






函数
1.函数分为:
①:内置函数:系统内置的通用函数。
②:自定义函数:跟据自己的要求编写的
从实现的功能角度:
①数值函数
②字符串函数
③日期和时间函数
④流程控制函数
⑤加密函数
⑥解密函数
⑦获取MySQL信息函数
⑧聚合函数
不同DBMS函数的差异:DBMS之间的差异性很大,远大于同一个语言不同版本之间的差异。这就意味着采用SQL函数的可移植性很差。
1.单行函数
1.操作数据对象
2.接收参数返回一个结果
3.只对一行进行变换
4.每行返回一个结果
5.可以嵌套
6.参数可以是一列或一个值
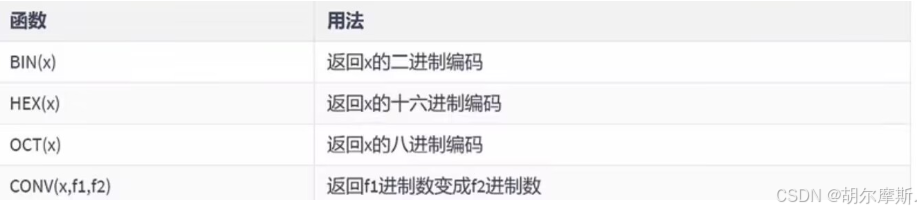
1.数值型函数



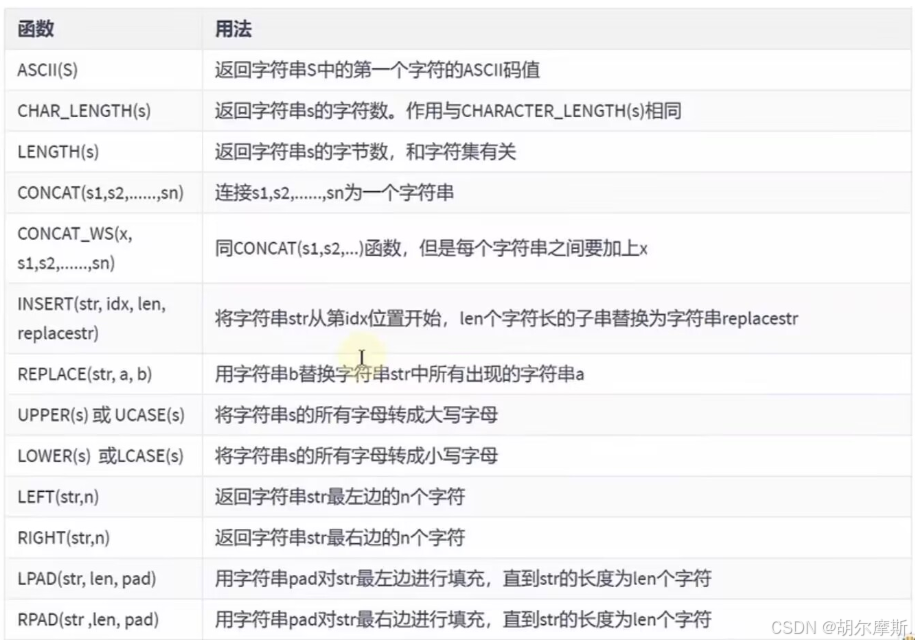
2.字符串类型的函数
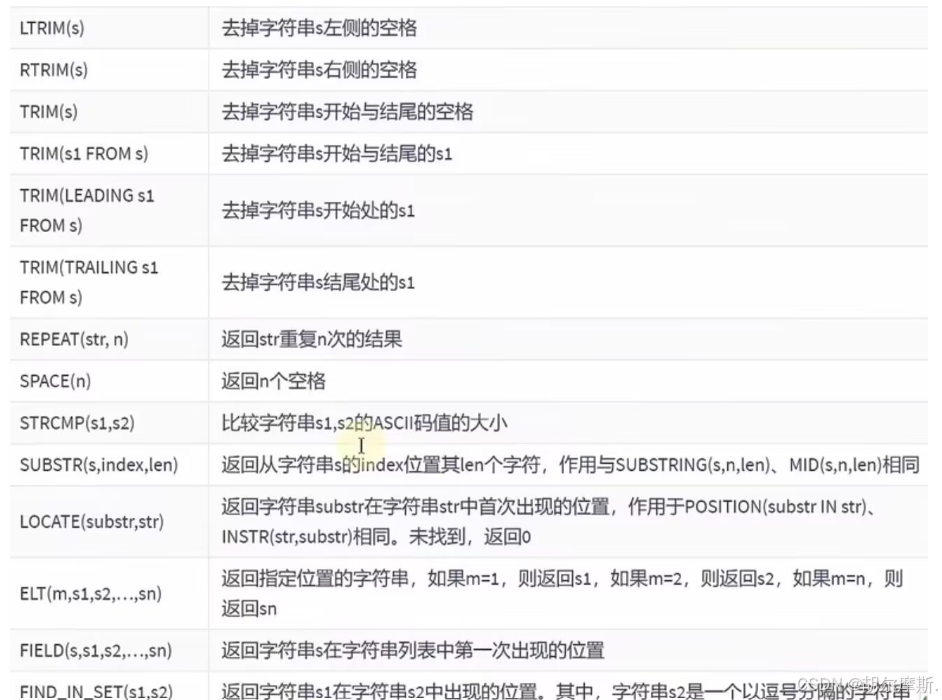

注意:SQL中字符串的索引从1开始
3.日期和时间类型的函数
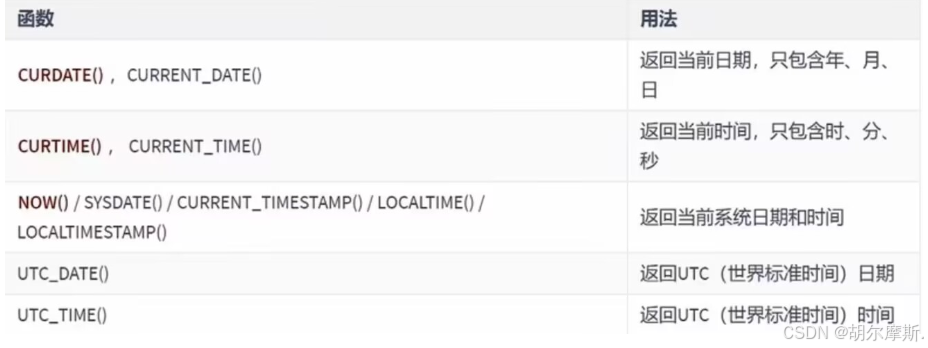
3.1获取日期和时间
3.2日期和时间戳的转换

3.3获取月份,星期,星期数,天数等
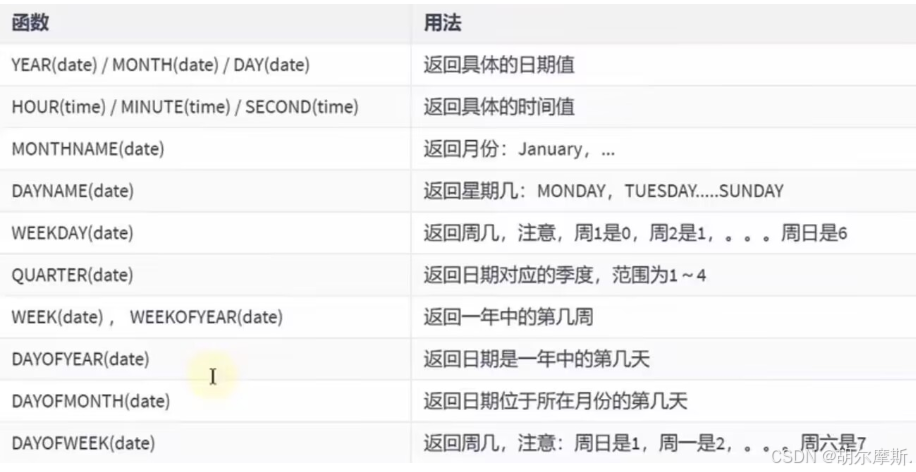

3.4日期操作函数
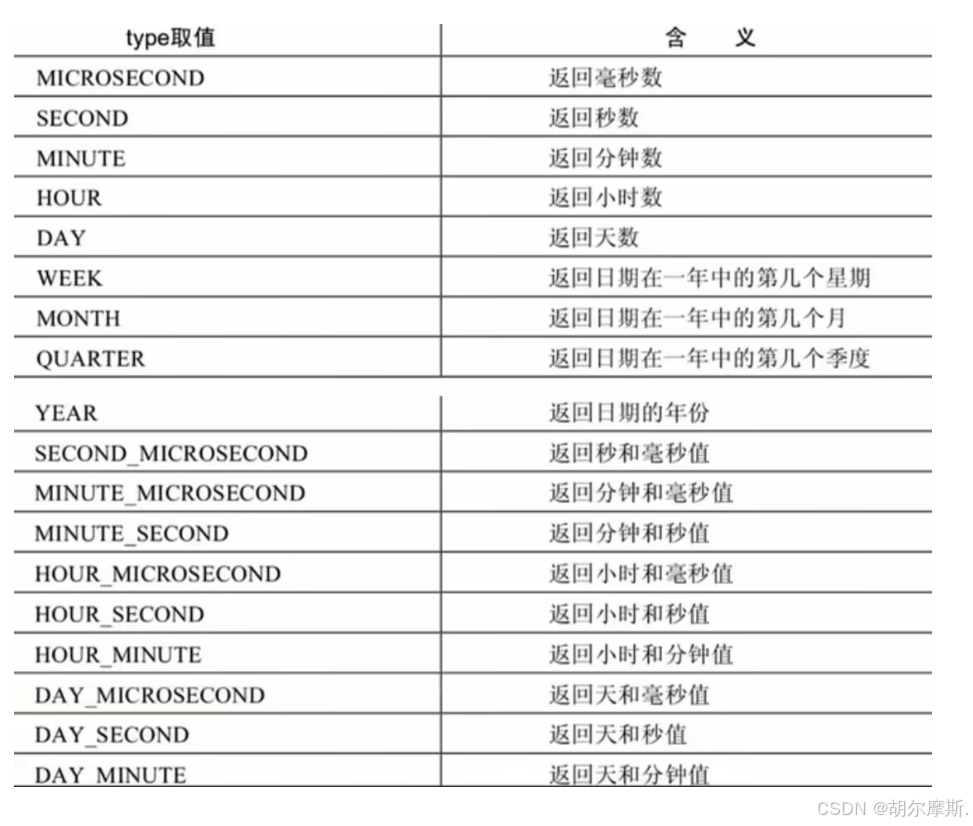

3.5时间和秒钟的转换函数

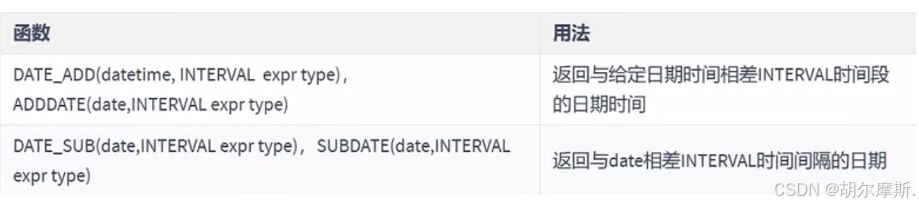
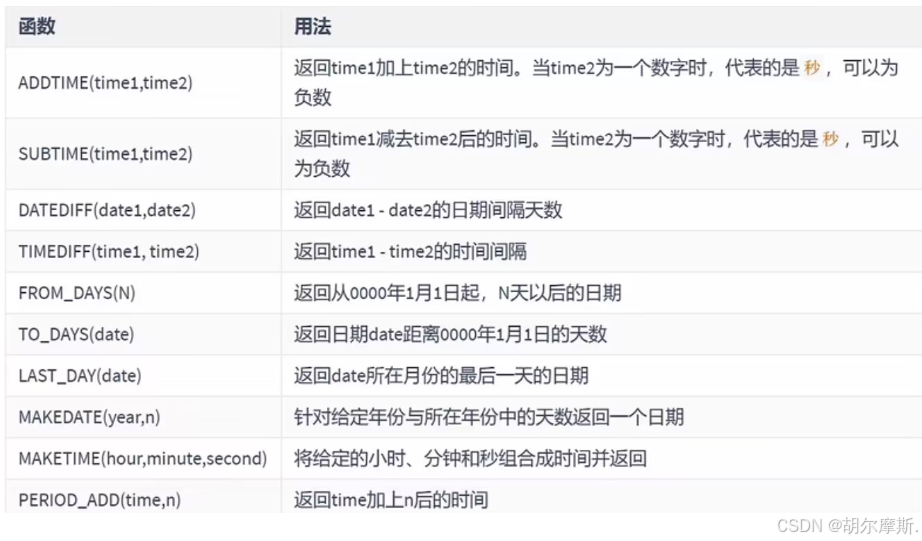
3.6计算日期和时间的函数
3.7日期的格式化与解析
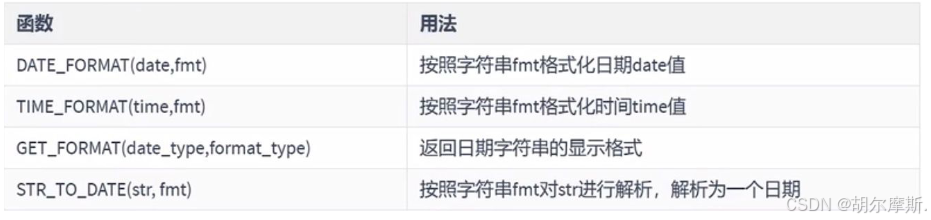
日期的格式化与解析 格式化:日期--->字符串 解析:字符串--->日期
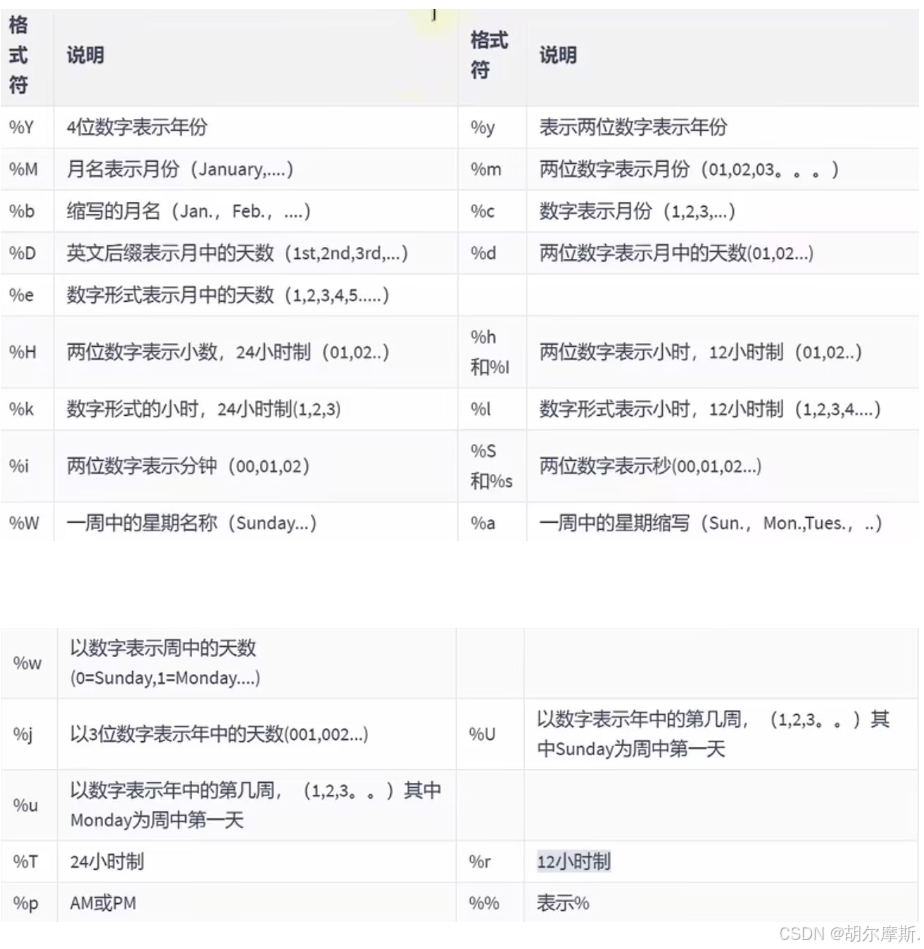
4.流程控制函数
流程处理函数可以跟据不同的条件,执行不同的处理流程,可以在SQL语句中实现不同的条件选择。MySQL中的流程处理函数主要包括IF() , IFNULL()和CASE()函数
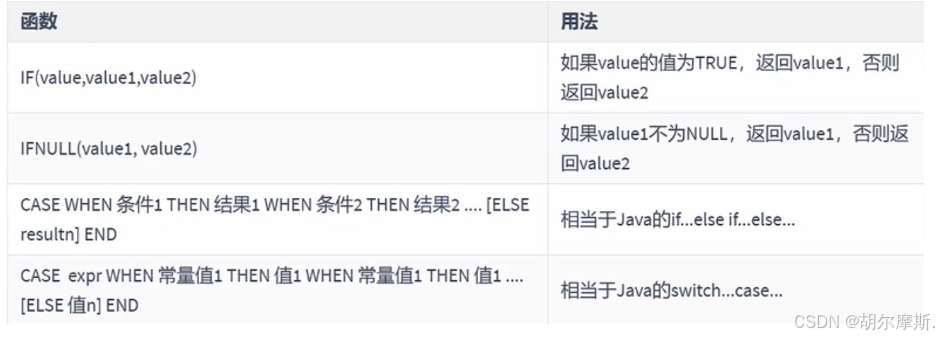
5.加密与解密函数
加密与解密函数主要用于对数据库中的数据进行加密与解密处理,以防被他人所窃取。
这些函数在保证数据库安全时非常有用。
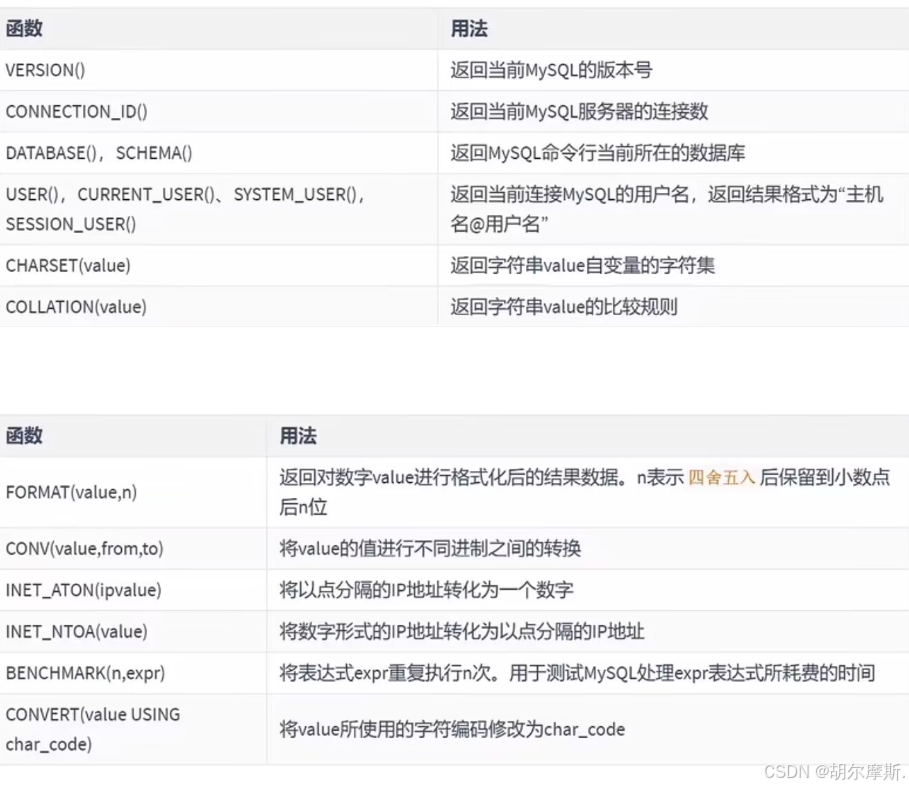
6.与MySQL有关的函数
2.多行函数(聚合函数)
1.聚合函数类型
1,AVG()
2.SUM()
3.MAX()
4.MIN()
5.COUNT()
1.SUM()/AVG()
当查询的字段中出现NULL值时会自动过滤
只适用于数值类型的字段(或变量) SELECT SUM(last_name),AVG(last_name) FROM employees;
2.MAX()/MIN()
当查询的字段中出现NULL值时会自动过滤
适用于数值类型,字符串类型,日期时间类型的字段(或变量) SELECT MAX(last_name),MIN(last_name) FROM employees;
3.count()
作用:计算指定字段在查询结构中出现的个数 SELECT COUNT(employee_id),COUNT(salary), COUNT(1),COUNT(*) FROM employees;
1.当查询的字段中出现NULL值时会自动过滤 SELECT COUNT(commission_pct) FROM employees;
2.结论:AVG=SUM/COUNT SELECT AVG(commission_pct), SUM(commission_pct)/COUNT(commission_pct) avg1, SUM(commission_pct)/107 FROM employees;
4.GROUP BY(分组函数)
1.可以使用GROUP BY子句将表中数据分成若干组 SELECT department_id,AVG(salary),SUM(salary) FROM employees GROUP BY department_id;
SELECT job_id,AVG(salary),SUM(salary) FROM employees GROUP BY job_id;
使用多个列分组 SELECT job_id,department_id,AVG(salary),SUM(salary) FROM employees GROUP BY job_id,department_id; #或者写作 SELECT department_id,job_id,AVG(salary),SUM(salary) FROM employees GROUP BY department_id,job_id;
2.SELECT中出现的非组函数的字段必须声明在GROUP BY中
反之GROUP BY中声明的字段可以不出现在SELECT中
#错误的写法 SELECT job_id,department_id,AVG(salary) FROM employees GROUP BY department_id;
3.GROUP BY中使用WITH ROLLUP
使用WITH ROLLUP关键字之后,在所有查询出的分组记录之后增加一条记录,
该记录计算查询出的所有记录的总和,即统计记录数量。
SELECT department_id,AVG(salary) FROM employees GROUP BY department_id WITH ROLLUP;
5.HAVING的使用
要求1:如果过滤条件中使用了聚合函数,则必须使用HAVING来替换WHERE,否则报错
要求2:HAVING必须声明在GROUP BY的后面
①行已经被分组
②使用了聚合函数
③满足HAVING子句中条件的分组将被显示
④HAVING不能单独使用,必须要跟GROUP BY一起使用
SELECT department_id,MAX(salary) FROM employees WHERE department_id IN (10,20,30,40) GROUP BY department_id HAVING MAX(salary)>10000;
WHERE与HAVING对比
1.WHERE可以直接使用表中的字段作为筛选条件,但不能使用分组中的计算函数作为筛选条件;HAVING必须要与GROUP BY配合使用。可以使用分组中的计算函数和分组字段作为筛选条件。
2.如果需要通过连接从关联表中获取需要的数据,WHERE是先筛选后连接。而HAVING是先连接后筛选。WHERE执行效率高于HAVING
6.SQL底层执行原理
1.SQL92语法
SELECT...,...,(存在聚合函数)
FROM...,...,...
WHERE 多表连接条件 AND 不包含聚合函数的过滤条件
GROUP BY...,...
HAVING 包含聚合函数的过滤条件
ORDER BY ...,...(ASC/DESC)
LIMIT ...,...
2.SQL99语法
SELECT...,...,(存在聚合函数)
FROM... (LEFT/RIGHT)JOIN ... ON ...
(LEFT/RIGHT)JOIN... ON ...
WHERE 不包含聚合函数的过滤条件
GROUP BY...,...
HAVING 包含聚合函数的过滤条件
ORDER BY ...,...(ASC/DESC)
LIMIT ...,...
SQL语句的执行过程:
FROM---->ON---->(LEFT/RIGHT JOIN)---->WHERE---->GROUP BY---->HAVING---->SELECT---->DISTINCT---->ORDER BY---->LIMIT

















 796
796

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









