






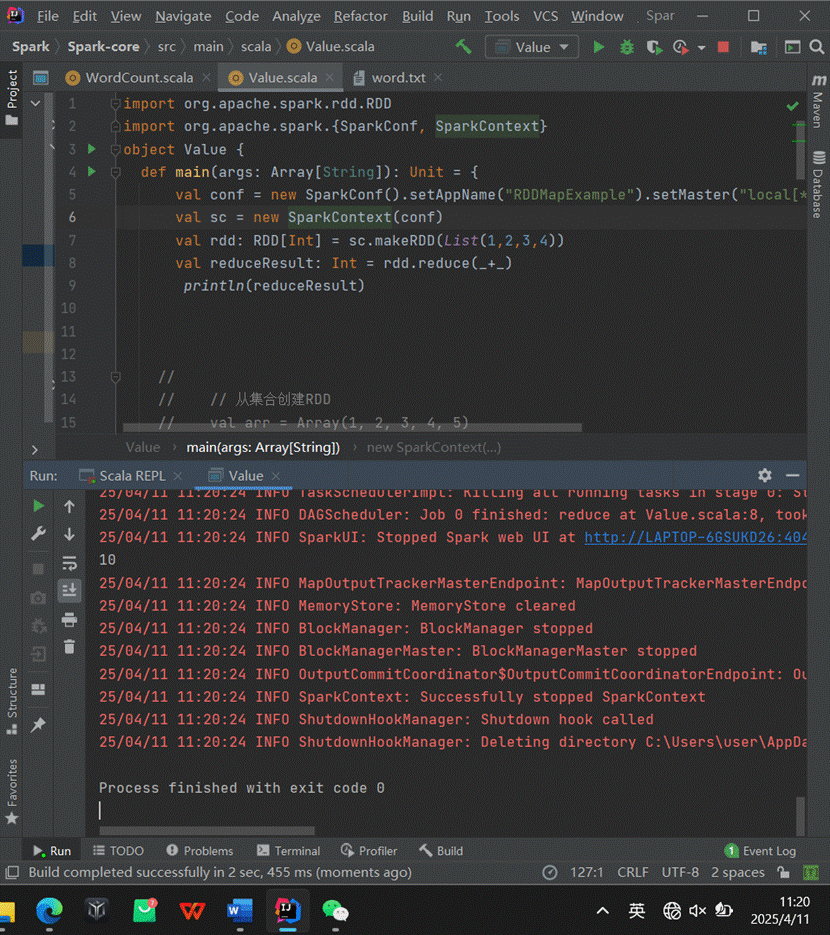
1.reduce
功能:聚集RDD中的所有元素,先聚合分区内数据,再聚合分区间数据。
示例:rdd.reduce(_+_) 将RDD中的所有整数相加。
2.collect
功能:在驱动程序中,以数组Array的形式返回数据集的所有元素。
示例:rdd.collect() 返回RDD中所有元素的数组。
3.foreach
功能:分布式遍历RDD中的每一个元素,调用指定函数。
示例:rdd.collect().foreach(println) 先收集RDD元素,然后逐个打印。
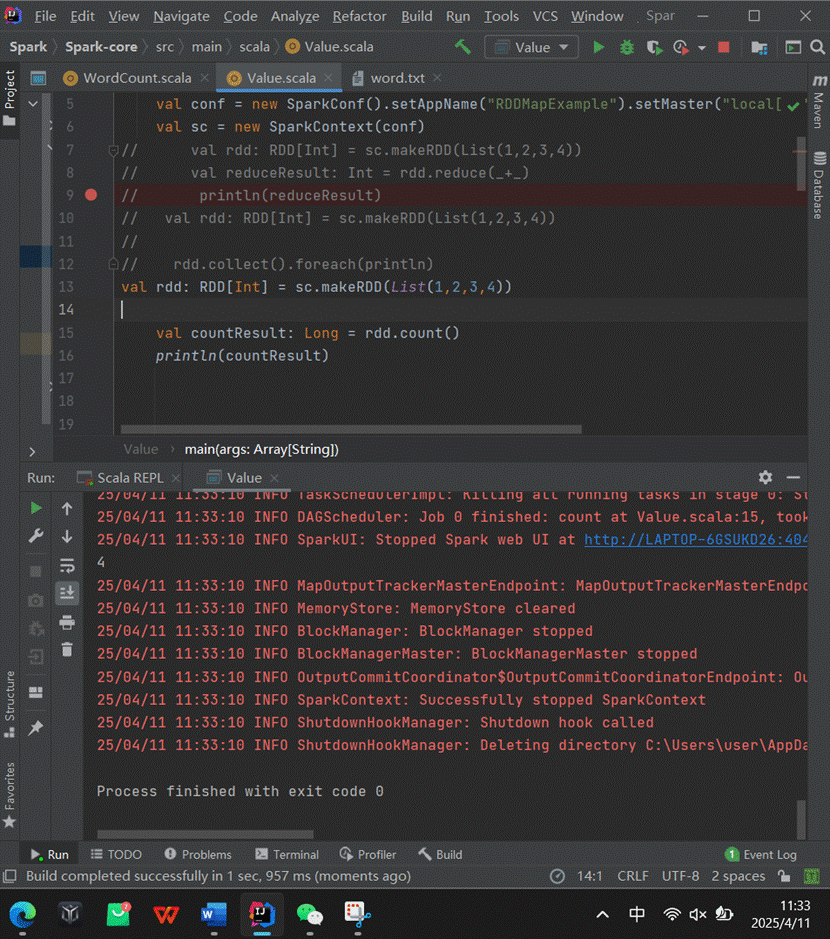
4.count
功能:返回RDD中元素的个数。
示例:rdd.count() 返回RDD中的元素数量。
5.first
功能:返回RDD中的第一个元素。
示例:rdd.first() 返回RDD中的第一个元素。
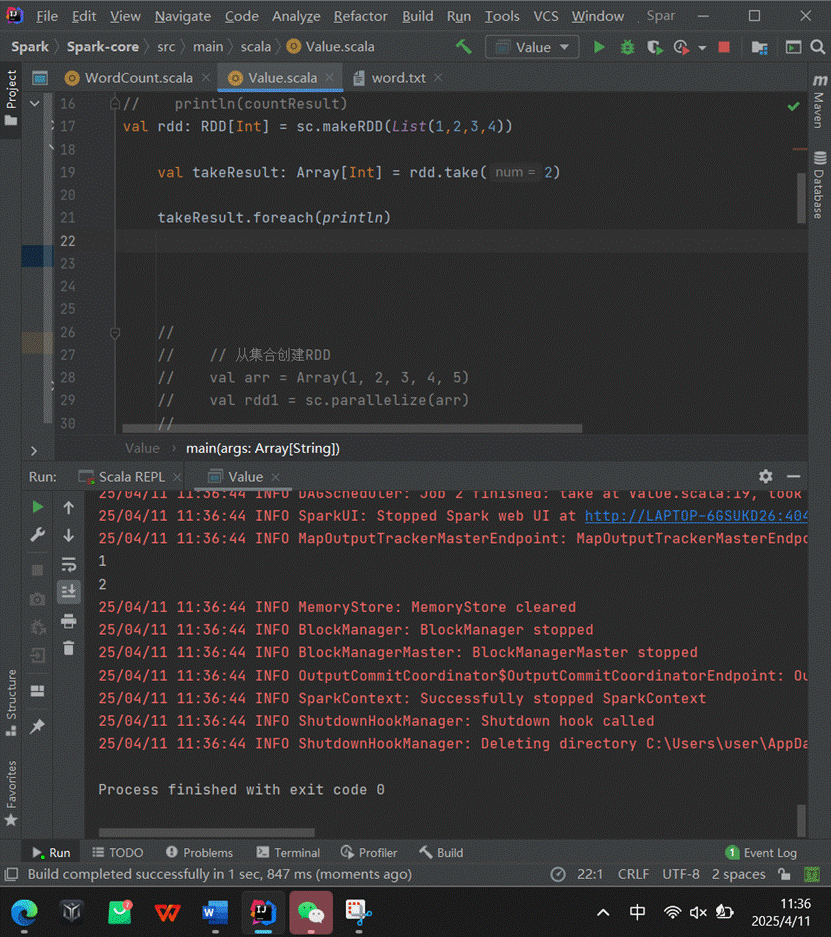
6.take
功能:返回一个由RDD的前n个元素组成的数组。
示例:rdd.take(2) 返回RDD中的前两个元素组成的数组。
7.takeOrdered
功能:返回RDD排序后的前n个元素组成的数组。
示例:rdd.takeOrdered(2) 返回RDD中排序后的前两个元素。
8.aggregate
功能:分区的数据通过初始值和分区内的数据进行聚合,然后再和初始值进行分区间的数据聚合。
示例:rdd.aggregate(0)(_+_, _+_) 将RDD的所有元素相加。
9.fold
功能:折叠操作,aggregate的简化版操作。
示例:rdd.fold(0)(_+_) 将RDD的所有元素相加,与aggregate的示例类似但更简洁。
10.countByKey
功能:统计每种key的个数,适用于RDD[(K, V)]类型。
示例:rdd.countByKey() 统计每种key出现的次数。
11.save相关算子
功能:将数据保存到不同格式的文件中,包括文本文件、对象文件和序列文件。
示例:
rdd.saveAsTextFile("path") 保存为文本文件。rdd.saveAsObjectFile("path") 保存为对象文件。
rdd.saveAsSequenceFile("path") 保存为序列文件(了解即可)。
12.累加器(Accumulator)
实现原理:
累加器用于把Executor端的变量信息聚合到Driver端。在Driver程序中定义的变量,在Executor端的每个Task都会得到这个变量的一份新的副本。每个Task更新这些副本的值后,传回Driver端进行merge操作。
常用方法:
sparkContext.longAccumulator(name: String): 创建一个长整型累加器。
sparkContext.doubleAccumulator(name: String): 创建一个双精度浮点型累加器。
自定义累加器:通过继承AccumulatorV2类,实现自定义的累加逻辑。
13.广播变量(Broadcast Variable)
实现原理:
广播变量用于高效分发较大的只读对象。它向所有工作节点发送一个较大的只读值,以供一个或多个Spark操作使用。Spark会为每个任务分别发送该变量,但在多个并行操作中可以共享同一个广播变量,从而提高效率。
常用方法:
sparkContext.broadcastT](value: T): 创建一个广播变量。
总结:
累加器适用于在分布式计算过程中聚合数据,如统计和、最大值、最小值等。
广播变量适用于在多个任务之间共享大对象,以减少数据传输开销,提高计算效率。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









