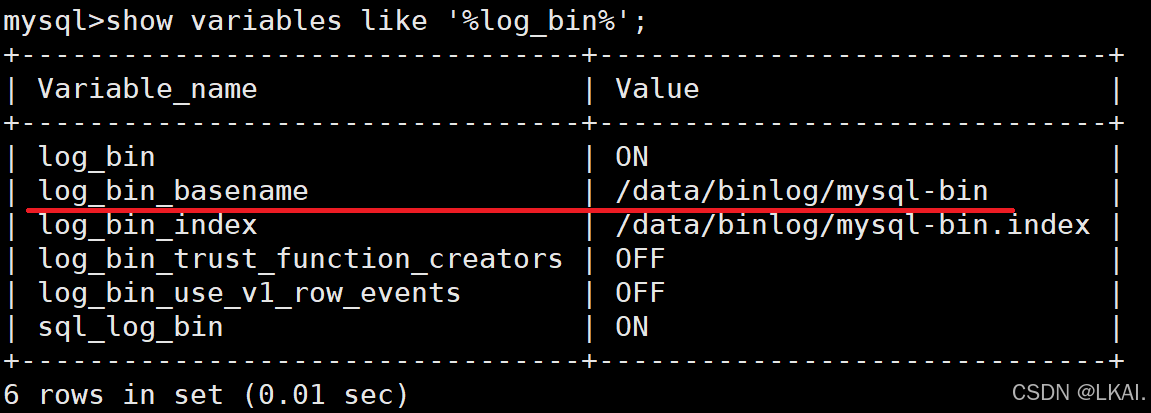
1)查看二进制日志位置
show variables like '%log_bin%';
2)查看所有存在的二进制日志
show binary logs;
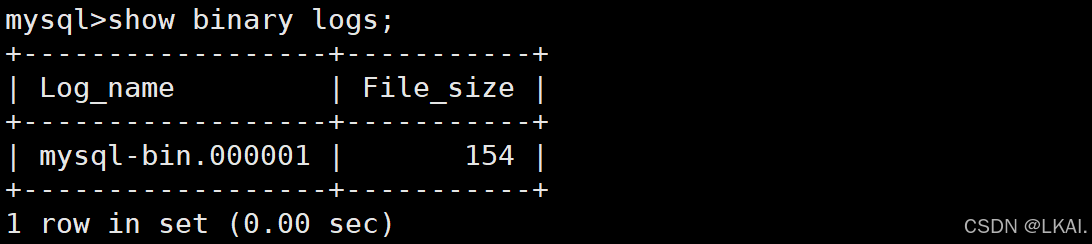
刷新二进制日志,产生新的二进制日志
flush logs;
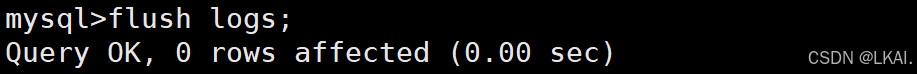
查看当前使用的二进制日志
show master status;

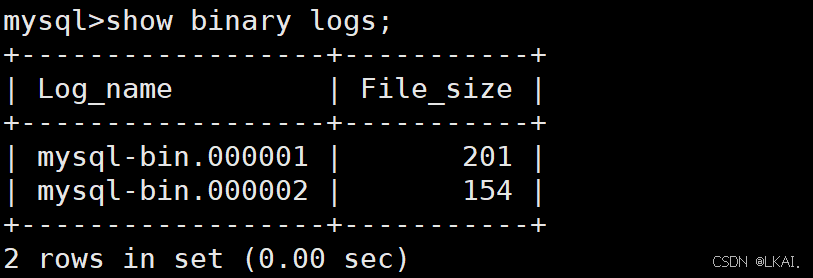
查看所有存在的二进制日志
show binary logs;
3)清空二进制日志
reset master;

查看当前使用的二进制日志
show master status;

4)查看二进制日志事件
create database binlog charset utf8mb4;
use binlog
create table t1(id int);
insert into t1 values(1);
show master status;

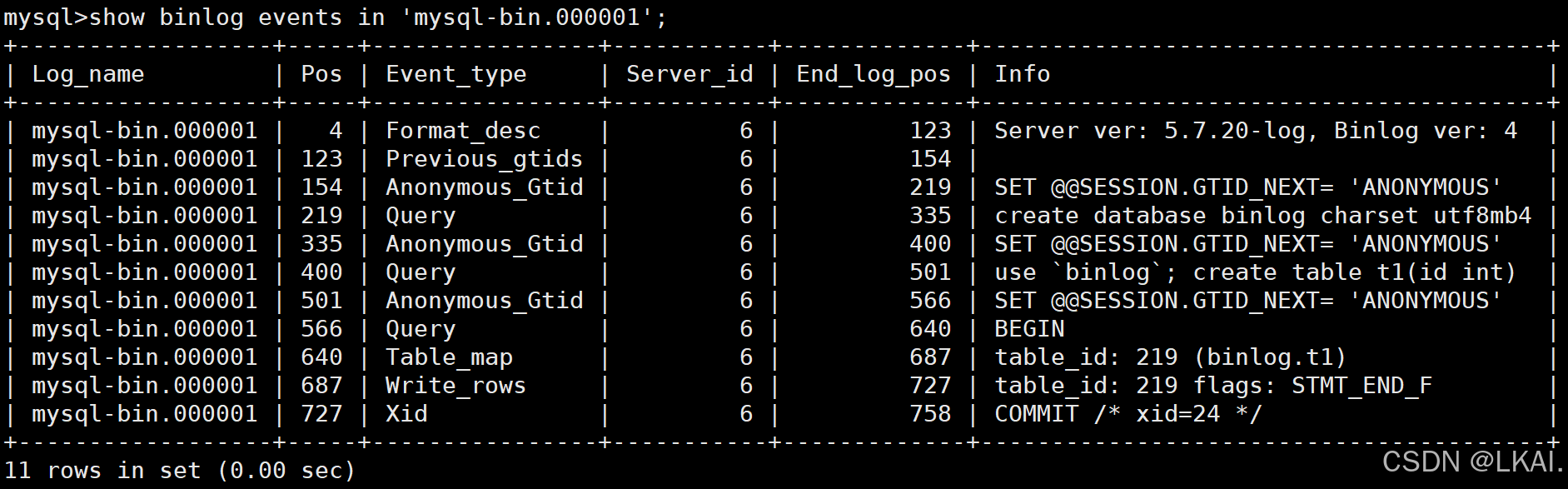
查看日志中详细事件
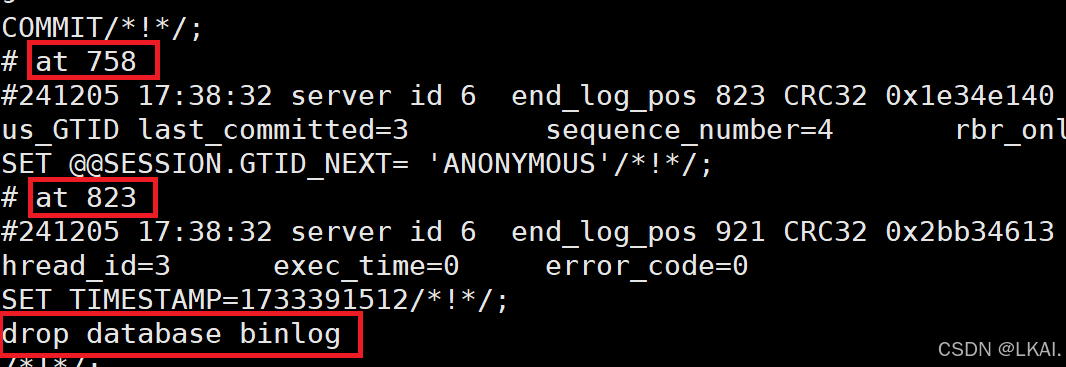
show binlog events in 'mysql-bin.000001';
模拟数据库损坏
drop database binlog;
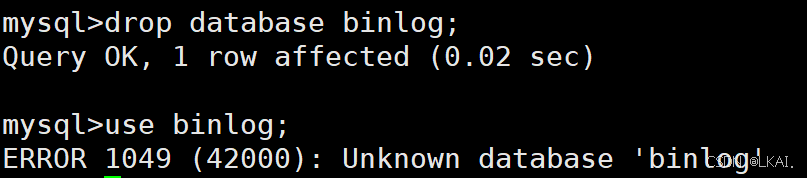
5)查看二进制日志内容
看语句级日志,不能看行数据
cd /data/binlog/
mysqlbinlog mysql-bin.000001
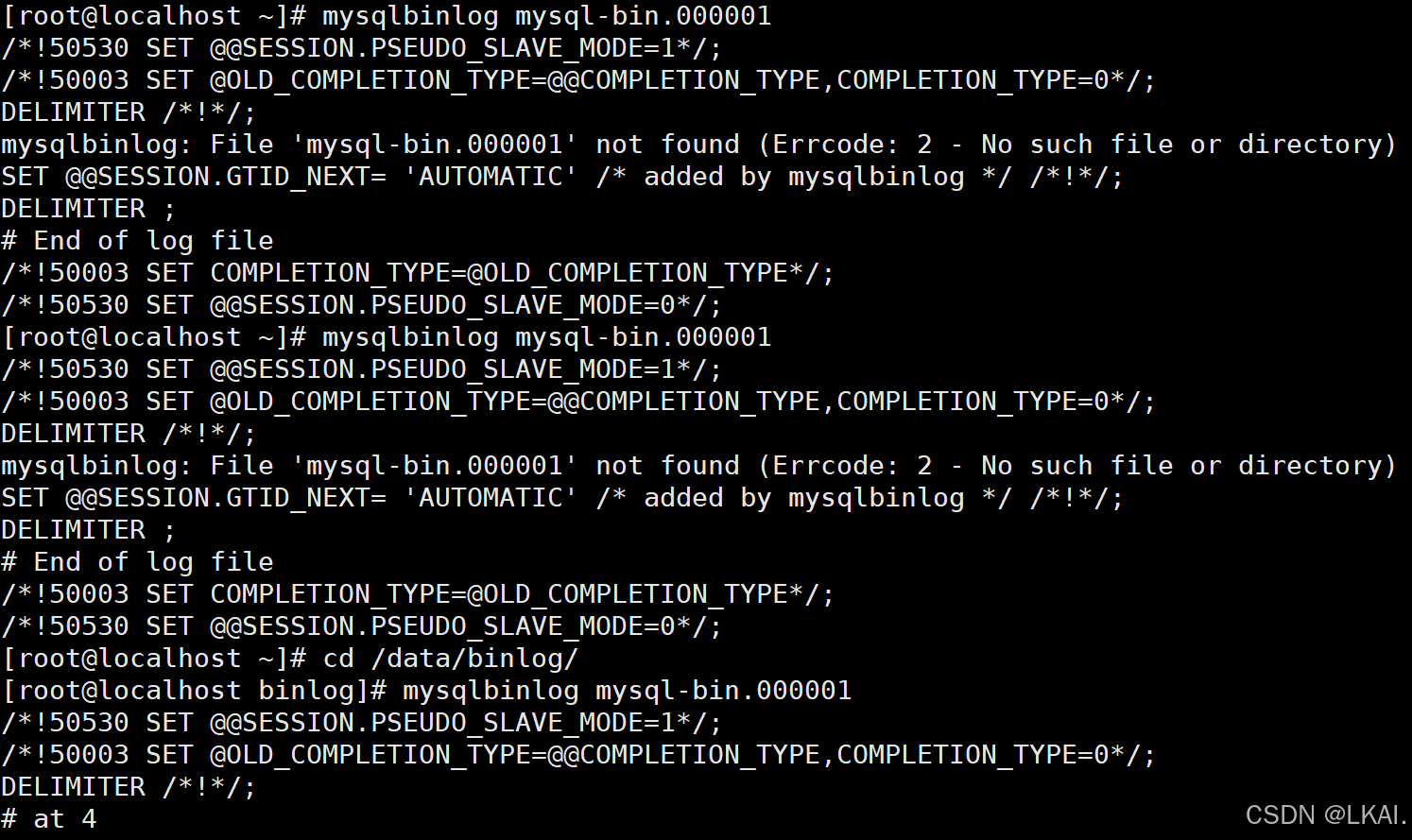
使用解码方式,可看行数据
mysqlbinlog --base64-output=decode-rows -vvv mysql-bin.000001
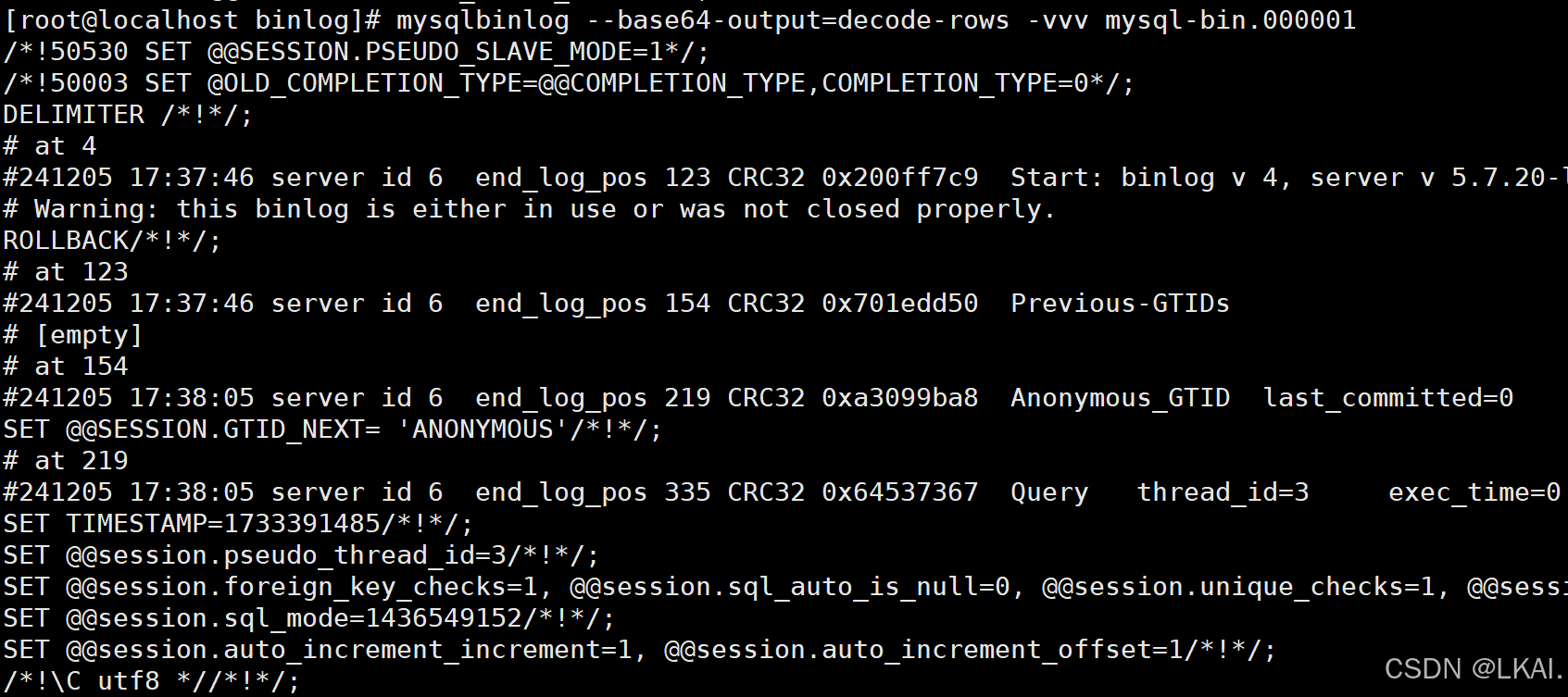
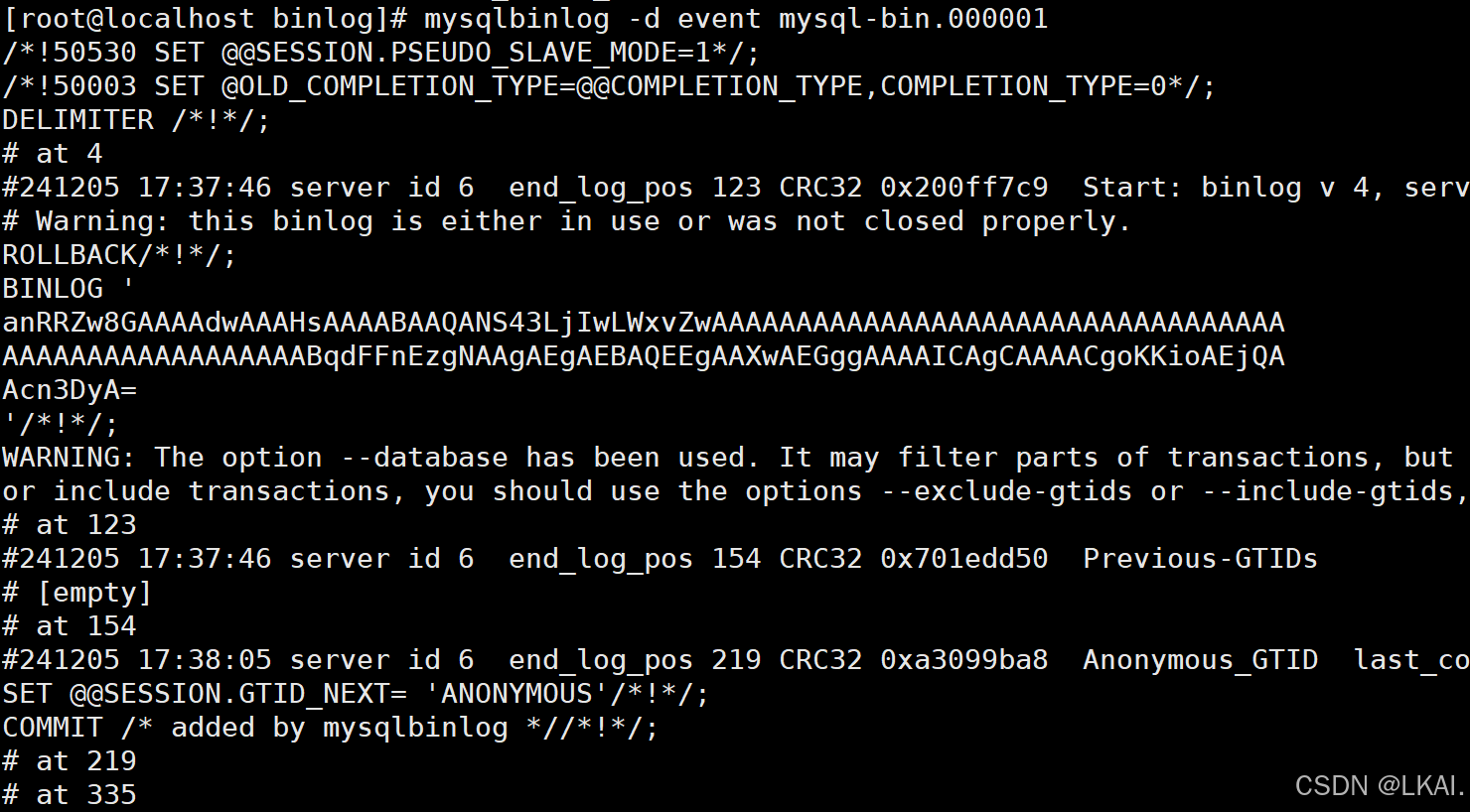
摘要显示事件号码
mysqlbinlog -d event mysql-bin.000001
6)截取二进制日志还原
mysqlbinlog mysql-bin.000001

mysqlbinlog --start-position=219 --stop-position=758 mysql-bin.000001 > /tmp/a.sql

ls -lh /tmp/a.sql

关闭日志
set sql_log_bin=0;

还原数据
source /tmp/a.sql

开启日志
set sql_log_bin=1;

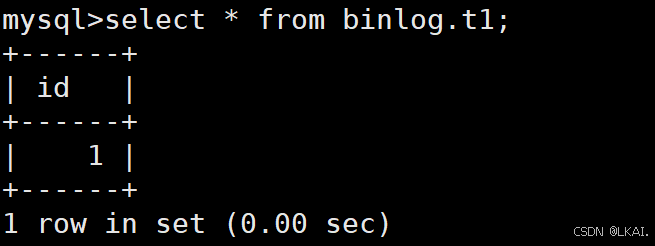
查数据看是否恢复
select * from binlog.t1;
7)通过binlog恢复数据(不使用reset master,再做一遍模拟删除)
创建数据
create database hehe charset utf8mb4;
use hehe;
create table t1(id int);
insert into t1 values(1);
模拟数据库损坏
drop database hehe;
查看日志存放文件
show master status;

查看事件
show binlog events in 'mysql-bin.000001';
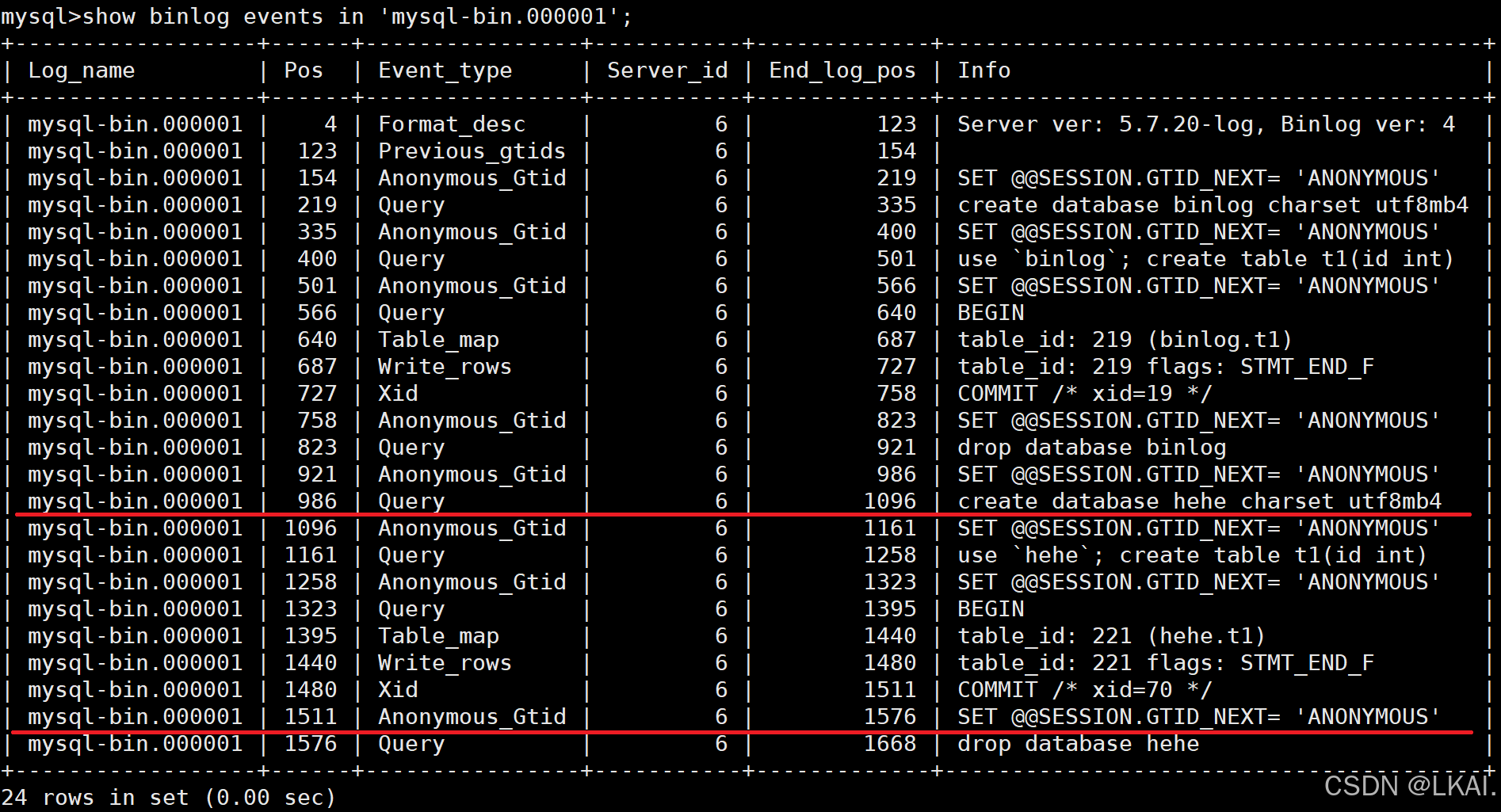
找到恢复到数据的Pos号
cd /data/binlog
mysqlbinlog --start-position=986 --stop-position=1511 /data/binlog/mysql-bin.000001 > /tmp/bin.sql
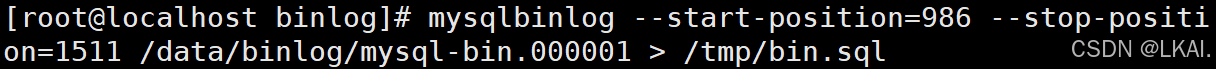
临时关闭恢复时产生的新日志
set sql_log_bin=0;
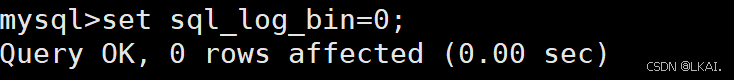
恢复数据
source /tmp/bin.sql

开启日志
set sql_log_bin=1;

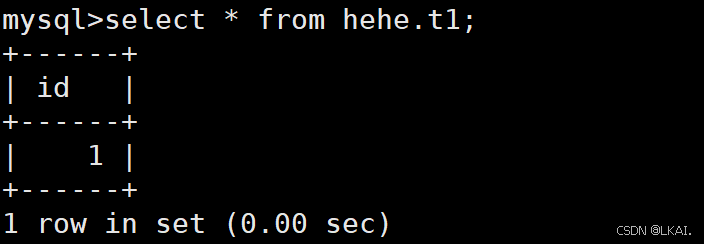
查数据看是否恢复
select * from hehe.t1;
- binlog的gtid记录模式的管理
1)GTID介绍
对于binlog中的每一个事务,都会生成一个GTID号码
DDL 、DCL:一个event就是一个事务,就会有一个GTID号
DML:begin到commit是一个事务,就是一个GTID号
2)GTID的组成
server_uuid:TID
TID:是一个自增长的数据,从1开始
查看server_uuid
cat /usr/local/mysql/data/auto.cnf

3)GTID的幂等性
如果拿有GTID的日志去恢复时,检查当前系统中是否有相同GTID号,有相同的就自动跳过,会影响到binlog恢复和主从复制
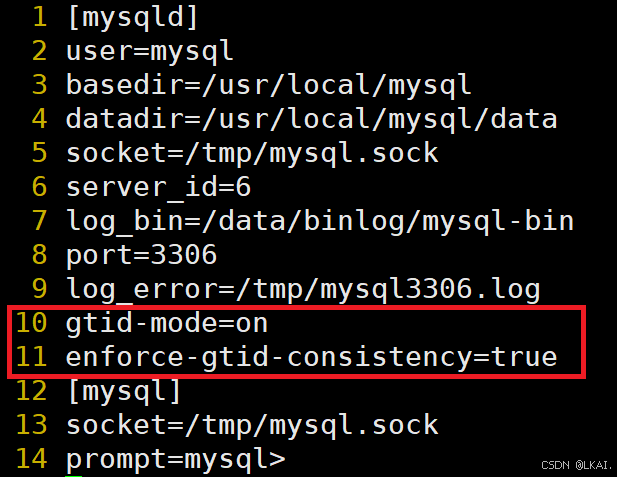
4)GTID的开启
vim /etc/my.cnf
添加:
gtid-mode=on
enforce-gtid-consistency=true
重启MySQL
systemctl restart mysqld
5)查看GTID信息
create database gtid charset utf8mb4;
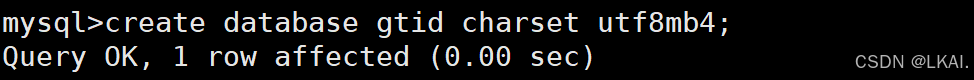
show master status;

use gtid;
create table t1(id int);

show master status;

insert into t1 values(1);

show master status;

drop database gtid;

show binlog events in 'mysql-bin.000002';
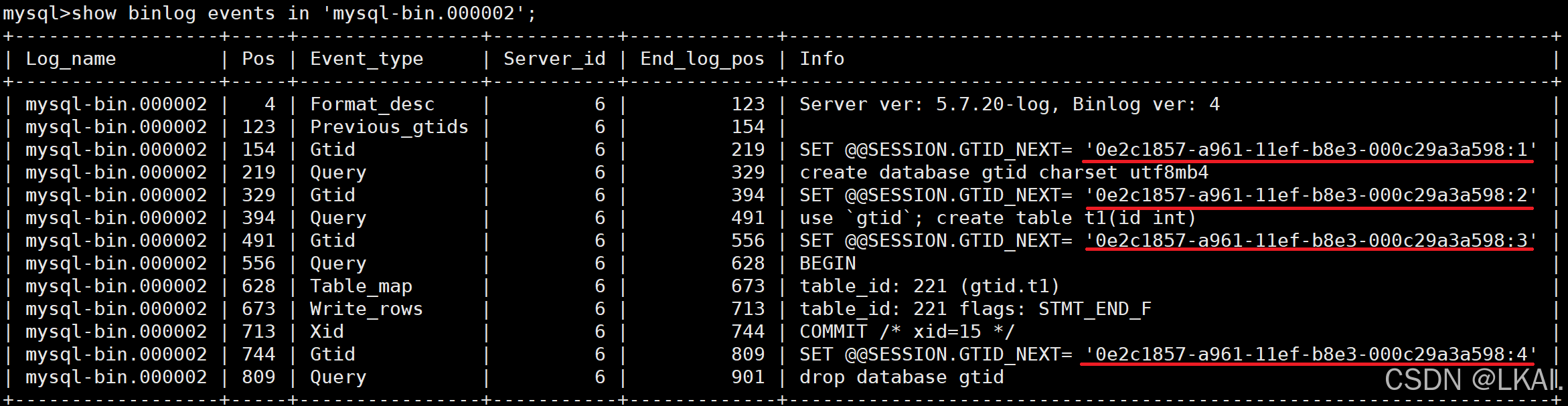
6)基于GTID,binlog恢复
截取日志
cd /data/binlog/
mysqlbinlog --skip-gtids --include-gtids='0e2c1857-a961-11ef-b8e3-000c29a3a598:1-3' mysql-bin.000002 > /tmp/gtid.sql

--skip-gtids 作用:在导出时,忽略原有的gtid信息,恢复时生成最新的gtid信息
临时关闭恢复时产生的新日志
set sql_log_bin=0;

恢复数据
source /tmp/gtid.sql
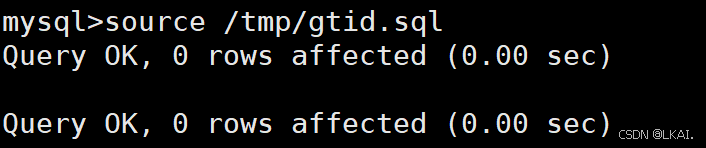
开启日志
set sql_log_bin=1;

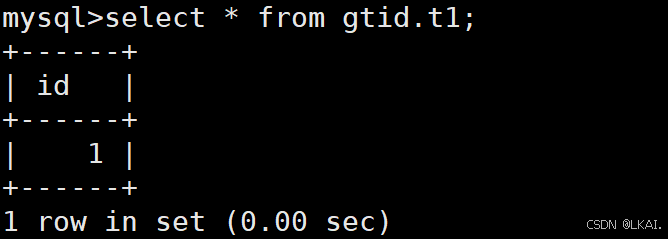
查数据看是否恢复
select * from gtid.t1;
7)GTID相关的参数
--skip-gtids 跳过gtids
--include-gtids='e2e9b01e-9687-11eb-b577-000c29b0384b:6','e2e9b01e-9687-11eb-b577-000c29b0384b:8' 截取的不是连续的值
--exclude-gtids='e2e9b01e-9687-11eb-b577-000c29b0384b:6','e2e9b01e-9687-11eb-b577-000c29b0384b:8' 排除的
慢日志(slow-log)
- 作用
记录运行较慢的语句,优化过程中常用的工具日志
然后再desc分析是否创建索
- 配置慢日志
查看慢日志状态
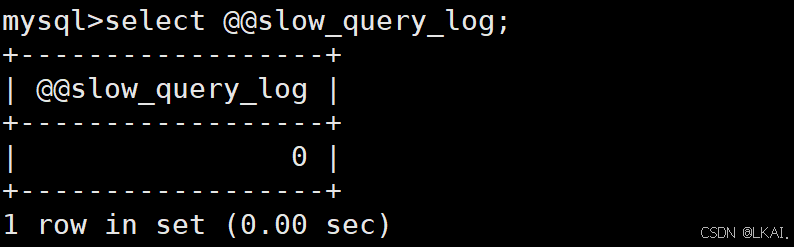
show variables like '%slow_query_log%';
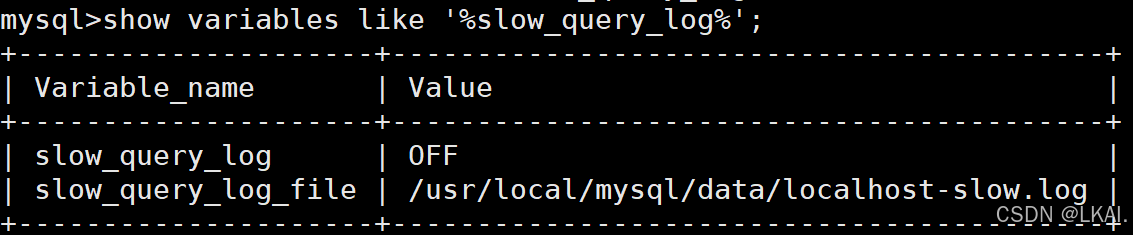
select @@slow_query_log;
开启慢日志
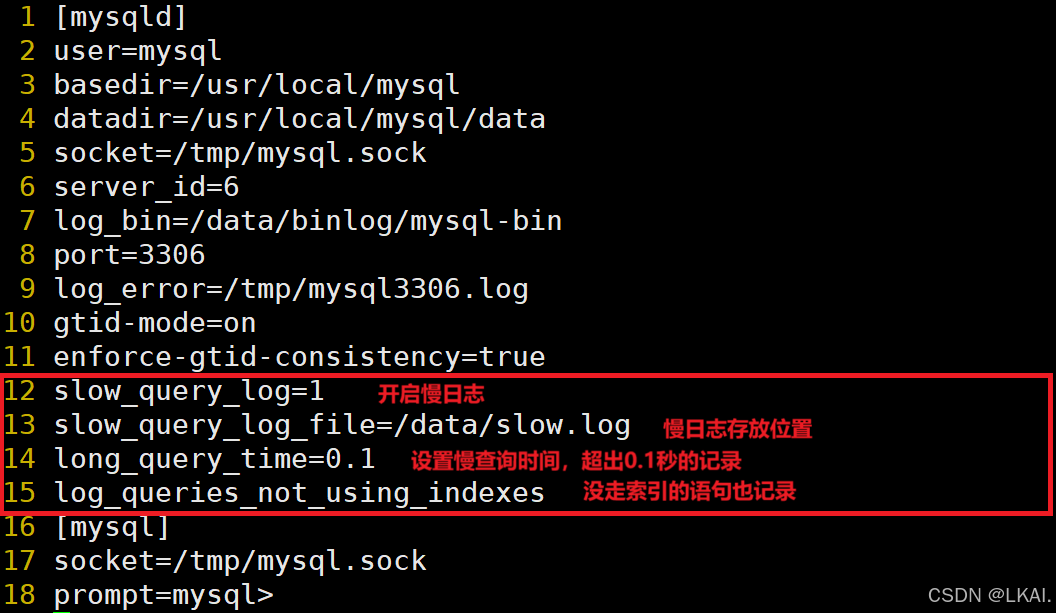
vim /etc/my.cnf
添加:
slow_query_log=1
slow_query_log_file=/data/slow.log
long_query_time=0.1
log_queries_not_using_indexes
重启MySQL
systemctl restart mysqld
- 模拟慢查询
创建数据库并导入t100w表
create database test;
use test;
source /root/t100w.sql
清空导入表的慢日志
> /data/slow.log
![]()
执行查询语句
select * from t100w limit 10000;
select * from t100w where id=1568;
select * from t100w where num=1100;
select * from t100w where num=102000 order by k1;
select * from t100w where k2='MN89';
查看慢日志文件
cd /data/

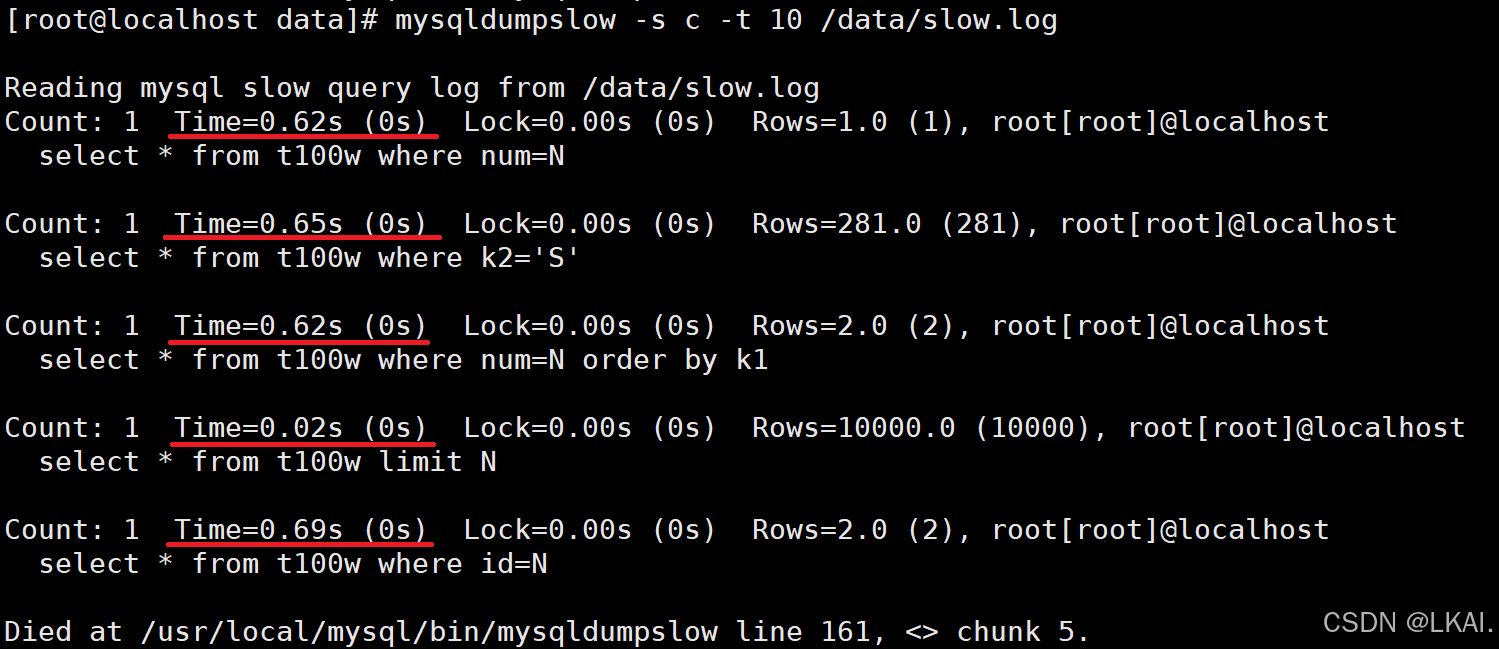
分析慢日志
mysqldumpslow -s c -t 10 /data/slow.log
创建索引
use test;
alter table t100w add index idx_k2(k2);

select * from t100w where k2='MN89';
创建索引后查询速度变快
第三方工具分析日志
下载地址:Software Downloads - Percona
将percona-toolkit-3.3.0-1.el7.x86_64包拖入/root目录
rpm -ivh percona-toolkit-3.3.0-1.el7.x86_64.rpm
分析日志
pt-query-digest /data/slow.log
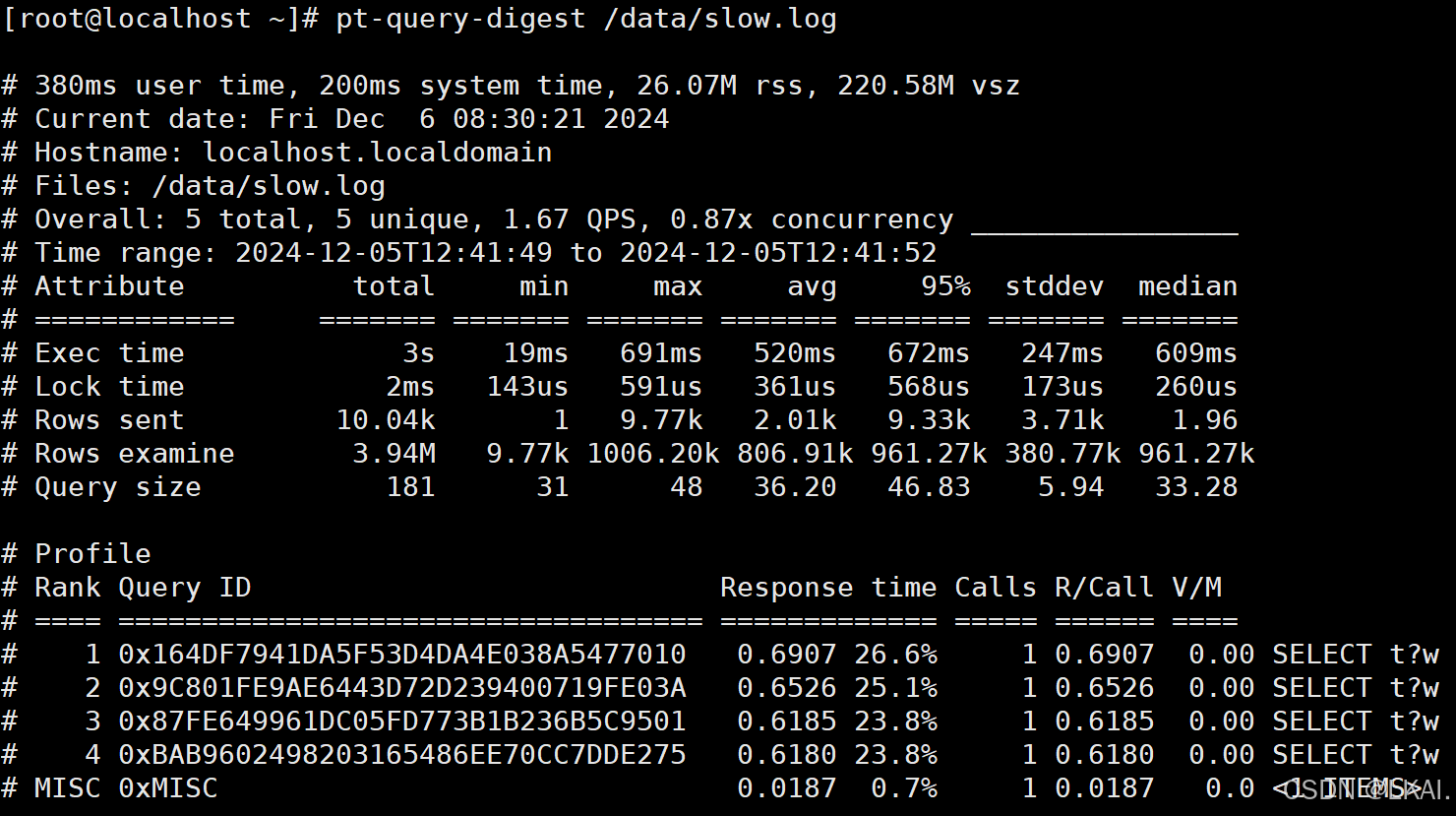
第一部分:总体统计结果
Overall:总共有多少条查询
Time range:查询执行的时间范围
unique:唯一查询数量,即对查询条件进行参数化以后,总共有多少个不同的查询
total:总计 min:最小 max:最大 avg:平均
95%:把所有值从小到大排列,位置位于95%的那个数,这个数一般最具有参考价值
median:中位数,把所有值从小到大排列,位置位于中间那个数
第二部分:查询分组统计结果
Rank:所有语句的排名,默认按查询时间降序排列,通过--order-by指定
Query ID:语句的ID,(去掉多余空格和文本字符,计算hash值)
Response:总的响应时间
time:该查询在本次分析中总的时间占比
calls:执行次数,即本次分析总共有多少条这种类型的查询语句
R/Call:平均每次执行的响应时间
V/M:响应时间Variance-to-mean的比率
Item:查询对象
第三部分:每一种查询的详细统计结果
由下面查询的详细统计结果,最上面的表格列出了执行次数、最大、最小、平均、95%等各项目的统计。
ID:查询的ID号,和上图的Query ID对应
Databases:数据库名
Users:各个用户执行的次数(占比)
Query_time distribution :查询时间分布, 长短体现区间占比,本例中1s-10s之间查询数量是10s以上的两倍。
Tables:查询中涉及到的表
Explain:SQL语句
常见用法:
分析半个小时内慢查询:
pt-query-digest --since 1800s slow.log
分析一段时间范围内的慢查询:
pt-query-digest --since '2023-03-16 15:03:00' --until '2023-03-16 15:06:00' slow.log
显示所有分析的查询命令如下
pt-query-digest --limit 100% slow.log
其中,“--limit”参数默认是“95%:20”,表示显示95%的最差的查询,或者20个最差的查询。
此外,也可以用这个工具来分析二进志日志,以查看我们日常的修改语句是如何分布的,首先需要把二进志日志转换为文
本格式。
mysqlbinlog mysql-bin.000005 > /tmp/mysql_bin_000005.log
pt-query-digest --type binlog /tmp/mysql_bin_000005.log
Anemometer基于pt-query-digest将MySQL慢查询可视化



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









