







 茴香豆,起初作为微信群的技术问题AI,现已发布Web版,支持创建知识库、更新正反例和集成微信、飞书。该工具在实战经验中不断优化,具备拒答、搜索增强等群聊特性和PDF处理能力。
茴香豆,起初作为微信群的技术问题AI,现已发布Web版,支持创建知识库、更新正反例和集成微信、飞书。该工具在实战经验中不断优化,具备拒答、搜索增强等群聊特性和PDF处理能力。

茴香豆最初是微信群解答技术问题的 AI 助手,我们在 2023 年 4 月发布的文章 LLaMa 和 RWKV 结构对比 中曾经介绍过。一年后回头再看, 当初提到的 Long Context、text2vec 和 GPU 效率问题,现在均已解决或明显改善。
现在我们发布茴香豆 web 版,大家可以创建自己的知识库、更新正反例、开关搜索,最后接入微信或飞书群。
https://openxlab.org.cn/apps/detail/tpoisonooo/huixiangdou-web
茴香豆目前已经开源在 InternLM 项目下,欢迎体验:
https://github.com/InternLM/HuixiangDou
茴香豆 web 版链接,文末点击阅读原文可直达,欢迎体验:
https://openxlab.org.cn/apps/detail/tpoisonooo/huixiangdou-web
现在 GitHub 上已经有不少类似的优秀项目,我们的优势在于实战经验丰富:
-
说 RAG 只是方便宣传。为了应对群聊场景,衍生出拒答、搜索增强、scoring、长文本、安全需求,远不止 RAG 概念
-
在多个群聊中运行超半年。例如豆哥解析 pdf 能处理表格,不似
langchain只提取正文文本
接下来,就向大家介绍如何使用茴香豆 web 版~
视频介绍:
LLM问答助手茴香豆发布web版,零开发集成微信&飞书群
https://www.bilibili.com/video/BV1S2421N7mn/
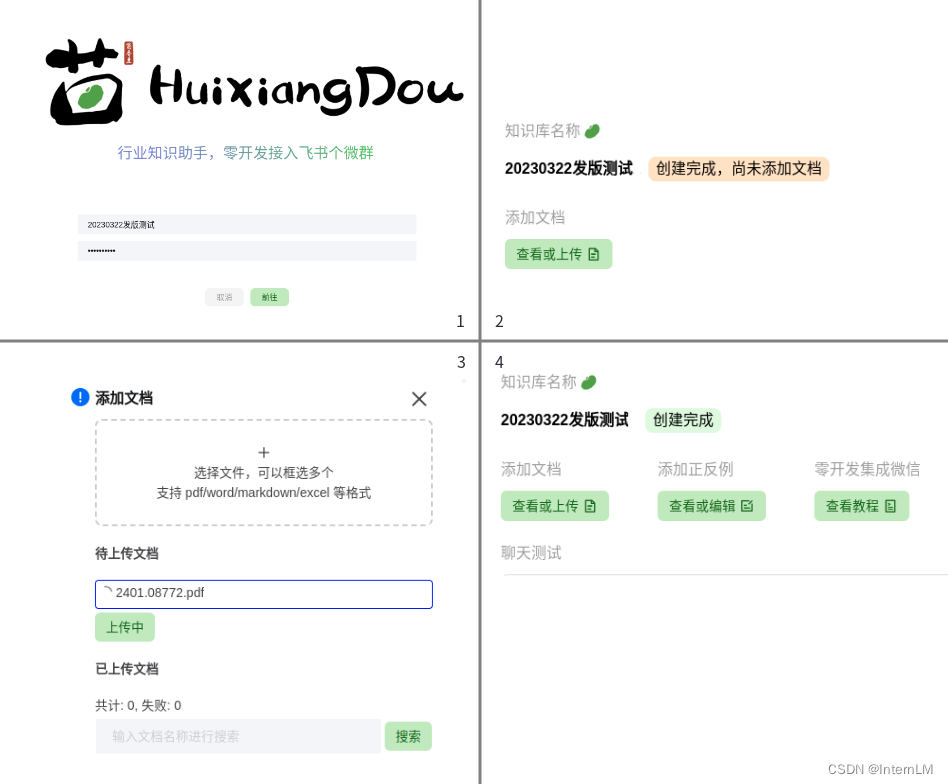
一、创建知识库
首先打开茴香豆 web 版(https://openxlab.org.cn/apps/detail/tpoisonooo/huixiangdou-web),设置知识库名称及密码,初次创建还不能开启聊天,必须添加文档完成知识库创建。
选择自己的文档,例如“2401.08772.pdf”,点击“上传”;创建成功后,即可解锁聊天、集成微信/飞书等功能。
可以直接输入以下账号密码体验已经创建好的知识库,开启聊天。
名称:20230322发版测试
密码:123
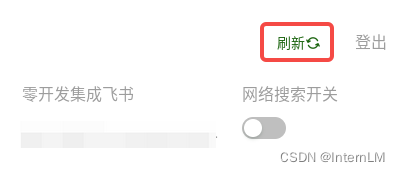
由于带宽和 GPU 有限,如果一直无法聊天测试,可以点右侧 “刷新” 按钮,主动更新当前状态。
二、聊天测试
拒答能力在群聊里是刚需,如果输入闲聊,它会标注出 “query is not a question”。
下面是我们基于内部数百个文档和真实问题的测试结果,它回复时会给出文档出处,如果它表现还不错、或者不满意,请点击对话框右上角给个反馈~
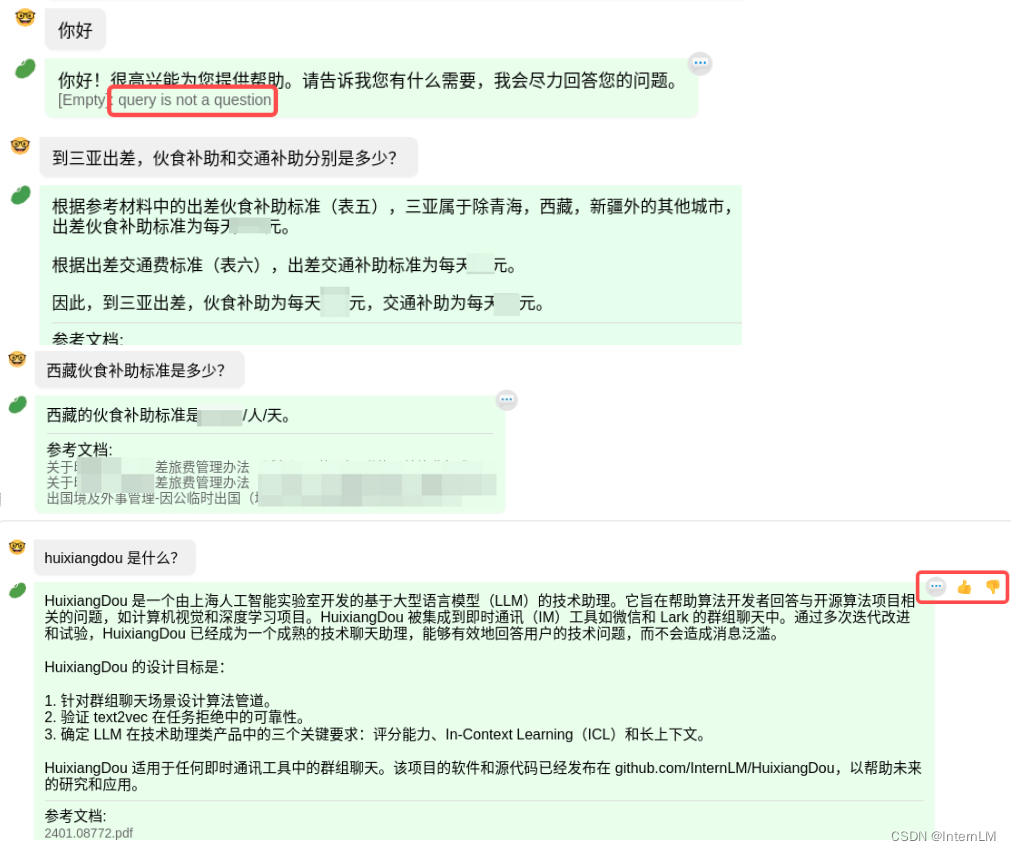
如遇敏感话题,豆哥也会及时装傻。

三、集成微信、飞书群
点击 “零开发集成微信”,我们提供了预编译 android APP 和指导教程,协助用户零编程集成到微信群;同样可“零开发集成飞书”。
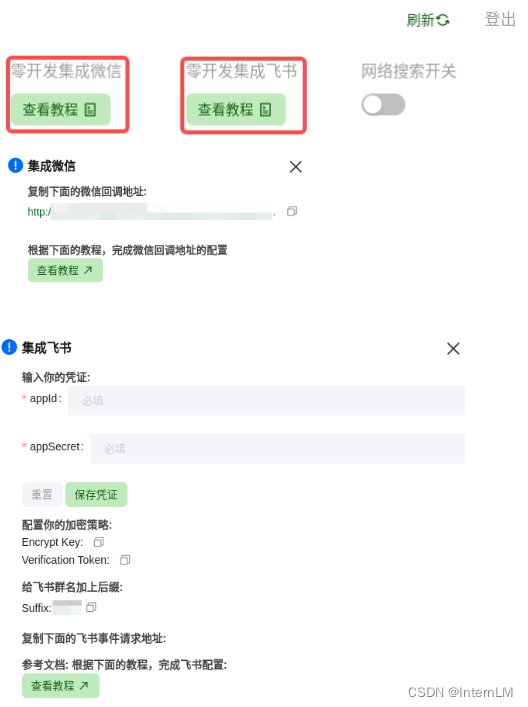
当然 web 版还有更多功能,欢迎大家多多体验~
如果对你有用的话,欢迎点个 star ~
https://github.com/InternLM/HuixiangDou

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









