







加粗为更新/新增数据
- [大数据平台] 2023-06-03 日业务人员在大数据平台中查看2023-06-02日用户表的历史数据,期望数据如下:
| id | name | phone | gender | create_time | update_time |
|---|---|---|---|---|---|
| 1 | jack | 111 | 男 | 2023-06-01 13:00:00 | 2023-06-01 13:00:00 |
| 2 | jason | 222 | 男 | 2023-06-01 13:00:00 | 2023-06-01 13:00:00 |
| 3 | tom | 333 | 男 | 2023-06-01 13:00:00 | 2023-06-01 13:00:00 |
看到这里,有些同学可能会疑惑为何不采用离线数仓中的快照表,而要选择使用 Flink 实时同步的方式。确实,从需求层面看,离线数仓的快照表似乎是一种合理的选择。然而,我们需要注意离线数仓通常采用凌晨 T+1 执行 SQL 的方式将业务数据筛选后同步至下游,这种操作适用于对业务数据精确度要求不高的场景。
对于对数据精确度要求较高的需求,采用 T+1 的同步方式可能会导致数据不一致的问题。详细的问题分析和解决方案可以参考我另一篇文章:深入数仓离线数据同步:问题分析与优化措施。
那么对于对数据精确度要求较高的场景,我们可以选择实时同步的方式来实现。这是因为实时同步通过读取 binlog 日志,能够获取业务数据的完整变更历史。与离线数仓中的 T+1 执行 SQL 不同,实时同步能够更及时地捕获和应用数据变更,确保数据的高一致性和精确度。
二、技术选型
在实时同步领域,要实现背景中的需求通常有两种常见的解决方式:
- 实时同步 + 拉链表:
- 拉链表完整记录了整个 binlog 的数据流向,并通过
start_date和end_date字段进行天粒度筛选。 - 可以采用此方式,实现细节可以参考笔者另一篇文章:Flink实时数仓同步:拉链表实战详解。
- 拉链表完整记录了整个 binlog 的数据流向,并通过
- 实时同步 + 快照表:
- 本文主要内容。
- 快照表适用于对数据的历史状态感兴趣,通过实时同步捕获变更事件,并将精确数据写入快照表。
本文主要介绍第二种实现方式:实时同步 + 快照表。
三、技术架构
鉴于业务数据通常存储在关系型数据库中,这里选择采用Flink-CDC持续读取binlog日志进行实时同步。为了保证实时数据能够高效写入下游并支持用户OLAP查询分析,这里选择了企业中常见的MMP库Doris作为实时数仓的存储层。整体架构如下图所示:
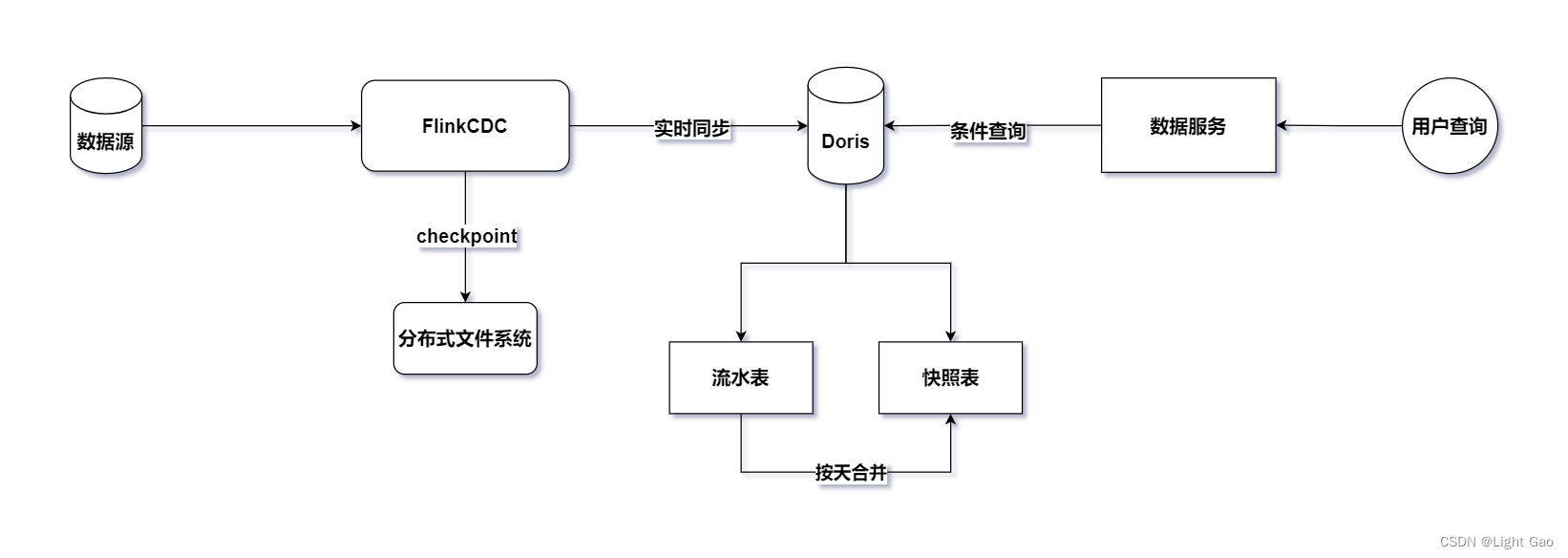
基于上图的设计,引入了一张额外的流水表到 Doris 中。这个设计的目的是为了实现业务的解耦,建立一张专门存储业务数据表的历史变更记录的流水表。这种结构不仅有助于满足当前需求,而且在后续可能出现的其他需求中也更加灵活可扩展。
在实际实现中,可以通过一个 Flink 程序来构建这两张表:流水表和快照表。这种设计模式使得系统更为模块化,同时也方便了后期其他需求的使用。
因此建议读者先阅读笔者另一篇文章:Flink实时数仓同步:流水表实战详解;再回到本文。这样能够更好地理解整个系统设计的背景和实际应用。
四、数据流转过程
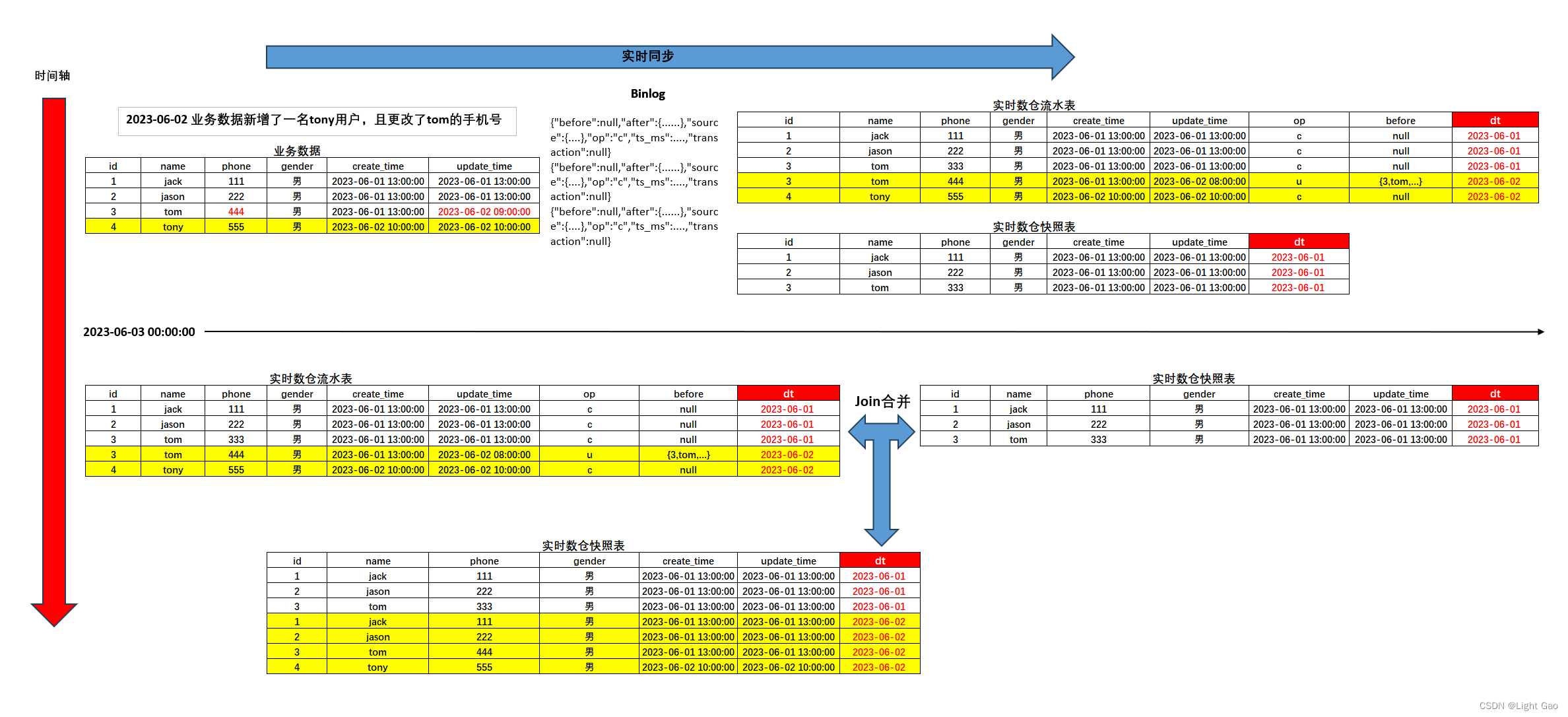
Flink实时同步程序负责处理捕获到的MySQL数据变更事件。在处理流程中,首先将全量数据存储到快照表,然后针对新增(INSERT)、修改(UPDATE)、删除(DELETE)等操作,将其同步至流水表。当符合以下任意一个条件便会触发合并任务:
- 当binlog数据中的日期为第二天。
- 凌晨过了5分钟 [自定义阈值]。
一旦触发合并任务,程序将执行JOIN操作,将流水表前一天数据与快照表中前两天的数据进行整合,最终得到前一天的全量数据,并将其写入至快照表的前一天分区中。这种设计模式既保证了数据的完整性和准确性,又有效地将全量数据存储于快照表中,数据流转过程如下图所示:
五、实时同步+快照表实现
5.1、快照表设计
- 快照表用于存储某个特定时间点的所有数据,通常以天为粒度,相当于对每天的业务数据进行一次全量快照,将当天的全部数据记录下来。举例来说,12号分区中的数据包含了从历史开始一直到11号的全部数据,而13号分区中的数据则包含了从历史一直到12号的全部数据,其余分区以此类推。
- 此处只介绍快照表的设计,关于流水表的建表语句请参考笔者另一篇文章:Flink实时数仓同步:流水表实战详解,此快照表采用了Unique数据模型,建表语句如下:
CREATE TABLE `example\_user\_snapshot`
(
`id` largeint(40) NOT NULL COMMENT '用户id',
`dt` date NULL COMMENT '流水日期',
`name` varchar(50) NOT NULL COMMENT '用户昵称',
`phone` largeint(40) NULL COMMENT '手机号',
`gender` varchar(5) NULL COMMENT '用户性别',
`create\_time` datetime NULL COMMENT '用户注册时间',
`update\_time` datetime NULL COMMENT '用户更新时间'
) ENGINE=OLAP
UNIQUE KEY(`id`, `dt`)
COMMENT '用户快照表'
PARTITION BY RANGE(dt)()
DISTRIBUTED BY HASH(id) BUCKETS 8
PROPERTIES
(
"dynamic\_partition.enable" = "true",
"dynamic\_partition.ti 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









