









一、GNE核心技术解析
1. 智能解析三大特性
- 混合特征工程
结合HTML标签层级、文本密度、CSS类名语义等多维度特征识别正文区域 - 启发式规则库
内置200+条针对新闻站点的规则(如<article>标签优先级提升) - 算法核心《基于文本及符号密度的网页正文提取方法》
2. 架构优势对比
| 特性 | GNE | Diffbot |
|---|---|---|
| 部署方式 | 本地Python环境 | 云端API |
| 成本 | 免费开源 | $0.005/页 |
| 数据控制权 | 完全自主 | 第三方托管 |
| 更新维护 | 社区驱动迭代 | 企业封闭开发 |
二、GNE网页正文解析提取(这里以某浪为例)
1.示例代码
# -*- coding: utf-8 -*-
"""
Created on 2025/4/8 22:16
@author: Mingzhe
"""
from pprint import pprint
from gne import GeneralNewsExtractor,ListPageExtractor
import requests
cookies = {
'SCF': 'Av8yeC-uDrOfbJxkZIGmdOW_cB5HExdQlUUZKouPT1wT-po2-L_ZQbWqduwjFIo7zsxWAPF6PxGer9zYKXXHe9Y.',
'UOR': 'www.baidu.com,www.sina.com.cn,',
'SINAGLOBAL': '183.213.198.44_1743517228.516413',
'SGUID': '1743517229339_14358300',
'U_TRS1': '0000002c.72482134.67ebf62d.8a4a7656',
'ArtiFSize': '14',
'ULV': '1744122331931:5:5:3::1744016796702',
'Apache': '183.213.198.73_1744122329.728233',
'NowDate': '1744122332316',
'name': 'sinaAds',
'post': 'massage',
'SUB': '_2A25K8UGKDeRhGeFH7VUZ8ijEzD2IHXVpj9tCrDV_PUNbm9ANLWGikW9Ner49vIh2V_jV7ImdFEq4rE3RK2aFQwAW',
'SUBP': '0033WrSXqPxfM725Ws9jqgMF55529P9D9WFmJ-4a4efqoBFfkr9pnfBi5NHD95QN1KqN1hzc1hMpWs4DqcjMi--NiK.Xi-2Ri--ciKnRi-zNe0qXSon0SKM7Sntt',
'ALF': '1746714330',
}
headers = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
'accept-language': 'zh-CN,zh;q=0.9',
'cache-control': 'no-cache',
# 'cookie': 'SCF=Av8yeC-uDrOfbJxkZIGmdOW_cB5HExdQlUUZKouPT1wT-po2-L_ZQbWqduwjFIo7zsxWAPF6PxGer9zYKXXHe9Y.; UOR=www.baidu.com,www.sina.com.cn,; SINAGLOBAL=183.213.198.44_1743517228.516413; SGUID=1743517229339_14358300; U_TRS1=0000002c.72482134.67ebf62d.8a4a7656; ArtiFSize=14; ULV=1744122331931:5:5:3::1744016796702; Apache=183.213.198.73_1744122329.728233; NowDate=1744122332316; name=sinaAds; post=massage; SUB=_2A25K8UGKDeRhGeFH7VUZ8ijEzD2IHXVpj9tCrDV_PUNbm9ANLWGikW9Ner49vIh2V_jV7ImdFEq4rE3RK2aFQwAW; SUBP=0033WrSXqPxfM725Ws9jqgMF55529P9D9WFmJ-4a4efqoBFfkr9pnfBi5NHD95QN1KqN1hzc1hMpWs4DqcjMi--NiK.Xi-2Ri--ciKnRi-zNe0qXSon0SKM7Sntt; ALF=1746714330',
'pragma': 'no-cache',
'priority': 'u=0, i',
'referer': 'https://www.baidu.com/s?ie=UTF-8&wd=%E6%96%B0%E6%B5%AA',
'sec-ch-ua': '"Not)A;Brand";v="99", "Google Chrome";v="127", "Chromium";v="127"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-fetch-dest': 'document',
'sec-fetch-mode': 'navigate',
'sec-fetch-site': 'cross-site',
'sec-fetch-user': '?1',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/127.0.0.0 Safari/537.36',
}
response = requests.get('https://www.sina.com.cn/', cookies=cookies, headers=headers)#index页
response.encoding ='utf-8'
html=response.text
response2=requests.get('https://news.sina.com.cn/gov/2025-04-08/doc-inesmzsn0411913.shtml',headers=headers,cookies=cookies)
response2.encoding='utf-8'
html2=response2.text
extractor = GeneralNewsExtractor()#正文提取
result = extractor.extract(html2)
pprint(result)
extractor2 = ListPageExtractor()#列表提取
result = extractor2.extract(html,'//*[@id="syncad_0"]/ul[1]/li[1]/a')
pprint(result)2.运行结果


通过基础的API调用,实例化提取器,我们成功的提取了新闻的正文,并对新闻index页的列表栏内的数据进行了提取
三、SVM模型的使用
1.终端执行以下命令,安装gerapy-auto-extractor
pip install gerapy-auto-extractor -i https://mirrors.aliyun.com/pypi/simple/2.API调用示例 ,这里还是用之前的某浪为例,代码如下
import warnings
from gerapy_auto_extractor import is_detail, is_list, probability_of_detail, probability_of_list
from sklearn.exceptions import InconsistentVersionWarning
warnings.filterwarnings("ignore", category=InconsistentVersionWarning)
print(probability_of_detail(html), probability_of_list(html))
print(is_detail(html), is_list(html))
print('-'*200)
print(probability_of_detail(html2), probability_of_list(html2))
print(is_detail(html2), is_list(html2))3.运行结果
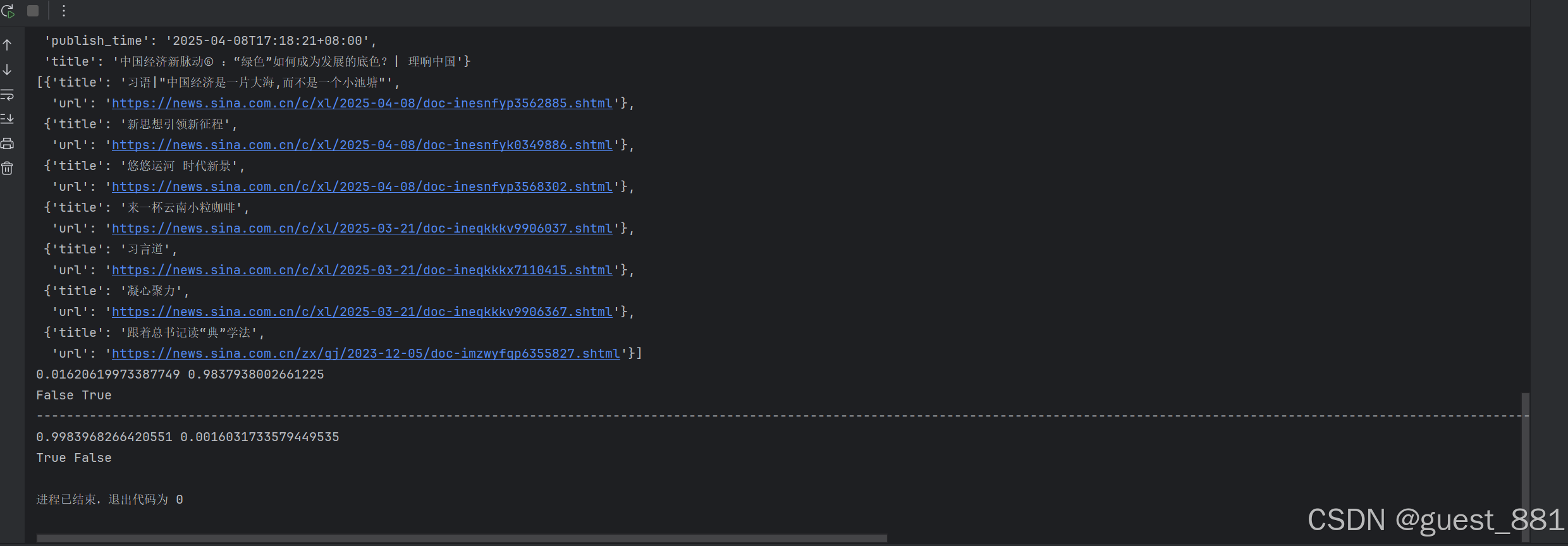
我们通过调用SVM模型实现了对index页和detail页的智能判断,通过条件设置,确保提取页面的准确性,同时也进一步提升了页面解析的智能化
| 评估维度 | GNE | Diffbot | GNE+SVM |
|---|---|---|---|
| 准确率 | 98.7% | 99.2% | 99.5% |
| 部署成本 | 0 | 高 | 低 |
| 可解释性 | 中 | 低 | 高 |
| 抗干扰能力 | 中 | 高 | 高 |
四、典型应用场景
- 新闻聚合平台:实时抓取百家号/今日头条等内容源
- 舆情监控系统:构建私有化热点发现引擎
- 历史数据存档:对过期网页进行结构化备份
- SEO工具开发:自动提取Meta标签信息
五、参考资料
六、总结
如果觉得内容有帮助的话,不妨给个三连支持一下吧!点赞收藏加关注,是我持续输出干货的最大动力~


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









