






整形数据类型
1 . 整形数据的编码
整形数据类型有三种:原码,反码和补码。
注 :整形数据在计算机中的储存形式是补码。
原码
定义:原码是指将一个数值的绝对值转换为二进制数,再补齐或截取相应的字节位后,将最高位用来表示符号,1表示负数,0表示正数。
例如:
10 的双字节原码:0 000 0000 0000 1010
-10的双字节原码:1 000 0000 0000 1010
反码
定义:原码除符号位以外的各位逐一取反后形成的二进制编码。
注:正数的反码和原码相同。
例如:
-10的双字节反码:1 111 1111 1111 0101
补码
正数的补码和原码相同,而负数的补码则是该数的反码 +1 后形成的二进制编码。
例如:
-10 的双字节补码:1 111 1111 1111 0110
2. 整形数据的表示
在C语言中,整型类型以关键字 int 作为基本类型说明符,另外配合四个类型修饰符 long(长)、short(短)、signed(有符号)、unsigned(无符号) 来改变和扩充基本类型含义。
注: int 单独使用默认为 signed int 。即有符号整形。
以下给出整形数据的表示方式和表示范围:

我相信有很多小伙伴可以看出int 和 long int 不管是占用内存和示数范围都是一样,这是怎么回事呢?
事实上是不同的,图片中使用的32位系统的编译器。
在32位系统中, int 和 long int 通常都占用4个字节(32位)。
对于有符号类型:
- 占用内存:4字节(32位)
- 示数范围: - 231 到 231- 1 ,即 - 2147483648到2147483647。
- 这是因为在32位系统中,为了提高内存访问效率和数据处理的一致性, int 和 long int 被设计为具有相同的大小。
而且在C语言规则中,对于 int 和 long int 只规定 long int 类型的示数范围不能小于 int 类型,但也允许他们的示数范围相同。
64位系统
- 在64位系统中,情况可能有所不同。
- int 通常仍然是4个字节(32位),但 long int 可能是8个字节(64位)。
- 对于有符号 long int (如果是8字节):
- 占用内存:8字节(64位)
- 示数范围: -263 到 263 - 1 ,即 - 9223372036854775808到9223372036854775807
总之, int 和 long int 在某些情况下占用内存和示数范围相同是由于特定系统架构和历史兼容性的原因,但在不同的平台和编译器下,它们的大小和范围可能会有所不同。
3.数据溢出
- 定义
- 数据溢出是指在进行数据运算时,计算结果超出了数据类型所能表示的范围。C语言中的基本数据类型(如 int 、 char 、 long 等)都有其特定的取值范围。
加法溢出
我们使用上述给出的整形数据类型可以写下以下代码:
#include<stdio.h>
int main()
{
int a = 2147483647;
int b = 0;
b = a + 1;
printf("%d", b);
return 0;
}
结果如下:

这里 a 被初始化为 int 类型所能表示的最大值2147483647。当我们试图将 a 加1时,结果超出了 int 类型的范围,就会发生溢出。在这种情况下, b 的值会变成 - 2147483648,这是因为 int 类型是有符号的,超出范围后会“循环”到最小值。
减法溢出
#include<stdio.h>
int main()
{
int a = -2147483648;
int b = 0;
b = a - 1;
printf("%d\n", b);
return 0;
}
结果如下:
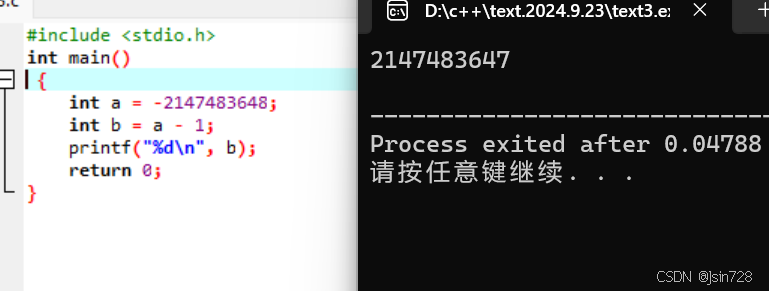
这里 a 是 int 类型所能表示的最小负数,当 a 减1时,结果会溢出变成2147483647。
如果数据整形编码和整形数据溢出结合,我们应该如何应对呢?
我们出一个例题看看:
写出以下的代码。
#include <stdio.h>
int main()
{
short a = 0;
short b = 0;
a = 32767;
b = a + 2;
printf("%d", b);
return 0;
}
输出结果:
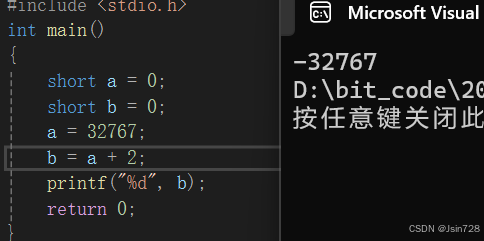
我们先表示出:
变量a的二进制数为:0111 1111 1111 1111
变量b的二进制数为:1000 0000 0000 0001
对于变量b 首位为 1 ,则表示为负数,又因为计算机中储存的是数据的补码,想要求出负数原码,则需要求出负数的反码后加一。
具体步骤如下:
变量b 的反码除首位不变,其余都变化:1111 1111 1111 1110
再将反码加一,则得到b的原码
b 原码:1111 1111 1111 1111
可见结果正为 -32767。
数据溢出在C语言编程中是一个需要谨慎处理的问题,了解其原理和处理方法对于编写可靠的程序至关重要。
四.实型数据类型
定义:用于表示带小数点的数据,根据表示范围和精度的不同,分为单精度(float),双精度(double)。
以下为实行数据类型的情况:

实数在计算机中是以指数形式存储的,对于任意形式的实数,均转换成指数形式。
科学计数法
一、科学计数法的表示形式
- 基本格式
- 在C语言中,科学计数法的格式为 aEn 或 aen ,其中 a 是尾数( 可以是整数或小数 ), n 是指数( 必须是整数 )。
- 例如, 1.23e4 表示 1.23×10⁴ ,即 12300 ; 4.56e-2 表示 4.56×10⁻² ,即 0.0456 。
二、数据类型与精度
- float类型
- 当使用 float 类型存储用科学计数法表示的数据时,要注意 float 的精度有限。 float 通常有大约7位有效数字。(这里的七位有效数字是输出前七位是准确的)
- 例如:
#include <stdio.h>
int main() {
float num = 1.23456789e2;
printf("%f\n", num);
return 0;
}
输出结果为:
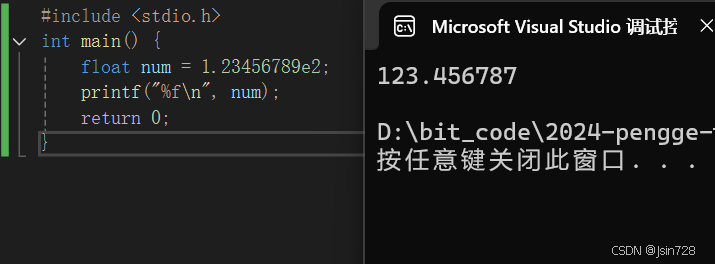
这里 num 的值在输出时可能会出现精度损失,因为 1.23456789e2 (即 123.456789 )超过了 float 能精确表示的范围,实际输出可能是 123.456787 之类的近似值。
- double类型
- double 类型有更高的精度,通常有大约15 - 16位有效数字。
- 例如:
#include <stdio.h>
int main() {
double num = 1.23456789012345e2;
printf("%lf\n", num);
return 0;
}
结果如下:
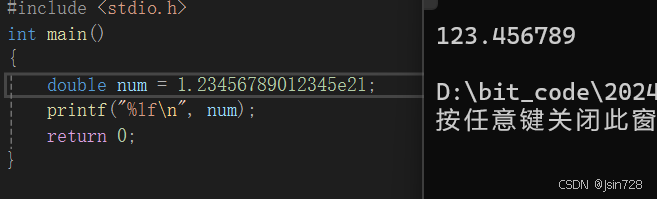
可以看到全是正确数字,%f 和 %lf 默认打印小数点后六位数。
注:%f 用于打印单精度(float),%lf 打印双精度(double)。
用 double 存储时,能更精确地表示较大或较小的数。
三、运算中的注意事项
- 精度损失
- 在对用科学计数法表示的数进行运算时,要注意可能出现的精度损失问题。特别是在 float 类型的运算中,多次运算可能会累积误差。
- 例如
#include <stdio.h>
int main() {
float a = 1.23e3;
float b = 4.56e-1;
float c = a + b;
printf("%f\n", c);
return 0;
}
结果如下:
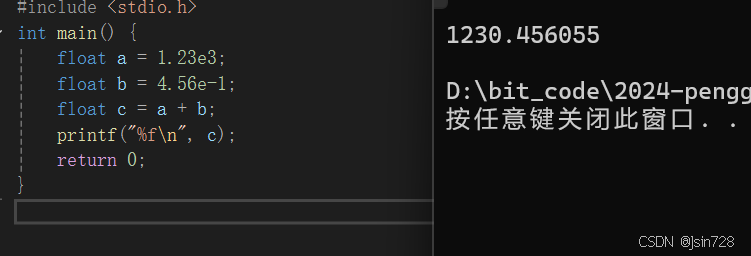
这里 a 和 b 相加时,可能会因为 float 的精度问题导致结果有一定偏差。
在C语言中使用科学计数法时,需要充分考虑数据类型的精度、输入输出的格式以及运算中的误差问题,以确保程序的正.
单精度浮点型(float)
- 占用内存:通常占用4个字节(32位)。
- 表示范围:大约在 ±3.4×10⁻³⁸ 到 ±3.4×10³⁸。
- 精度:大约有7位有效数字。
- 实例:
float num1 = 3.14f;
注意:在C语言中,给 float 类型赋值时,通常在数值后面加上 f 或 F 来明确表示这是一个单精度浮点型常量,以免编译器将其当作双精度浮点型处理。
- 双精度浮点型(double)
- 占用内存:通常占用8个字节(64位)。
- 表示范围:大约在 ±1.7×10⁻³⁰⁸ 到 ±1.7×10³⁰⁸。
- 精度:大约有15 - 16位有效数字。
- 示例:
double num2 = 3.141592653589793;
- 长双精度浮点型(long double)
- 占用内存:因编译器和系统而异,可能占用8字节、10字节或16字节。在某些系统上, long double 的精度和范围比 double 更高。
- 表示范围和精度:不同系统下有所不同,但通常比 double 更精确、范围更大。
- 例如:
double long num 3 = 3.141592653589793l;
注意:在C语言中,给 long double 类型赋值时,通常在数值后面加上 L 或 l 来明确表示这是一个长双精度浮点型常量。
五.字符型数据类型
- 字符型数据类型的定义与概念
- 在编程语言中,字符型数据类型主要用于存储单个字符。在C语言中,字符型用 char 来表示。它在内存中占用**1个字节(8位)**的存储空间。
- 例如,字符 ‘A’ 、 ‘a’ 、 ‘0’ 等都可以用 char 类型来存储。需要注意的是,字符型数据存储的是字符的ASCII码值(在C语言中,ASCII码是最常用的字符编码方式)。例如,字符 ‘A’ 的ASCII码值是65,字符 ‘a’ 的ASCII码值是97,字符 ‘0’ 的ASCII码值是48。
- 字符型数据类型的表示方法
- 字符常量:用单引号括起来的单个字符,如 ‘A’ 、 ‘b’ 、 ‘$’ 等。另外,还有一些特殊的转义字符,例如 ‘\n’ (表示换行)、 ‘\t’ (表示制表符)、 ‘\’ (表示反斜杠本身)等。这些转义字符用于表示一些难以直接用普通字符表示的字符或字符序列。
- 字符变量:在C语言中,可以通过声明 char 类型的变量来存储字符。例如:
char ch;
ch = 'A';
- 这里声明了一个 char 类型的变量 ch ,并将字符 ‘A’ 赋值给它。
- 字符型数据类型的运算
- 算术运算:由于字符型数据存储的是ASCII码值,所以可以对字符型数据进行算术运算。例如:
c
char ch1 = 'A';
char ch2 = ch1 + 1;
printf("%c\n", ch2);
- 在这个例子中,首先将字符 ‘A’ 赋值给 ch1 ,然后将 ch1 的ASCII码值(65)加1得到66,再将66对应的字符( ‘B’ )赋值给 ch2 ,最后通过 printf 函数以字符形式输出 ch2 ,结果为 ‘B’ 。
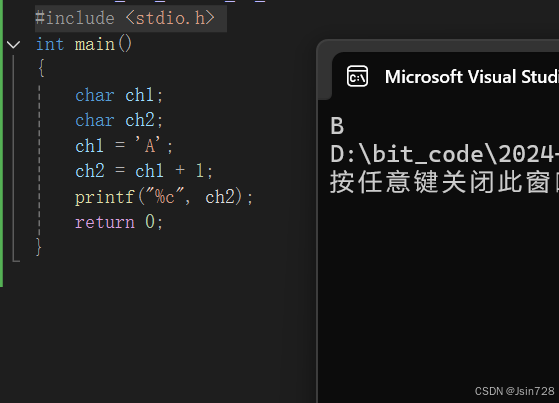
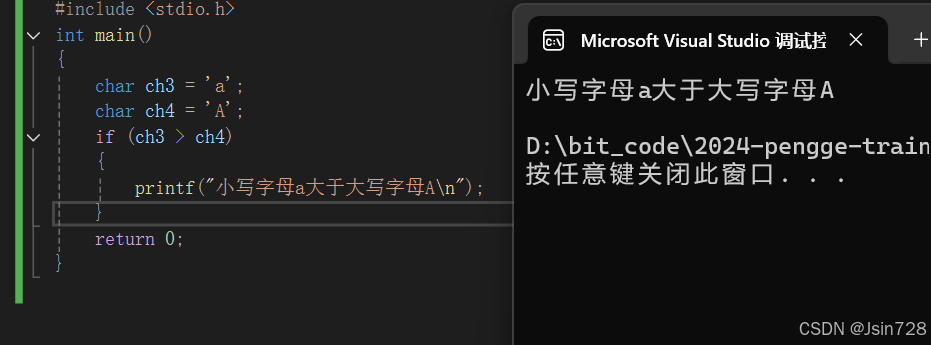
- 比较运算:可以对字符型数据进行比较运算,比较的是字符的ASCII码值。例如:
char ch3 = 'a';
char ch4 = 'A';
if (ch3 > ch4)
{
printf("小写字母a大于大写字母A\n");
}
- 因为小写字母 a 的ASCII码值(97)大于大写字母 A 的ASCII码值(65),所以条件成立,会输出相应的结果。
上面的 if 语句先不要着急,后面会讲到的。
今天我们先到这里,后续会更新常量,小编也是学者,如果哪里有错,希望大家可以提出了,一起进步,一起提升。

















 4782
4782

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









