






王卓数据结构与算法之栈和队列
栈和队列
栈和队列与线性表的关系
总的来说,栈和队列是操作受限的线性表 下面两个实例可以帮助你快速了解他们各自的特点




基础知识点
栈的定义和特点
后进后出 仅仅在尾部进行插入和删除操作


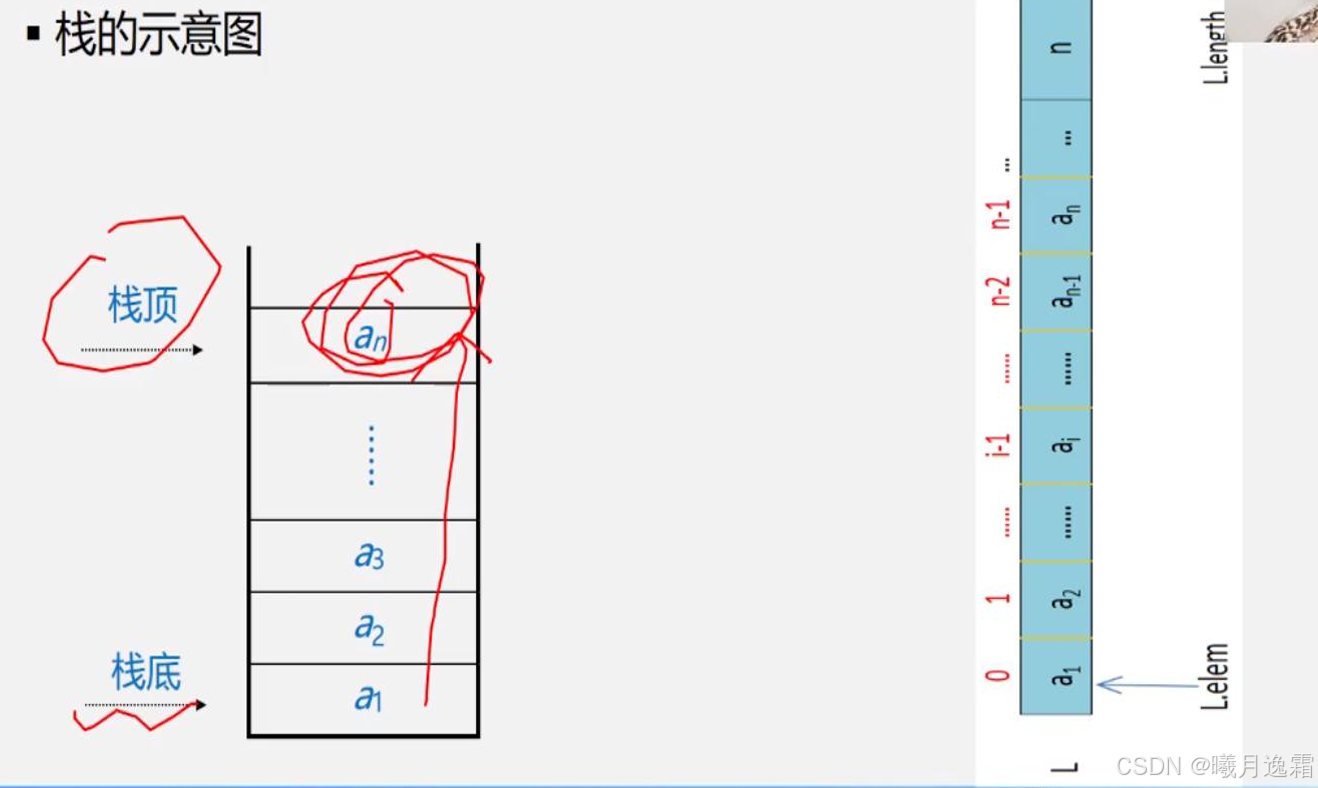
队列的定义和特点

案例
`
这就是非常典型的栈的问题 根据进制转换的方法 结果是从下往上取的 而我们把这些数字按顺序放进一个数组里面,再把它竖起来,在输出结果时,就是非常明显的先入后出的特点 这样我们就可以用栈来实现 再合适不过了
栈
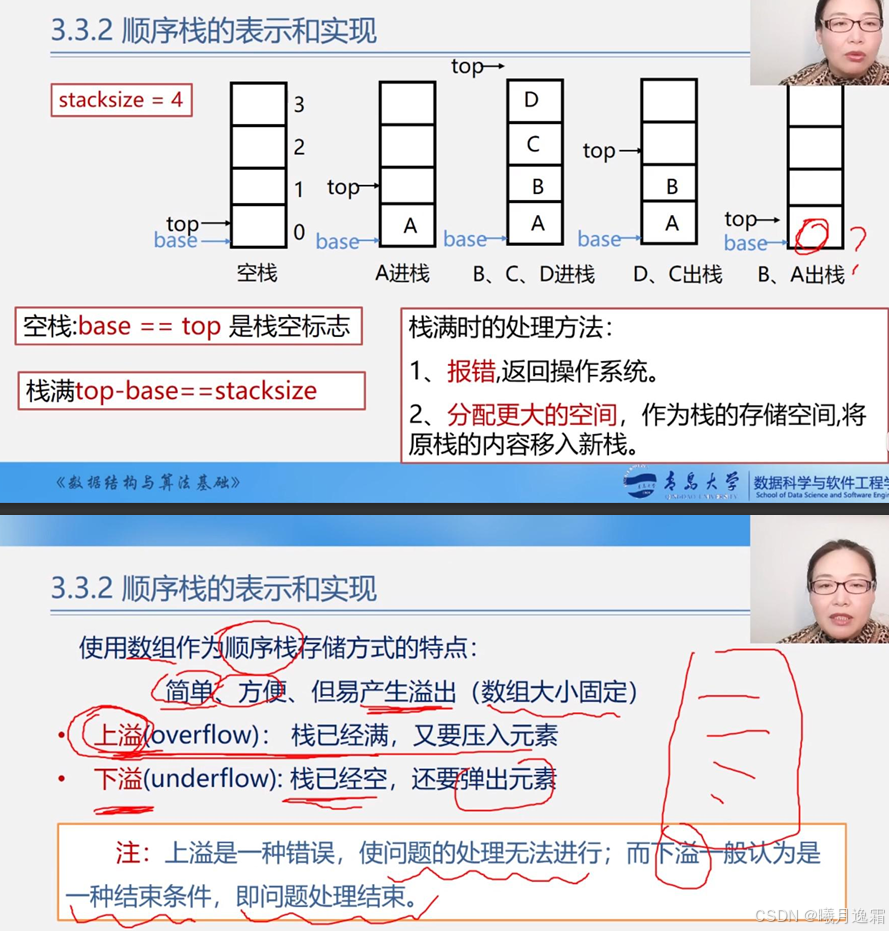
顺序栈的表示和实现
注意如果看过别的老师的视频 这里对于top指针有两种设置方式 均可达到效果 (因为入栈的时候是先将top指针向上移动一位,然后将想要压入栈的元素放进现在top指针所指的位置)一种是王卓老师将top指向真正栈顶元素之上 一种是懒猫老师直接将top指针设置在-1的位置上 这两种方式都很好不必纠结 代码会在后文展示
顺序栈的代码实现(先做在看!)
- 这些代码需要自己手敲反复理解
- 下面分别是顺序栈的代码实现(C++和C)
- 对于没有学过类与对象的同学直接看后面的C语言版本就好
- 虽然代码有些长但还是希望大家全部掌握
#include <iostream>
using namespace std;
//用C++的方式实现顺序栈(以存储整型数据为例
const int MAXSIZE=100;
class stack{
private:
int *data;//因为弹出栈和入栈时需要存储数据,所以需要一个指针来存储数据
int top;//栈顶指针
int size;
public:
stack();
stack(int size);
~stack();
//内联函数
void push( int s)
{
if (isFull()){
throw full();//抛出异常
}else{
top=top+1;
data[top]=s;
}
// else{
// cout<<"FULL";为了遵循子函数功能尽量单一的原则,比如这个函数的功能只是压入栈而不是压入栈并输出
// 所以我们最好不要这么写,可以采用异常捕获
//所有的输出应该在特有的dispaly函数,main函数,input函数中体现,便于类的重用
}
int pop(){
if (isEmpty())//当我们写好了判断是否为空的函数后,最好直接调用
{
throw empty();//抛出异常
}else{
return data[top--];//先弹出栈顶的值,然后再将栈顶指针下移
}
}
bool isFull()//bool类型的函数名要用is开头
{
if (top==size-1)
{
return true;
}else{
return false;
}
}
bool isEmpty()
{
if (top==-1)
{
return true;
} else{
return false;
}
}
int getTop()
{
if (!isEmpty())
{
return data[top];
}
}
class full{};//定义内部异常类
class empty{};
};
stack::stack(){
size=MAXSIZE;
top=-1;
data= new int[MAXSIZE];//没有参数默认最大空间
}//无参构造函数
stack::stack(int s){
size=s;
top=-1;
data=new int[size];//根据传入的参数开辟空间
}//有参构造函数
stack::~stack(){
delete[]data;//new函数开辟的空间需要delete释放
}//构析函数
int main() {
stack A(2);
try//因为这些语句都有可能抛出异常,所以需要用try包裹在里面
{
A.push(1);
A.push(2);
A.push(3);
}
//当有full这样的异常出现时,会跳到catch语句块中输出错误信息
catch (stack::full){
cout<<"full"<<endl;//错误信息
}
try {
cout<<A.pop()<<endl;//弹出2
cout<<A.pop()<<endl;//弹出1
cout<<A.pop()<<endl;//因为栈中已经为空,所以弹出空栈会抛出异常直接跳出try结构,被catch语句捕获并输出错误信息empyt
}
catch (stack::empty){
cout<<"empty"<<endl;
}
//这样就很好的解决了栈溢出和栈空问题,避免在pop和push函数中输出,保证了类的可重用性
//这里使用异常捕获保证类的重用性,是因为如果我们使用if-else语句简单的在栈空时用printf函数
// 输出empyt时,当第二次我们使用时程序需要输出其他信息,就会需要我们进行修改或者直接导致我们无法使用这个类了
//由于一次异常捕获只能找到一个异常,所以如果要捕获多个异常,需要嵌套使用try catch语句
//所以只有在必要时才使用异常捕获,否则尽量避免使用异常捕获,因为异常捕获会降低程序的性能,并且会让代码变得难懂
//能用if 语句代替异常捕获的就尽量用if语句
// cout<<A.isFull()<<endl;
// cout<<A.pop()<<endl;
// cout<<A.pop()<<endl;
// cout<<A.getTop()<<endl;
// cout<<A.isEmpty()<<endl;
return 0;
}
王卓老师(C)
//1.预编译部分
#include <stdio.h>
#include <stdlib.h>
//2.宏定义部分
#define bool char//因为C语言中不含布尔类型,我们自己定义一下
#define ture 1
#define false 0
#define MAXSIZE 50 //定义
typedef int Elemtype;//自定义栈中元素的数据类型
typedef struct Sqstack{
int top;//栈顶指针
Elemtype data[MAXSIZE];
}Sqstack;
bool initStack(Sqstack*s)
{
s->top=-1;//s指针不需要在函数内部开辟空间,因为它指向的是一个已经存在的 Sqstack 对象。
}
//判断栈是否为空
bool isempty(Sqstack s)
{
if(s.top == -1)
{
return ture;
} else{
return false;
}
}
//进栈
bool push(Sqstack*s,Elemtype data)//因为我们需要改变s的位置所以这里是指针,入栈还需要传入参数的值
{//首先我们需要判断栈是否为空
if(s->top ==MAXSIZE-1)//因为在栈空时我们让top在-1的位置上,这样也更符合数组下标的特性,比如当top指针指向的是
//栈顶元素时,此时它的位置正好是MAXSIZE-1
//在王卓老师的课程中提到了另一种方式也比较好,其核心就是让
{
return false;
} else{
++s->top;//先让top指向下一个empty空间
s->data[s->top]=data;//再把数据放进来
return ture;
}
}
//出栈
bool pop(Sqstack*s,Elemtype*data)//出栈需要返回一个数据,所以这里我们用*data来把值带出去
{
if(s->top == -1)
{
return false;
} else{
*data=s->data[s->top];//先让data指向栈顶元素
--s->top;//再让top指向下一个元素 而弹出的栈顶元素已经不在栈中
return ture;
}
}
//取栈顶元素
bool gettop(Sqstack s,Elemtype*data)
{
if(s.top == -1)
{
return false;
} else{
*data=s.data[s.top];//让data指向栈顶元素
return ture;
}
}
int main() {
Sqstack s;
initStack(&s);
push(&s,1);
push(&s,2);
push(&s,3);
Elemtype X;//用于保存出栈和读栈顶元素返回的变量的值
int count =s.top;
for (int i = 0; i <= count; i++)
{
printf("i=%d\n",i);
gettop(s,&X);
printf("get X=%d\n",X);
pop(&s,&X);
printf("pop X=%d\n",X);
}
return 0;
}
链栈
看到这里 如果真的有自己手敲一遍代码的同学会发现 这些对于栈也好还是下面的队列也好 我觉得本质上它的基本操作无非就是增删改查以及遍历,而对于这些用顺序存储方式来实现的,本质上就是对数组的操作,无非就是针对于不同的数据结构特点来制定特别的操作方式,以及对于结构体改如何定义的问题。我觉得大家在学习数据结构与算法这门课时最好需要有一种框架性思维,这也是我几天前在B站上刷到了拉布拉东对于其的讲解,真的是豁然开朗,建议大家花时间观看!

- 由于链栈不常用这里就不给出具体的代码示例了
队列

循环队列的引入
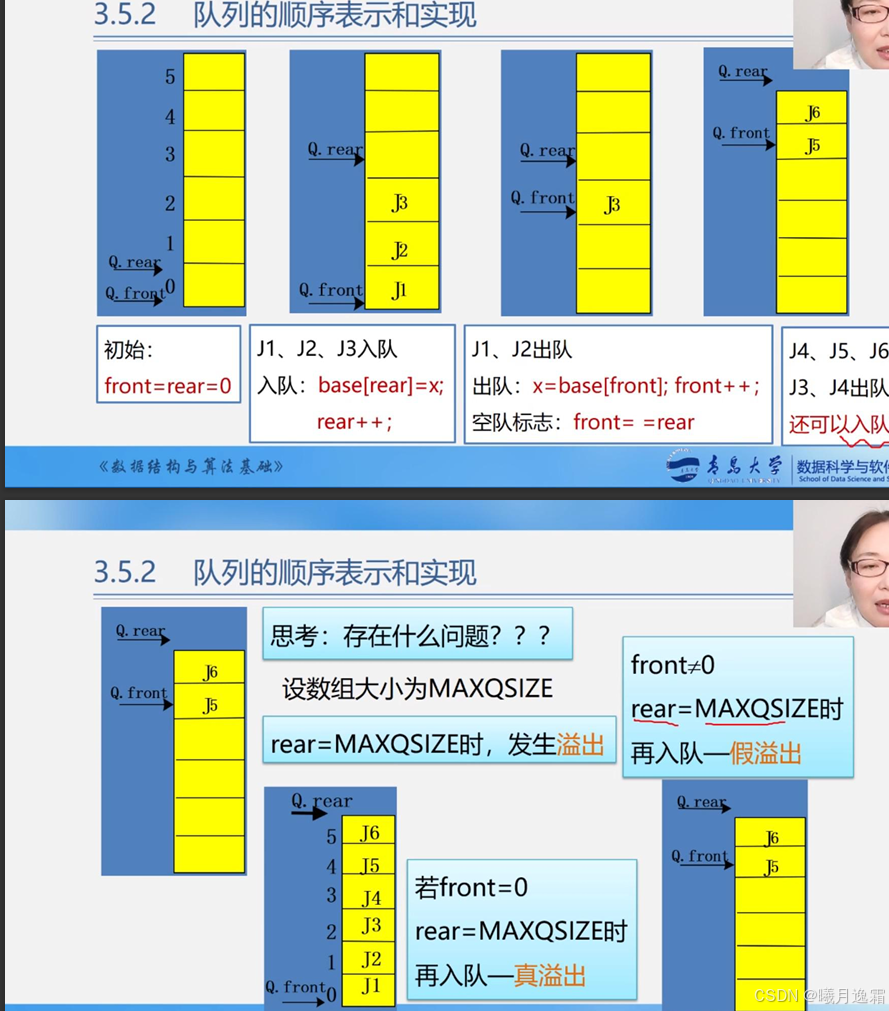
请大家务必好好看看上面的图片 这就是我们为什么常常采用循环队列的原因——即可以反复地去利用空间 在现实生活中我们去排队,前面有人走了 后面自动就会有人跟上,不存在会有空出来位置没人的情况 而在队列中我们可没有这么智能 而如果不这么做的话就会导致上图的假溢出的情况 这对于存储空间是极大的浪费 这就是为什么我们会引入循环队列 对于循环队列 我们可以将它想象成一个游泳圈 只要有人进来或者离开对应的front和rear指针就会发生移动 直到front==rear的情况 也就队满
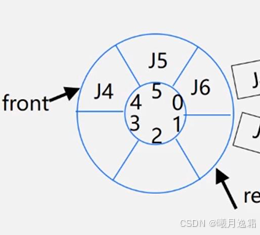
这就有引入了我们的下一个问题 在队空时的判断条件也是front==rear,那我们该如何区分栈空栈满呢???
这个方法的核心就是“少用一个元素空间”以及循环队列的“循环”到底怎么用代码写出来 这个我觉得是非常重要的 希望大家仔细体会
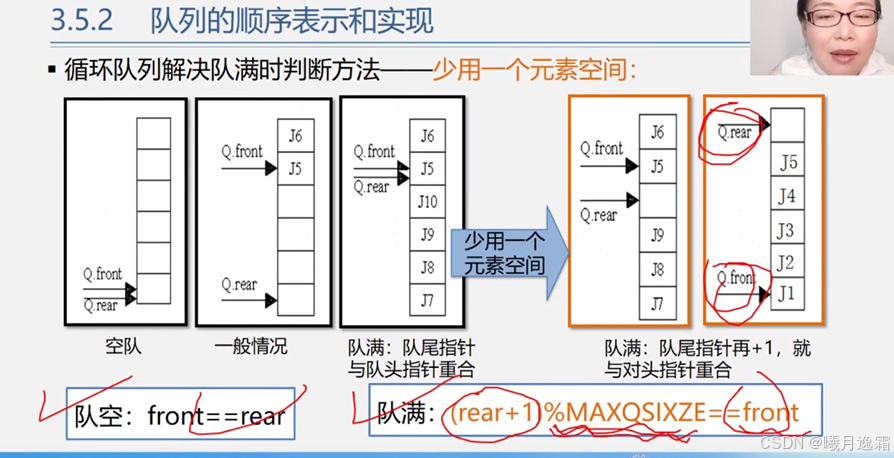
循环队列代码演示(先做在看!!!)
对于其中的入队,出队和get队长这三个函数需要格外注意!!!
#include <stdio.h>
#include <stdlib.h>
#define MAXSIZE 100
#define OK 1
#define ERROR 0
#define OVERFLOW -1
typedef int Status;
// 队列结构体定义
typedef struct Queue {
int base[MAXSIZE];
int rear;
int front;
} Queue;
// 初始化队列
Queue* InitQueue() {
Queue* L = (Queue*) malloc(sizeof(Queue));
if (L == NULL) {
fprintf(stderr, "Memory allocation failed\n");
return NULL;
}
L->front = 0;
L->rear = 0;
return L;
}
// 插入元素到队列
Status EnQueue(Queue* L, int e) {
if ((L->rear + 1) % MAXSIZE == L->front) { // 判断队列是否已满
return OVERFLOW;
}
L->base[L->rear] = e;
L->rear = (L->rear + 1) % MAXSIZE;
return OK;
}
// 出队操作
Status DeQueue(Queue* L, int* e) {
if (L->rear == L->front) { // 判断队列是否为空
return ERROR;
}
*e = L->base[L->front];//因为要获取队头元素,所以这里采用指针的方式
L->front = (L->front + 1) % MAXSIZE;
return OK;
}
// 获取队列长度
int GetLength(Queue* L) {
return (L->rear - L->front + MAXSIZE) % MAXSIZE;
}
// 打印队列元素
void PrintQueue(Queue* L) {
int temp_front = L->front;
while (temp_front != L->rear) {
printf("%d ", L->base[temp_front]);
temp_front = (temp_front + 1) % MAXSIZE;
}
printf("\n");
}
// 释放队列内存
void FreeQueue(Queue* L) {
if (L != NULL) {
free(L);
}
}
int main() {
Queue* L = InitQueue();
if (L == NULL) {
return -1;
}
int element;
EnQueue(L, 1);
EnQueue(L, 2);
PrintQueue(L);
if (DeQueue(L, &element) == OK) {
printf("Dequeued element: %d\n", element);
}
PrintQueue(L);
FreeQueue(L);
return 0;
}


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









