






1.数仓为什么要分层,常见的分层方式有哪些?
1)空间换时间
2)增强扩展性
3)提高了数据的容错性
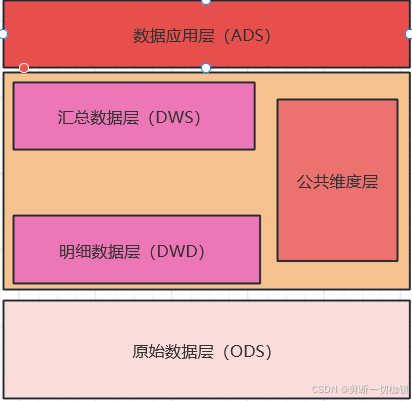
常见的分层:ODS、DWD、DWS、ADS
2.请描述概念并举例说明维度表和事实表?
维度表:事实表示对业务数据的度量,而维度是观察数据的角度
存储着描述性信息,用来解释事实表中的数据,如产品、客户、时间等
通常包含主键,用于与事实表关联
事实表:存储业务过程中的度量值,如销售额、数量、利润等
数据仓库的核心、用于分析和计算
通常包含外键,主要用于关联维度表
事实表的主键 就是维度表的外键
举例:有一个销售事实表,产品ID(主键)、时间ID(主键)、客户ID(主键)
有多个维度事实表:产品维度表:产品ID(外键)、产品名称、类别
时间维度表:时间ID(外键)、日期、月份
客户维度表:客户ID(外键)、客户电话、客户姓名
一个事实表对应多个维度表:星型模型
3.如何理解维度退化?
假设有一个客户维度表,包含以下字段:
客户ID
客户姓名
客户地址
客户城市
客户省份
客户国家
从逻辑上讲,客户城市、客户省份、客户国家可以进一步拆分为一个独立的地理位置的维度表
处于以下原因,仍然保留在这个客户维度表中
减少数据冗余,避免创建过多的维度表
简化模型,便于维护
性能优化、避免过多表的连接操作
4.tairDir怎么实现断点续传
开启三个node01节点 第一个echo hello >> baidu.log 第二个 hi >> qq.log 第一个ping www.baidu.com >> baidu.log
第二个 ping www.qq.com >> qq.log 然后在第三个节点 mv taildir2logger.conf /opt/yjx/apache-flume-1.11.0-bin/options/
将上传上来的.conf文件 覆盖移动到opt/yjx/apache-flume- /options/ 目录下 然后运行flume-ng agent -n a1 -c conf -f ${FLUME_HOME}/options/taildir2logger.conf -Dflume.root.logger=INFO,console
命令 查看这个支持多文件监控的Source运行的情况如何 cat /var/yjx/flume/taildir_position.json 结果为这样 {"inode":141678157,"pos":622017,"file":"/root/baidu.log"},{"inode":141678158,"pos":587487,"file":"/root/qq.log"}
即为成功
将数据分成多个批次,每次同步一个批次。
记录已同步的批次,下次从断点继续。
代码实现:
##定义a1的三个组件的名称
a1.sources = r1
a1.sinks = k1
a1.channels = c1
##定义Source的类型
a1.sources.r1.type = TAILDIR
a1.sources.r1.positionFile = /var/yjx/flume/taildir_position.json
a1.sources.r1.filegroups = f1 f2
a1.sources.r1.filegroups.f1 = /root/baidu.log
a1.sources.r1.headers.f1.headerKey1 = baidu
a1.sources.r1.filegroups.f2 = /root/qq.log
a1.sources.r1.headers.f2.headerKey1 = qq
a1.sources.r1.headers.f2.headerKey2 = v2
a1.sources.r1.headers.f2.headerKey2 = v3
a1.sources.r1.fileHeader = true
a1.sources.r1.maxBatchCount= 1000
##定义Sink的类型
a1.sinks.k1.type = logger
##定义Channel的类型
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
##组装source channel sink
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c15.Flume 拦截器的意义以及如何自定义拦截器?
拦截器主要用于数据在Source传输到Channel之前,对事件进行预处理或过滤,主要作用包括
数据清洗:过滤无效或不需要的数据,定义一个数被三整除,即过滤
数据增强:添加额外信息
数据脱敏:对敏感信息进行脱敏处理
自定义:创建一个Java类并实现org.apache.flume.interceptor.Interceptor接口。您可以实现其intercept()方法,该方法允许您修改或转换事件。此外,您还可以实现initialize()和close()方法,以在拦截器的生命周期中执行任何必要的初始化或清理工作。
在Flume配置文件中为您的拦截器指定一个唯一的名称,并设置它的class属性为您创建的Java
类的完全限定名称。
将您的Java类打包成一个.jar文件并将其放置在Flume的CLASSPATH中,以使Flume能够找到您
的自定义拦截器类。
6.DataX 在使用 HDFSWriter 的时候如何配置 HDFS 的 HA
{
"job": {
"setting": {
"speed": {
"channel": 1
},
"errorLimit": {
"record": 0,
"percentage": 0.02
}
},
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "root",
"password": "123456",
"connection": [
{
"jdbcUrl": ["jdbc:mysql://node01:3306/scott?useUnicode=true&characterEncoding=UTF-8"],
"table": ["emp"]
}
],
"column": [
"empno",
"ename",
"job",
"mgr",
"hiredate",
"sal",
"comm",
"deptno"
],
"splitPk": "empno"
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"defaultFS": "hdfs://hdfs-bd",
"hadoopConfig": {
"dfs.nameservices": "hdfs-bd",
"dfs.ha.namenodes.hdfs-bd": "namenode1,namenode2",
"dfs.namenode.rpc-address.hdfs-bd.namenode1": "node01:8020",
"dfs.namenode.rpc-address.hdfs-bd.namenode2": "node02:8020",
"dfs.client.failover.proxy.provider.hdfs-bd":
"org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider"
},
"path": "/datax/scott",
"fileType": "text",
"fileName": "emp",
"column": [
{
"name": "empno",
"type": "INT"
},
{
"name": "ename",
"type": "STRING"
},
{
"name": "job",
"type": "STRING"
},
{
"name": "mgr",
"type": "INT"
},
{
"name": "hiredate",
"type": "date"
},
{
"name": "sal",
"type": "DOUBLE"
},
{
"name": "comm",
"type": "DOUBLE"
},
{
"name": "deptno",
"type": "INT"
}
],
"writeMode": "append",
"fieldDelimiter": ",",
"encoding": "UTF-8"
}
}
}
]
}
}在json文件中 ,会指名HDFS(path)的位置
需提前在hdfs创建好位置
比如:path": "/datax/scott,需提交创建datax/scott 文件位置 这是hdfs将数据同步输出过来位置
如果是hdfs2hive 还需提前在hive中建立数据库表名,及表的结构 以便于数据同步
7.数仓中使用的哪些文件存储格式?
行式存储:
文本文件(Text File)
CSV文件
列式存储:
Parquet:适用于hadoop生态系统中的多种技术框架(如Hive、Spark)
ORC:可以从存储数据的元信息,方便对数据进行管理和维护,常用于Hive数据仓库
其他存储格式:
Avro:是一种支持数据序列化和反序列化的格式,具有自描述性
HBase:基于Hadoop的列存储的分布式数据库,适用于高并发的应用


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









