






一.数据类型
1.列表
假设有一个由数字组成的 list,现在需要把其中的偶数项取出来,组成一个新的 list。一种比较“正常”的方法是:
list_1 = [1, 2, 3, 5, 8, 13, 22] list_2 = [] for i in list_1: if i % 2 == 0: list_2.append(i) print (list_2)
输出
[2, 8, 22]
此方法通过循环来遍历列表,对其中的每一个元素进行判断,若模取2的结果为0则添加至新列表中。
使用列表解析实现同样的效果:
list_1 = [1, 2, 3, 5, 8, 13, 22] list_2 = [i for i in list_1 if i % 2 == 0] print (list_2)
输出
[2, 8, 22]
[i for i in list_1] 会把 list_1 中的每一个元素都取出来,构成一个新的列表。
如果需要对其中的元素进行筛选,就在后面加上判断条件 if。所以 [i for i in list_1 if i % 2 == 0] 就是把 list_1 中满足 i % 2 == 0 的元素取出来组成新列表。
进一步的,在构建新列表时,还可以对于取出的元素做操作。比如,对于原列表中的偶数项,取出后要除以2,则可以通过 [i / 2 for i in list_1 if i % 2 == 0] 来实现。输出为 [1, 4, 11]。
在实际开发中,适当地使用列表解析可以让代码更加简洁、易读,降低出错的可能。
2.字典
字典这种数据结构有点像我们平常用的通讯录,有一个名字和这个名字对应的信息。在字典中,名字叫做“键”,对应的内容信息叫做“值”。字典就是一个键/值对的集合。
它的基本格式是(key是键,value是值):
d = {key1 : value1, key2 : value2}
键/值对用冒号分割,每个对之间用逗号分割,整个字典包括在花括号中。
关于字典的键要注意的是:
1.键必须是唯一的;
2.键只能是简单对象,比如字符串、整数、浮点数、bool值。
list就不能作为键,但是可以作为值。
举个简单的字典例子:
score = {
'萧峰': 95,
'段誉': 97,
'虚竹': 89
}
python字典中的键/值对没有顺序,我们无法用索引访问字典中的某一项,而是要用键来访问。
print (score['段誉'])
注意,如果你的键是字符串,通过键访问的时候就需要加引号,如果是数字作为键则不用。
如果你提供的键在字典中不存在,则会报错。另一种访问字典中元素的方法是:
score.get('慕容复')
这种方法的好处是,即使提供的键不存在,也不会报错,只会返回 None
字典也可以通过for...in遍历:
for name in score: print (score[name])
注意,遍历的变量中存储的是字典的键。
如果要改变某一项的值,就直接给这一项赋值:
score['虚竹'] = 91
增加一项字典项的方法是,给一个新键赋值:
score['慕容复'] = 88
删除一项字典项的方法是del:
del score['萧峰']
注意,这个键必须已存在于字典中。
如果你想新建一个空的字典,只需要:
d = {}
3.元组
元组(tuple)也是一种序列,和我们用了很多次的list类似,只是元组中的元素在创建之后就不能被修改。
如:
postion = (1, 2)
geeks = ('Sheldon', 'Leonard', 'Rajesh', 'Howard')
都是元组的实例。它有和list同样的索引、切片、遍历等操作(参见25~27课):
print (postion[0]) for g in geeks: print (g) print (geeks[1:3])
其实我们之前一直在用元组,就是在print语句中:
print ('%s is %d years old' % ('Mike', 23))
('Mike', 23)就是一个元组。这是元组最常见的用处。
再来看一下元组作为函数返回值的例子:
def get_pos(n): return (n/2, n*2)
得到这个函数的返回值有两种形式,一种是根据返回值元组中元素的个数提供变量:
x, y = get_pos(50) print (x) print (y)
这就是我们在开头那句代码中使用的方式。
还有一种方法是用一个变量记录返回的元组:
pos = get_pos(50) print (pos[0]) print (pos[1])
二.控制流
1.条件语句
if-else-elif
if,是:“如果”条件满足,就做xxx,否则就不做。
else 顾名思义,就是:“否则”就做yyy。
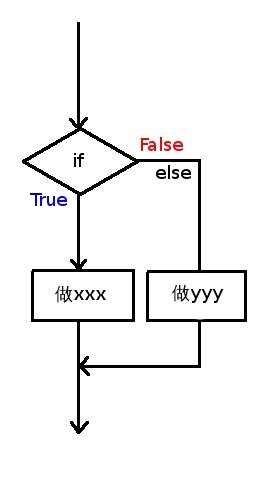
当if后面的条件语句不满足时,与之相对应的 else 中的代码块将被执行。
if a == 1:
print('right')
else:
print('wrong')
elif 意为 else if,含义就是:“否则如果”条件满足,就做yyy。elif 后面需要有一个逻辑判断语句。
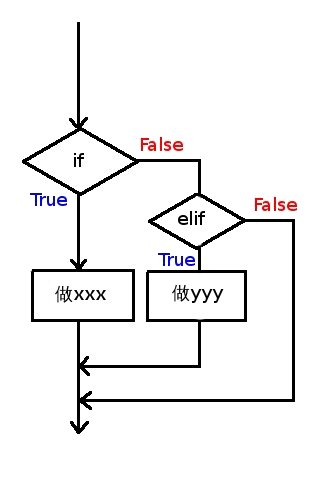
当if条件不满足时,再去判断 elif 的条件,如果满足则执行其中的代码块:
if a == 1:
print ('one')
elif a == 2:
print ('two')
if, elif, else 可组成一个整体的条件语句。
-
if 是必须有的;
-
elif 可以没有,也可以有很多个,每个elif条件不满足时会进入下一个elif判断;一旦满足,执行完就结束整个条件语句;
-
else 可以没有,如果有的话只能有一个,必须在条件语句的最后。
if的嵌套
和 for 循环一样,if 也可以嵌套使用,即在一个 if/elif/else 的内部,再使用 if。这有点类似于电路的串联。
if 条件1: if 条件2: 语句1 else: 语句2 else: if 条件2: 语句3 else: 语句4
在上面这个两层if的结构中,当:
条件1为True,条件2为True时,
执行语句1;
条件1为True,条件2为False时,
执行语句2;
条件1为False,条件2为True时,
执行语句3;
条件1为False,条件2为False时,
执行语句4。
假设需要这样一个程序:
我们先向程序输入一个值x,再输入一个值y。(x,y)表示一个点的坐标。程序要告诉我们这个点处在坐标系的哪一个象限。
x>=0,y>=0,则输出1;
x<0,y>=0,则输出2;
x<0,y<0,则输出3;
x>=0,y<0,则输出4。
你可以分别写4个if,也可以用if的嵌套:
if y >= 0: if x >= 0: print (1) else: print (2) else: if x < 0: print (3) else: print (4)
2.循环
while语句
同 if 一样,while 也是一种控制流语句,另外它也被称作循环语句。
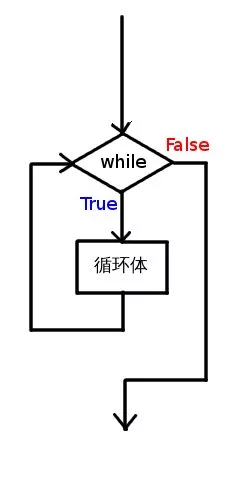
while,英文翻译过来就是“当...的时候”。
程序执行到 while 处,“当”条件为 True 时,就去执行 while 内部的代码;“当”条件为 False 时,就跳过。
语法为:
while 条件: 循环执行的语句
同 if 一样,注意冒号,注意缩进。
栗子:
# coding: gbk
a = 1 # 为了后面的条件能满足,先把a设为1
while a != 0: # 如果a不等于0就循环(1不等于0)
print("please input")
a = int(input()) # 在循环内部获取输入,改变a的值(想想看不改会怎样?)
print("over")
程序执行后,会不断向你询问输入,直到你输入0,条件 a!=0 不满足,循环结束。
for循环
同 while 一样,for 循环可以用来重复做一件事情。在某些场景下,它比 while 更好用。
比如之前的一道习题:输出1到100(公众号中的练习题3)。
我们用while来做,需要有一个值来记录已经做了多少次,还需要在 while 后面判断是不是到了100。
如果用for循环,则可以这么写:
for i in range(1, 101): print(i)
解释一下,range(1, 101) 表示从1开始,到101为止(不包括101,注意这里和 randint 不一样),取其中所有的整数。
for i in range(1, 101) 就是说,把这些数,依次赋值给变量i。
相当于一个一个循环过去,第一次 i = 1,第二次 i = 2,……,直到 i = 100。当 i = 101 时跳出循环。
所以,当你需要一个循环10次的循环,你就只需要写:
for i in range(1, 11)
或者
for i in range(0, 10)
区别在于前者i是从1到10,后者 i 是从0到9。当然,你也可以不用 i 这个变量名,换成其他合法的变量名也可以。
比如一个循环n次的循环:
for count in range(0, n)
for 循环的本质是对一个序列中的元素进行遍历。什么是序列,以后再说。先记住这个最简单的形式:
for i in range(a, b)
就是从 a 循环至 b-1
三.函数与类
1.函数
以 range(1,10) 为例,range 是这个函数的名称,后面括号里的1和10是 range 需要的参数。它有返回结果,就是一个从1到9的序列生成器(暂时你可以理解为,就是1~9九个数字)。
再来看 input(),括号里面什么都没有,表示我们没有给参数。函数执行过程中,需要我们从控制台输入一个值。函数的返回结果就是我们输入的内容。
PS:range 还可以接受1个或3个参数,input也可以接受1个字符串参数。可以等我之后几课来讲,或者尝试在网上搜索下“python range 参数”。
如果我们要自己写一个函数,就需要去 定义 它。python里的关键字叫 def(define的缩写),格式如下:
def sayHello():
print ('hello world!')
sayHello 是这个函数的名字,后面的括号里是参数,这里没有,表示不需要参数。但括号和后面的冒号都不能少。下面缩进的代码块就是整个函数的内容,称作函数体。
然后我们去调用这个函数,就是用函数名加上括号,有必要的话,括号里放参数:
sayHello()
得到和直接执行print ('hello world!')一样的结果。
2.命令行常用命令
打开命令行,我们会看到每行前面都有诸如
C:\Documents and Settings\Crossin>
或者
MyMacBook:~ crossin$
之类的。
这个提示符表示了当前命令行所在目录。
在这里,我们输入 python 并敲下回车,就可以进入python环境了。但今天我们暂时不这么做。
第一个常用的命令是:
dir (windows环境下)
ls (mac环境下)
dir 和 ls 的作用差不多,都是显示出当前目录下的文件和文件夹。
具体效果可参见文末的附图。
第二个常用命令是:
cd 目录名
通过 dir 或 ls 了解当前目录的结构之后,可以通过“cd 目录名”的方式,进入到当前目录下的子目录里。
如果要跳回到上级目录,可以用命令:
cd ..
另外,Windows下如果要写换盘符,需要输入
盘符:
比如从c盘切换到d盘
C:\Documents and Settings\Crossin> d:
有了以上两个命令,就可以在文件目录的迷宫里游荡了。虽然没可视化的目录下的操作那么直观,但是会显得你更像个程序员。。。
于是乎,再说个高阶玩法:现在你可以不用 idle 那套东西了,随便找个顺手的文本软件,把你的代码写好,保存好,最好是保存成 py 文件。
然后在命令行下,通过使用 cd 命令进入到 py 文件保存的目录,再执行命令:
python 代码的文件名
就可以运行你写的程序了。
演示如下:
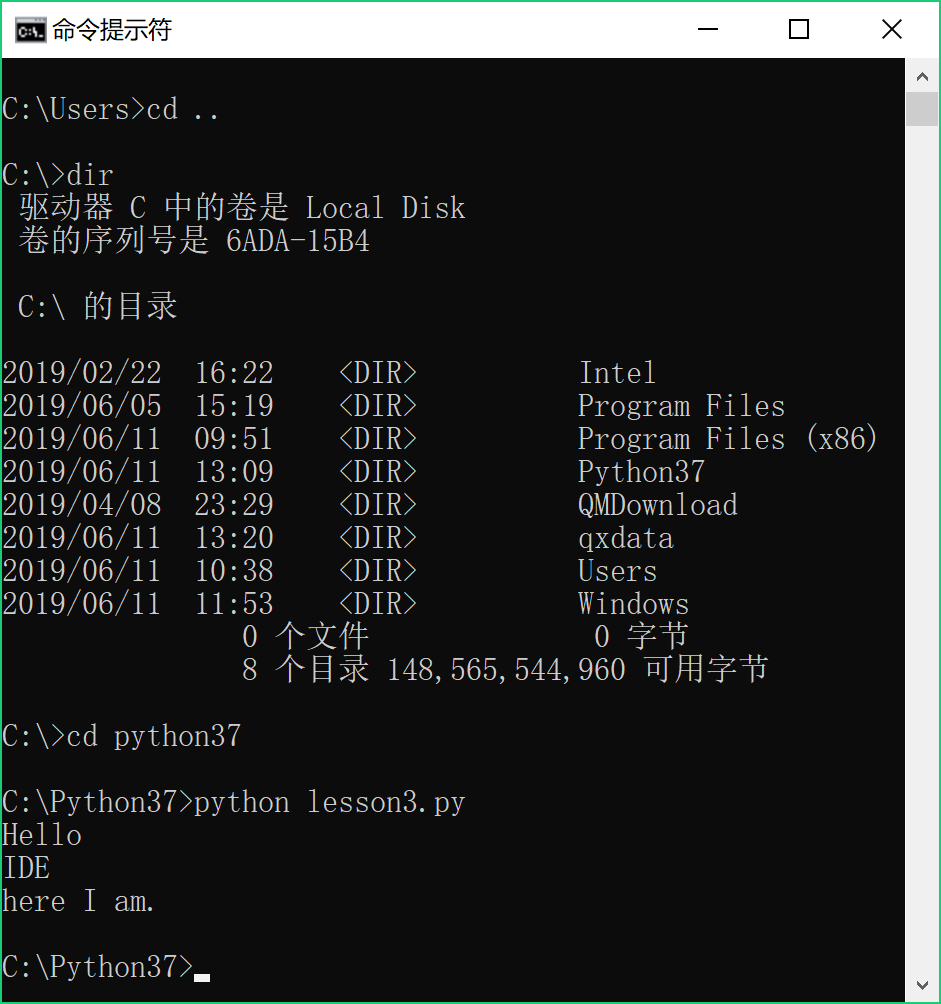
嗯,这才像个python程序员的样!
注意:如果执行 python 命令时提示“不是内部或外部命令”,那么说明你的环境变量没有设置好。请参考 1.安装 课中最后一点配置命令行里的几点注意进行检查。
其他常用命令,诸如 拷贝文件、删除文件、新建文件夹 之类的,请你自行在网上搜索相关资料。很容易的,比如你搜“mac 终端 常用命令”,就可以找到很多了。
3.函数的参数
如果我们希望自己定义的函数里允许调用者提供一些参数,就把这些参数写在括号里,如果有多个参数,用逗号隔开,如:
def sayHello(someone): print(someone + ' says Hello!')
或者
def plus(num1, num2): print(num1+num2)
参数在函数中相当于一个变量,而这个变量的值是在调用函数的时候被赋予的。在函数内部,你可以像过去使用变量一样使用它。
调用带参数的函数时,同样把需要传入的参数值放在括号中,用逗号隔开。要注意提供的参数值的数量和类型需要跟函数定义中的一致。如果这个函数不是你自己写的,你需要先了解它的参数类型,才能顺利调用它。
比如上面两个函数,我们可以直接传入值:
sayHello('Crossin')
还是注意,字符串类型的值不能少了引号。
或者也可以传入变量:
x = 3 y = 4 plus(x, y)
在这个函数被调用时,相当于做了num1=x, num2=y这么一件事。所以结果是输出了7。
4.函数应用试例
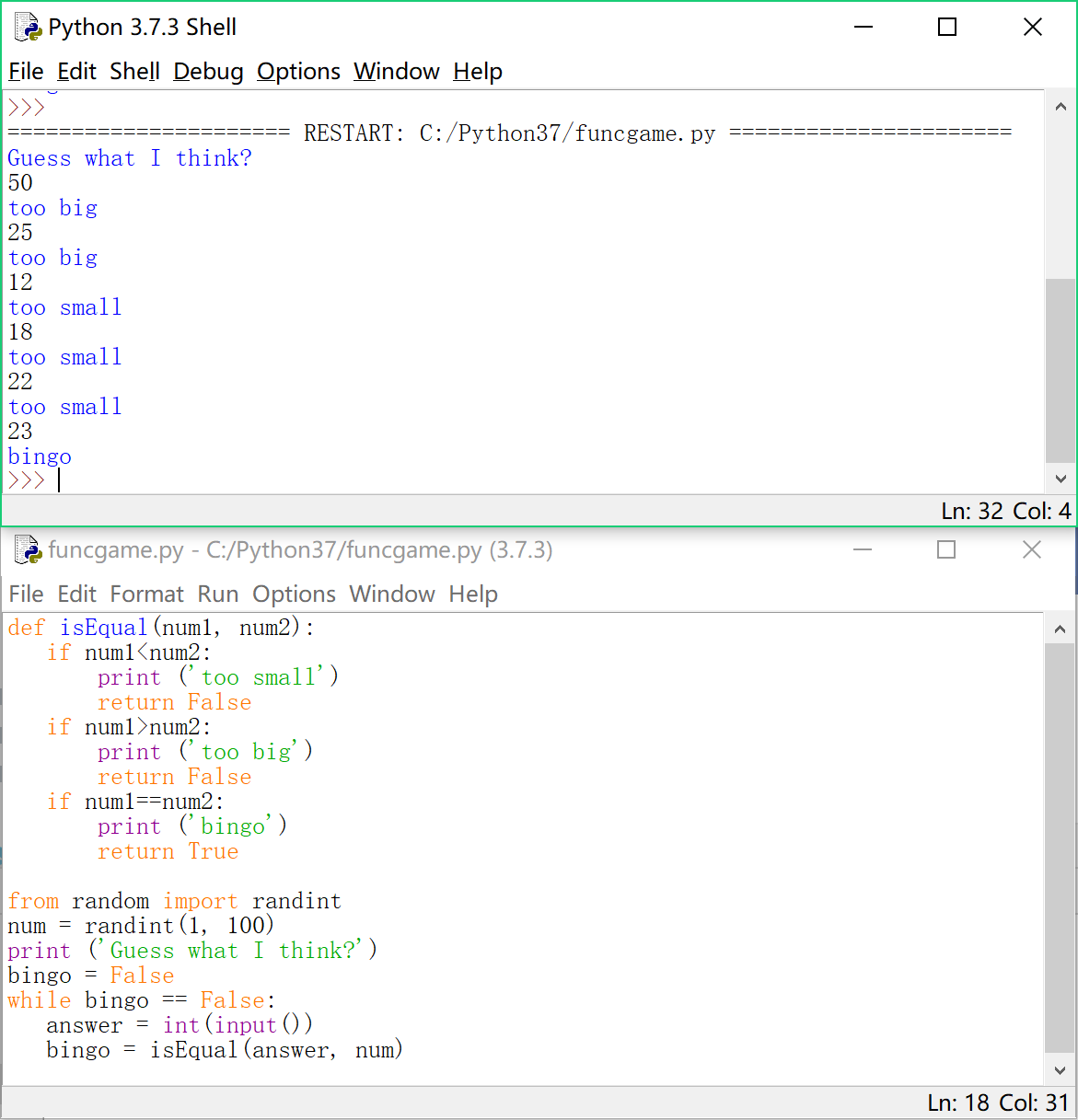
我希望有这样一个函数,它比较两个数的大小。
如果第一个数小了,就输出“too small”
如果第一个数大了,就输出“too big”
如果相等,就输出“bingo!”(意为:猜中了!)
函数还有个返回值,当两数相等的时候返回True,不等就返回False。
于是我们来定义这个函数:
def isEqual(num1, num2):
if num1<num2:
print ('too small')
return False
if num1>num2:
print ('too big')
return False
if num1==num2:
print ('bingo!')
return True
这里说一下,return 是函数的结束语句,return 后面的值被作为这个函数的返回值。函数中任何地方的 return 被执行到的时候,这个函数就会立刻结束并跳出。
注意:函数的 返回值 和我们前面说的 输出 是两回事。print 输出是将结果显示在控制台中,最终一定是转成字符类型;而 返回值,是将结果返回到调用函数的地方,可以是任何类型。
然后在我们的小游戏里使用这个函数:
from random import randint
num = randint(1, 100)
print('Guess what I think?')
bingo = False
while bingo == False:
answer = int(input())
bingo = isEqual(answer, num)
在 isEqual 函数内部,会输出 answer 和 num 的比较结果,如果相等的话,bingo 会得到返回值 True,否则 bingo 得到 False,循环继续。
函数可以把某个功能的代码分离出来,在需要的时候重复使用,就像拼装积木一样,这会让程序结构更清晰。
四.调试程序
写代码,不可避免地会出现bug。很多人在初学编程的时候,当写完程序运行时,发现结果与自己预料中的不同,或者程序意外中止了,就一时没了想法,不知道该从何下手,只能反复重新运行程序,期待忽然有次结果就对了。
今天我就来讲讲代码遇到问题时的一些简单处理方法。
-
读错误信息
来看如下一个例程:
import random a = 0 for i in range(5): b = random.choice(range(5)) a += i / b print (a)
这个程序中,i从0循环到4,每次循环中,b是0到4中的一个随机数。把i/b的结果累加到a上,最后输出结果。
运行这段程序,有时候会输出结果,有时候却跳出错误信息:
Traceback (most recent call last):
File "C:\Users\Crossin\Desktop\py\test.py", line 5, in <module>
a += i / b
ZeroDivisionError: integer division or modulo by zero
有些同学看见一段英文提示就慌了。其实没那么复杂,python的错误提示做得还是很标准的。
它告诉我们错误发生在test.py文件中的第5行
a += i / b
这一句上。
这个错误是“ZeroDivisionError”,也就是除零错。
“integer division or modulo by zero”,整数被0除或者被0模(取余数)。
因为0不能作为除数,所以当b随机到0的时候,就会引发这个错误。
知道了原因,就可以顺利地解决掉这个bug。
以后在写代码的时候,如果遇到了错误,先别急着去改代码。试着去读一读错误提示,看看里面都说了些啥。
-
输出调试信息
我们在所有课程的最开始就教了输出函数“print”。它是编程中最简单的调试手段。有的时候,仅从错误提示仍然无法判断出程序错误的原因,或者没有发生错误,但程序的结果就是不对。这种情况下,通过输出程序过程中的一些状态,可以帮助分析程序。
把前面那个程序改造一下,加入一些与程序功能无关的输出语句:
import random
a = 0
for i in range(5):
print ('i: %d' % i)
b = random.choice(range(5))
print ('b: %d' % b)
a += i / b
print ('a: %d' % a)
print ()
print (a)
运行后的输出结果(每次结果都会不一样):
i: 0
b: 3
a: 0
i: 1
b: 3
a: 0
i: 2
b: 3
a: 0
i: 3
b: 0
Traceback (most recent call last):
File "C:\Users\Crossin\Desktop\py\test.py", line 7, in <module>
a += i / b
ZeroDivisionError: integer division or modulo by zero
当b的值为0时,发生了除零错。这次可以更清晰地看出程序出错时的状态。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









