






MybatisPlus
MybatisPlus是基于Mybatis的一个组件,能够帮我们省去很多操作,也能够进行自定义操作,可以看作是对mybatis的加强
1.MybatisPlus入门
Mybatis通过扫描实体类,并基于反射获取实体类信息作为数据库表信息
1.MybatisPlus引入
1.1引入MybatisPlus起步依赖
我们在idea的pom文件中添加如下依赖
<!-- MybatisPlus依赖-->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.4.1</version>
</dependency>
1.2自定义Mapper继承MybatisPlus提供的BaseMapper接口
我们定义一个mapper,用来基础mp为我们提供的接口,User是我们的实体类,这个接口根据泛型User通过反射来获得我们实体类的信息,根据信息的属性来填充BaseMapper的方法
由于我们直接继承了这个类,所以我们可以直接用BaseMapper里的方法
如下
public interface UserMapper extends BaseMapper<User>{
}后续我们直接使用UserMapper根据指定方法查询即可,不需要手写方法
2.常见注解
MybatisPlus是通过扫描实体类,基于反射获取实体类信息作为数据库表信息
public interface UserMapper extends BaseMapper<User>{
}通过扫描USer来获取信息

类名为驼峰命名法的会转为下划线命名作为表名
名为id的字段作为主键
变量名驼峰转下划线作为表的字段名
用这种逻辑可以知道表的信息
如果我们的实体类不符合以上约定:如不采用驼峰命名,类名和表名不一致等,我们就需要自定义配置
MybatisPlus常用的注解如下:
| @TableName | 用来指定表名 |
| @Tableld | 指定表中的主键字段信息 |
| @TableField | 指定表中的普通字段信息 |
在需要指定表名为某某表的pojo类上加上注解进行之定义配置
tableId的各类配置如下,可以根据我们需要来在注解里添加
1.TableId
idType枚举:
AUTO:数据库自增长 //数据库生成id
INPUT:通过set方法自行输入 //自己输入id
ASSIGN_ID:分配ID,接口IdentifierGenerator的方法newxtId来生成id //mp生成id
默认实现类为defaultIdentifierGenerator雪花算法
如果没加上id的类型就会默认使用雪花树算法
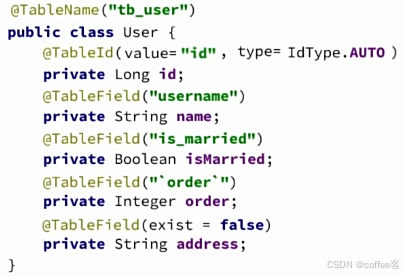
@TableName("tb-user")
@Data
public class User {
/**
* 用户id
*/
@TableId(value = "id",type = IdType.AUTO)
private Long id;
}2.@TableField
通常我们不需要使用tableField注解,因为大部分都符合条件
1.成员变量和数据库字段名不一致时
2.成员变量以is开头,而且是布尔值时(会去掉is)
3.成员变量名与数据库关键字冲突
4.成员变量不是数据库字段(不存在这个字段)
如表
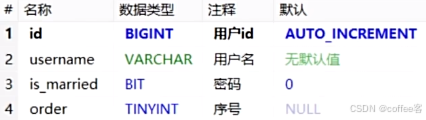
可以使用TableField
3.常见配置
Mybatis配置项除了继承Mybatis原生配置,还有一些特有的配置
如下所展示
mybatis-plus:
mapper-locations: classpath*:mapper/*.xml#继承的功能
global-config:
db-config:#特有的功能
#以下原本就是默认值,为方便展示所使用
id-type: assign_id #id为雪花算法生成
update-startegy: not_null #更新策略:只更新非空字段
4.核心功能
4.1条件构造器(***Wrapper)
如果我们有比较复杂的sql语句
可以用这帮我们构造各种解决复杂条件的功能
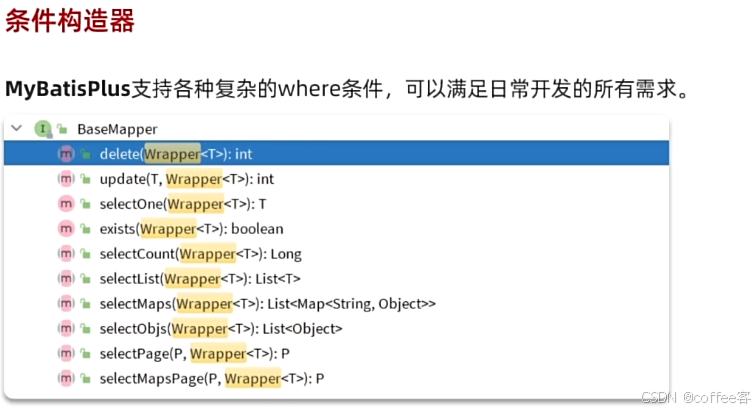
首先在我们的mapper类中要继承这个接口
public interface UserMapper extends BaseMapper例如我们要查询名字中带o的,存款大于等于1000人民币的人的id,username,info,balance的人

原本要在mapper层中编写如上代码,而且Service层等方法要配置
void testQueryByIds() {
// List<User> users = userMapper.queryUserByIds(List.of(1L, 2L, 3L, 4L));
// users.forEach(System.out::println);
//1.构造查询条件
QueryWrapper<User> wrapper =new QueryWrapper<User>()
.select("id","username","info","balance")
.like("username","o")
.ge("balance",1000);
//2.查询 此时把查询到的数据放到了wrapper集合中
List<User> users=userMapper.selectList(wrapper);
users.forEach(System.out::println);
}现在我们直接调用mapper继承的QueryWrapper方法进行查询
现在例如我们要更新用户数据
更新id为1,2,4的用户余额扣除200

void testUpdateById() { // 1.更新数据 List<Long> ids=List.of(1L,2L,3L); // 2.更新条件 UpdateWrapper<User> wrapper=new UpdateWrapper<User>() .setSql("balance=balance-200") .in("id",ids); // 3.执行更新 // 第一个参数是更新参数,由于我们在wrapper里写了所以不需要 userMapper.update(null,wrapper); }
前面几种方法不太符合规约,因为很难维护,不好看出来各类参数配置
一般使用lambdaWrapper来解决
如前面的查询方法,可以看到很清楚每个参数的变量之间的关系如.ge("balance",1000)表示User里的balance的值为1000,select里的参数表示要对这些参数进行查询,这些都不好看出来
@Test
void testQueryByIds() {
// List<User> users = userMapper.queryUserByIds(List.of(1L, 2L, 3L, 4L));
// users.forEach(System.out::println);
//1.构造查询条件
QueryWrapper<User> wrapper =new QueryWrapper<User>()
.select("id","username","info","balance")
.like("username","o")
.ge("balance",1000);
//2.查询
System.out.println(wrapper);
List<User> users=userMapper.selectList(wrapper);
users.forEach(System.out::println);
}改成
就是将字符串改成利用反射机制得到User里对应的参数的方法
更加直观简洁,如图,整个属性和值的关系很直观,所以我们建议用这种方法
void TestLambda(){
LambdaQueryWrapper<User> wrapper =new LambdaQueryWrapper<User>()
.select(User::getId,User::getUsername,User::getInfo,User::getBalance)
.like(User::getUsername,"o")
.ge(User::getBalance,1000);
System.out.println(wrapper);
List<User> users=userMapper.selectList(wrapper);
users.forEach(System.out::println);
}
4.2自定义SQL
我们可以利用MybatisPlus的Wrapper来构建复杂的Where条件,然后自己定义sql语句中剩下的部分

我们先定义wraper方法:如图in语句直接取代了foreach的复杂判断

但是mp适合编写复杂where判断语句,如果是要将balance改为动态地赋值就要在业务层去拼接sql语句,就违反了开发规范,就和我们需要的效果(直接不需要操作底层sql来进行动态赋值)
所以我们一般将mp擅长的where构建让他去做,剩下的sql我们来写
这个传递过程我们应该如何去做
1.利用wrapper构建where条件

2.在mapper方法中自定义一个方法,并用Param注解声明wrapper变量名称,变量名称必须是ew
![]()
3.在xml里自定义Sql,并使用wrapper条件
ew调用的方法就是自定义sql片段

4.3Service接口
利用Service接口,可以帮我们直接实现一些基础的service
Service接口继承IService,里面也有get,update等功能
如save,第一个就是基础的新增功能,而saveBatch可以看到传参是集合,因此是对批量数据进行新增的方法,saveOrUpdateBatch就是增或改,通过判断传入的数据是否有id,如果没有就执行update更新,如果有就执行save新增

如remove,也是通过方法名可以看出来功能,如removeById就是根据id删除
removeByIds就是批量删除 底层是用in
而removeBatchIds使用delet from..id=..用jdbc的方式批量提交删除,性能比in好,但是数据量少利用ByIds即可
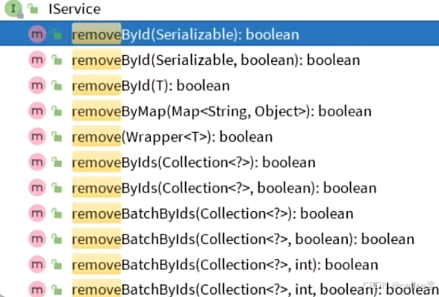
由于Service是接口不像Mapper接口有mybatis动态代理给我们生成实现类,它的实现类ServiceImpl需要实现所有实现的方法
因此mp也为我们提供了实现所有方法的类ServiceImpl,我们只需要将我们自己的实现类继承这个类即可
1.UserService继承IService
一定要加泛型
public interface IUserService extends IService<User>2.UserServiceImpl实现UserService并继承Service
public class UserServiceImpl extends ServiceImpl<UserMapper, User> implements UserService {
}可以看到,我们还要提供两个泛型-一个为UserServiceImpl用到的mapper,另一个是相关的实体类
@Service
public class UserServiceImpl extends ServiceImpl<UserMapper,User> implements IUserService {
}我们创建一个测试类
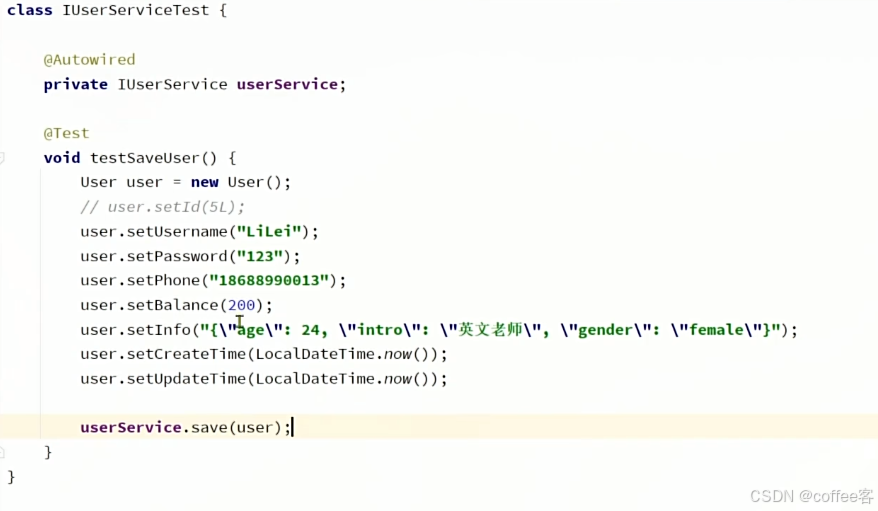
就直接调用我们的userService实现了方法,但是我们Service里没有自己写方法,都是Iservice里继承得到的方法
2.实战环节
1.简单方法的实现
我们先在controller类中注入要用的userService
@Autowired
private IUserService userService;但是 spring此时建议我们用构造器的方式注入
private final IUserService userService;
public UserController(IUserService userService) {
this.userService = userService;
}但是这个方法要用到多个bean的话就比较麻烦
因此我们直接用lambok的方法
@AllArgsConstructor来直接注入所有的bean
但是我们只需要service的bean
所以我们用这个注解即可——必备构造函数 作用是只会所有对一开始就需要初始化的变量进行构造
只要是加了final的bean都会自动构造
@RequiredArgsConstructor//所以只加final 就行,final一开始就需要初始化
private final IUserService userService;最终效果
@RequiredArgsConstructor
public class UserController {
private final IUserService userService;
@ApiOperation("新增用户接口")
@PostMapping
public void saveUser(@RequestBody UserFormDTO userFormDTO){
}
}最终实现效果:
我们不需要写Service和mapper,mp自动帮我们完成了这些操作
public void saveUser(@RequestBody UserFormDTO userDTO){
//由于只需要传入一个参数,用save即可
//此时还要把dto转为po来保存
BeanUtils.copyProperties(userDTO,User.class);
userService.save(userDTO);
}@ApiOperation("删除用户接口") @DeleteMapping("{id}") public void deleteUser(@PathVariable("id") Long id ){ userService.removeById(id); }@ApiOperation("删除用户接口") @DeleteMapping("{id}") public void queryUserById(@ApiParam("用户id") @PathVariable("id") Long id ){ User user= (User) userService.getById(id); return BeanUtils.copyProperties(user, UserVO.class); }
2.复杂类型的接口实现
我们如果要实现复杂类型的接口,如以下代码,mp提供的方法不足以实现我们的需求,需要自定义Service来处理不同情况的输出
然后用baseMapper自定义注解
Controller
@ApiOperation("扣减用户金额接口")
@PutMapping("/{id}/deduction/{money}")
public void deductMoneyById(@ApiParam("用户id") @PathVariable("id") Long id,@ApiParam("扣减金额") @PathVariable Integer money)
{
userService.deductBalance(id,money);
}Service
public interface IUserService extends IService<User> {
void deductBalance(Long id, Integer money);
}ServiceImp
@Service
public class UserServiceImpl extends ServiceImpl<UserMapper,User> implements IUserService{
@Override
public void deductBalance(Long id, Integer money) {
//由于ServiceImpl里已经注入mapper了,所以直接用mapper也可以
//1.查询用户
User user=getById(id);
//2.检验用状态
if(user==null||user.getStatus()==2){
throw new RuntimeException("用户状态异常");
}
//3.检验用户余额是否充足
if(user.getBalance()<money){
throw new RuntimeException("用户余额不足");
}
//4.扣减余额
baseMapper.deductBalance(id,money);
}
}UserMapper
@Update("UPDATE mp.user SET balance=balance-#{money} Where id= #{id}")
void deductBalance(@Param("id") Long id,@Param("money") Integer money);
}3.Lambda查询

如果用传统的mybatis方法就需要复杂的xml的where,if判断语句
利用Lambda语法帮我们实现where查询
Controller
@ApiOperation("复杂条件查询接口")
@GetMapping("/List")
//接收变量太多,建议用对象来接收
public List<User> queryUsers(@RequestBody UserQuery query){
//1.查询用户PO
List<User> users=userService.queryUsers(query.getName(),query.getStatus(),query.getMinBalance(),query.getMaxBalance());
return users;
}Service
List<User> queryUsers(String name, Integer status, Intege){
}ServiceImpl
@Override
public List<User> queryUsers(String name, Integer status, Integer minBalance, Integer maxBalance) {
//直接使用lambda来构建条件
List<User> list= lambdaQuery()
.like(name!=null,User::getUsername,name)
.eq(status !=null,User::getStatus,status)
.ge(minBalance !=null,User::getBalance,minBalance)
.le(maxBalance!=null,User::getBalance,maxBalance)
//如果查询一个用one,多个用list,分页用page,计数用count等
.list();
return list;
}然后不需要我们编写复杂的语句,直接运行

4.IService批量新增


如上代码,每次提交都请求一次提交到数据库,过于浪费
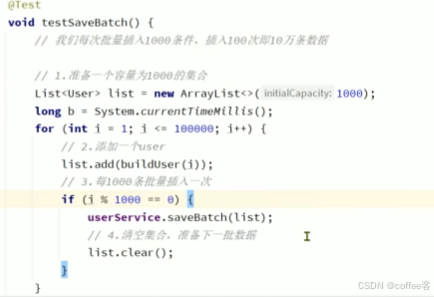
如代码所示,我们也是用for循环插入,逻辑是每达到1000条数据就存入一次,要花费100次
效率大大提高,但是我们可以利用IService一次性全部插入所有数据
for循环插入效率较低,一般我们用ISerivce批量插入,
3.扩展功能
3.1代码生成
我们要使用mp共有以下几个步骤
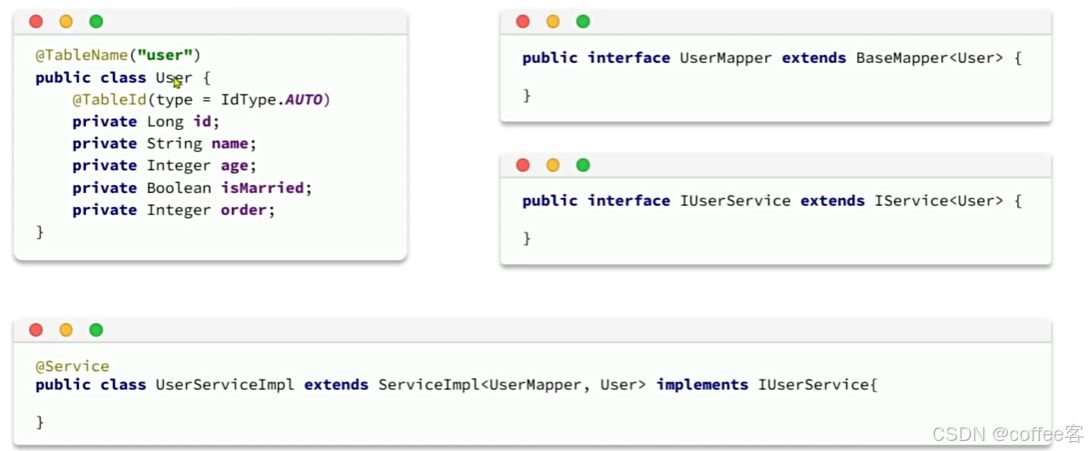
我们发现它们大部分代码都是固定的,不固定的是类名随我们的业务发生变化
我们可以通过代码生成来实现根据类名来修改Service,Controller,Mapper的名字
首先我们下载插件:
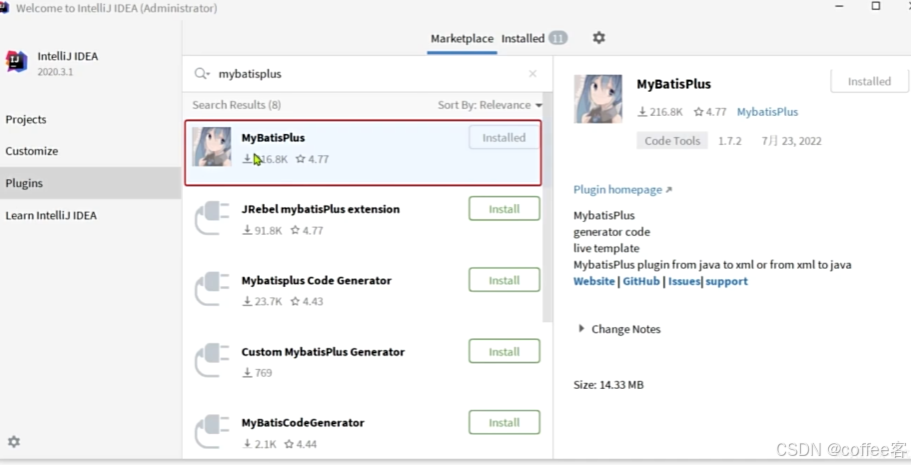
下载完成以后点击连接数据库

配置我们要连接的表
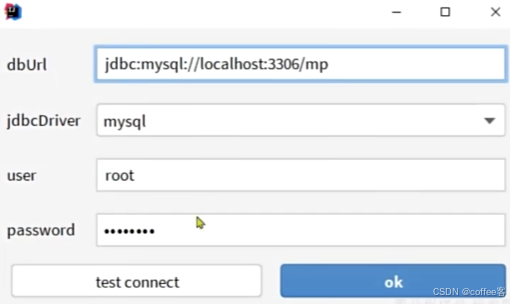
随后配置信息
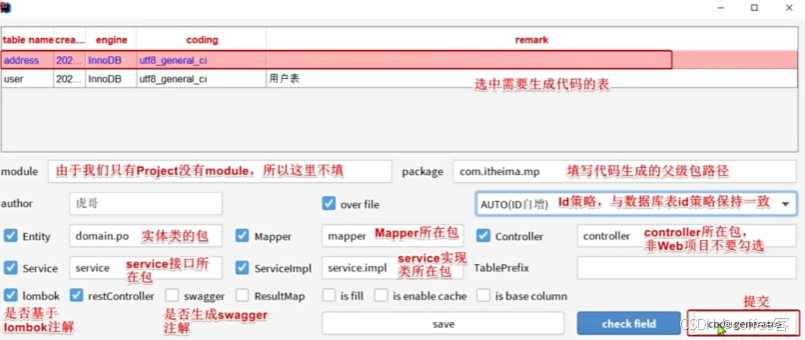
配置完成以后就可以生成我们表所需要的Pojo类,Mapper,.Service,ServiceImpl,Controller'
我们就可以根据业务来进行配置和编写所需代码了
3.2静态工具
静态工具类实现了很多类似IService的方法
由于静态工具都是静态的,在实现时和IService有些不同
如Service是非静态的,我们要自定义接口继承IService要指定泛型,而静态工具不需要
因为静态类无法读取到类型,所以不用指定泛型
但是有些要传入额外参数:如Class字节码。字节码就是我们实体类中的字节码,从而通过反射来得到实体类中的信息
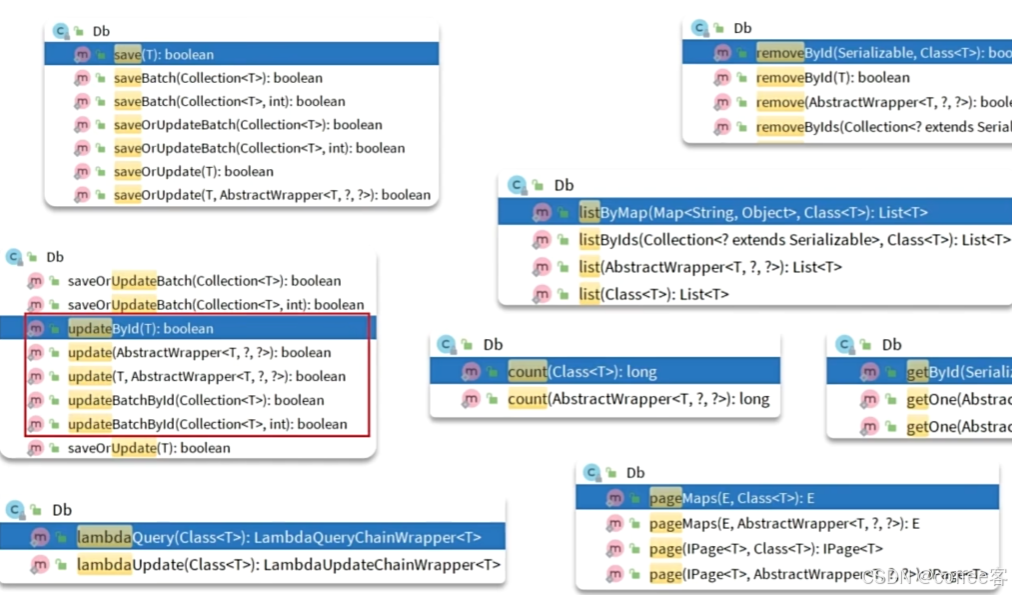
但是它们的区别是什么
有如下案例

因为我们要查询用户地址,用id来查找,在查找用户的同时也要查询地址,所以要在UserService里也要注入addressService,如第三个需求,我们需要查address的同时要查User,因此也要在addressService里注入userService,因此形成了循环依赖
我们在如userService要注入addressService时直接调用db静态工具来完成
现在我们用Db工具来代替IService实现类,如下定义的实现业务功能的方法
![]()

3.3.逻辑删除
-需要手动扩展
例如我们一个很重要的数据,如订单数据,未来我们要做一个数据统计
我们不能直接删除它
它们采用的就是逻辑删除



但是如update,等操作,因为我们实际上没有删除,但是update仍然可以进行更新,但是我们已经逻辑删除了,因此我们的增删改查的操作都会发生改变,要加上额外条件,但是mp没有提供这些功能,因此mp提供了拓展功能
在yml文件进行配置
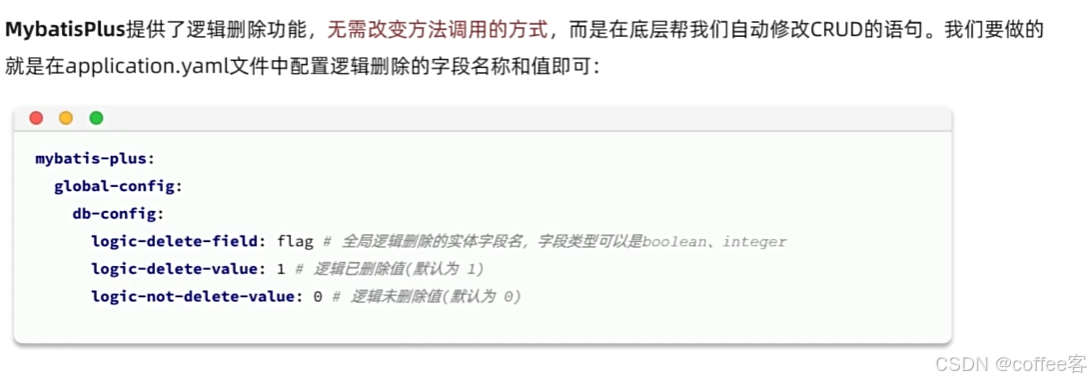
配置完成以后我们的操作就会根据需要逻辑删除的字段,其mp帮我们实现的方法也会根据逻辑字段判断来进行CRUD.如update,就会自动判断deleted的数值进行更新
但是不太推荐逻辑删除,因为数据并没有实际删除,而且SQL中要对逻辑删除的所有字段进行判断,都会影响查询效率,如果数据不能删除,可以把数据迁移到别的表
3.4枚举处理器
-需要手动扩展
如User类中有一个用户状态字段:
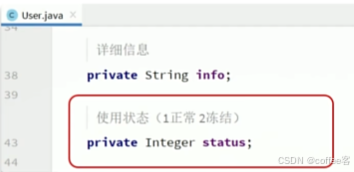
如图 ,如果一个类中有多种状态,每个状态对应的值我们很难记住 因此我们可以用枚举来进行表示
定义一个枚举类来储存状态和各种方法

然后我们类中的状态类型也要改变
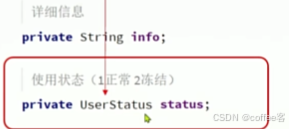
但是我们的数据库中状态类型任然是int类型

我们要将枚举类型转换成int类型,在业务中不光是枚举类型,很多类型都要进行转化
mybatis在后面帮我们完成了很多类型转换
mp也扩展了枚举的类型和json类型的处理器
类型转换处理器用法如下:
1.
我们要在进行类型转换的类下的成员变量用EnumValue来注解

这个时候在存入数据和读取数据的时候就知道这个变量是和数据库同名的变量是同一个2变量

2.配置我们所需要的枚举处理器

此时这两个变量就会自动进行类型转换了,我们不需要进行额外操作
我们使用这个枚举也会更加方便

通常程序返回的是我们的枚举名称,也就是英文名
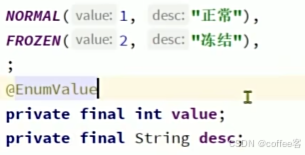
如果我们要返回value值或者是我们的字符串
就需要修改SpringMvc底层的返回的值
在要返回的数据变量加上注解@JsonValue,返回的枚举名就会显示是desc的字符串了
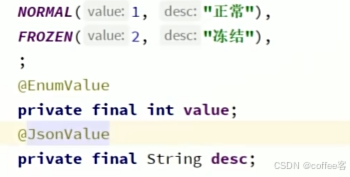
3.5Json处理器
和上面的处理器类似,就是用来处理Json转换的处理器
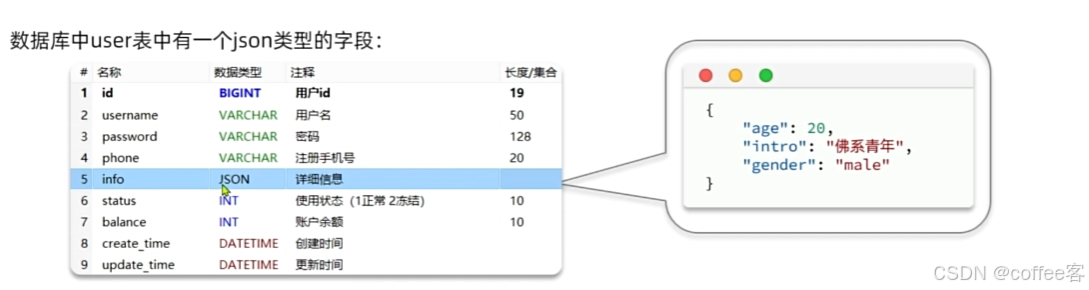
我们要将user表中的JSON格式转换成对象
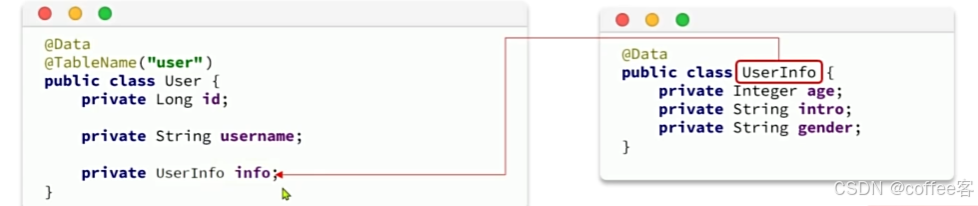
但是mybatis不能自动将对象和json数据进行转换
按理来说我们要自己进行转换,但是mp提供了这个处理器。
我们要在要进行转换的元素加入注解@TableField,这个处理器mp没有提供在application文件配置的方法,多个元素要分别加上这个注解,而且如图所示也出现了对象的嵌套,我们就要定义复杂的resultMap,如果我们不想定义resultMap就要在类上加入@TabelName注解
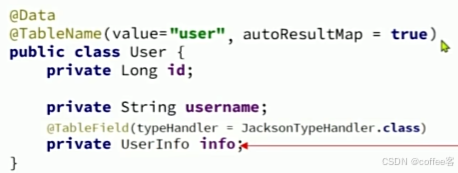
就可以帮我们实现对象和json数据的转换了
4.插件功能
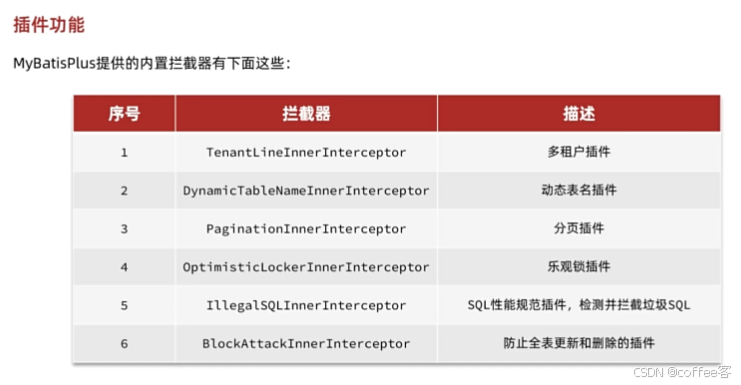
4.1分页插件
mp为我们提供了一个分页的插件
这个分页插件和PageHepler类似
1.配置插件
首先在配置类中注册MybatisPlus核心插件,同时添加分页插件
@Configuration
public class MyBatisConfig {
@Bean
public MybatisPlusInterceptor mybatisPlusInterceptor() {
MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();
//1,创建分页插件
PaginationInnerInterceptor paginationInnerInterceptor = new PaginationInnerInterceptor(DbType.MYSQL);
//设置查询最大上限
paginationInnerInterceptor.setMaxLimit(1000L);
//2.添加分页插件
interceptor.addInnerInterceptor(paginationInnerInterceptor);
return interceptor;
}
}例如overFlow方法,就是超过最大上限后就会返回到第一页,可以无限查询不会溢出
自定义一个配置类,注入到bean中,可以看到插件是基于拦截器来实现的
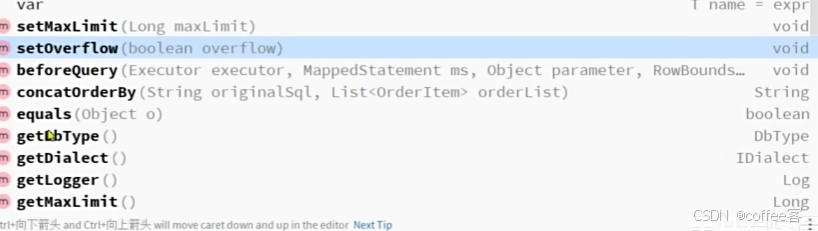
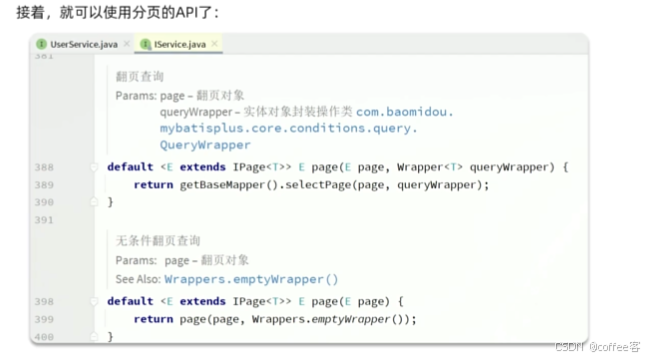
2.可以看到IService的IPage方法的逻辑是:
第二个参数是分页条件,第一个参数的泛型E和前面的E是一样的,代表IPage及其子类类型
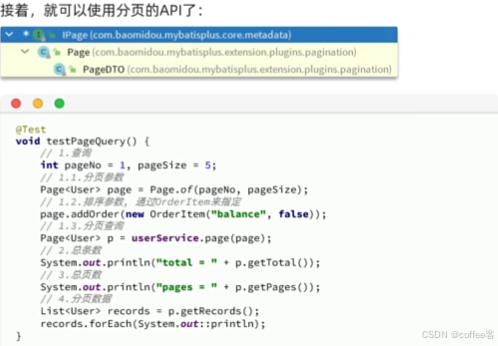
Ipage的子类如下

子类Page里包含的就是分页的参数:页码,分页大小,排序字段等
我们也可以看到这个方法的返回值也是E,因为Page里不仅仅包含分页参数,还包含了传出的分页结果,因此返回的也是Page
4.2通用分页实体
现在我们有一个案例

利用Ipage插件来对传入的json进行处理
传入的数据包括页数,数据量等
思想:一般我们先创建一个类来封装这些数据,作为查询条件,然后用UserVO来返回给前端,如果有给后端的就用UserDto来给后端
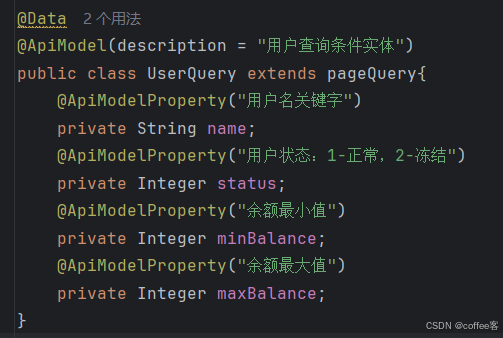
@Data @ApiModel(description = "用户查询条件实体") public class UserQuery {// @ApiModelProperty("页码") // private Integer pageNo; //单独写一个页码管理的类 @ApiModelProperty("用户名关键字") private String name; @ApiModelProperty("用户状态:1-正常,2-冻结") private Integer status; @ApiModelProperty("余额最小值") private Integer minBalance; @ApiModelProperty("余额最大值") private Integer maxBalance; }
按理来说我们要在这个类中添加分页参数,但是我们可以创建一个分页查询实体,我们所有的分页查询都可以用到这个类
我们要想用到分页实体里的参数就直接继承它就可以了
@ApiModel(description = "页码查询条件实体")
public class pageQuery {
@ApiModelProperty("页码")
private Integer pageNo;
@ApiModelProperty("页数")
private Integer pageSize;
@ApiModelProperty("排序字段")
private Integer pageBy;
@ApiModelProperty("是否升序")
private Integer isAsc;
}
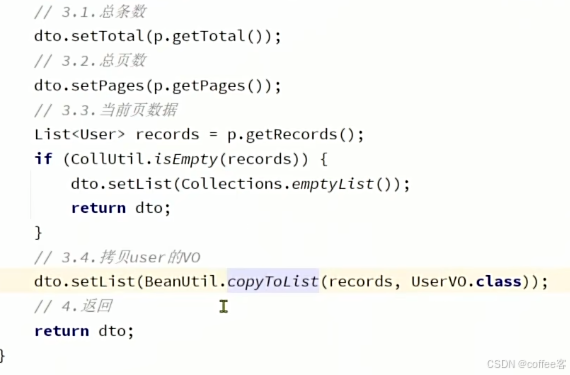
随后我们要创建一个分页结果实体类,是dto类型,这里的dto是返回给前端数据封装的实体类

然后我们就可以在controller里使用了

随后定义service方法进行处理

好了以上就是mybatisPlus的一个学习总结,mybatisPlus的强大之处远远不止于此,我这里只做一个简单的入门,后续可以根据我们需要进行扩展,好了感谢大家的观看,谢谢大家 :)

















 323
323

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









