






LLMOps中的Bias检测:ID&E嵌入LLM生命周期
关键字: [Amazon Web Services re:Invent 2024, 亚马逊云科技, 生成式AI, Claude, Large Language Models, Bias Detection, Model Lifecycle, Responsible Ai, Data Collection]
导读
大型语言模型(LLMs)可能会延续社会偏见,导致产生歧视性输出。这个闪电演讲探讨了在LLMOps生命周期中检测和缓解偏见的技术,涵盖从数据收集到模型部署和监控的全过程。学习构建包容性数据集、实施去偏见策略、进行偏见测试以及处理伦理考量的最佳实践。通过案例研究和实践示例,参与者将获得将包容性、多样性和公平性融入LLMOps流程的实用工具和方法的见解。本演讲为与会者提供了构建更值得信赖的LLMs的策略,确保这些强大技术的负责任开发和部署。
演讲精华
以下是小编为您整理的本次演讲的精华。
在2024年亚马逊云科技 re:Invent活动上,亚马逊云科技高级产品架构师Candace Bohannon发表了一场题为“LLMOps中的偏差检测:将ID&E嵌入LLM生命周期”的精彩演讲。她的演讲深入探讨了在开发和部署大型语言模型(LLM)时培养多元化、包容性和公平性(ID&E)的重要性。LLM技术发展迅速,据路透社报道,ChatGPT在短短两个月内就达到了1亿用户,速度超过了TikTok和Instagram等平台。
Bohannon承认LLM和生成式人工智能技术具有巨大潜力,但同时强调了这种强大技术所带来的责任。她强调需要将公平性、问责制和包容性的原则融入到这些模型的核心,确保代表不同视角,让每个人的声音都能被听到。在整个演讲过程中,Bohannon强调了LLM生命周期中可能引入偏差的各个阶段。
在数据收集阶段,她强调构建包容性和代表性数据集的重要性,寻求多元化视角,并确保不同人口统计数据的平衡代表性。Bohannon引用了2017年的“性别阴影”论文,当时现成的人脸识别软件在识别女性面孔和深肤色时表现不佳,将25%的深肤色女性面孔的性别误分类,这一比例高达样本量的50%。她将这种偏差归因于用于训练这些模型的数据缺乏多样性,往往反映了科技行业的同质性。
Bohannon还讨论了LLM训练数据不透明的挑战,这些数据往往包含版权材料,被模型创建者视为“秘密配方”。她提到这些模型是在1万亿个数据点上训练的,使得检测和缓解偏差变得困难。此外,她强调了通过迁移学习引入偏差的潜在风险,在这种情况下,原始“父模型”中的偏差可能会在微调过程中无意中转移到“子模型”中。
在模型开发方面,Bohannon解释了如何通过模型架构本身引入偏差,包括神经网络架构的选择、超参数调优以及训练过程中使用的目标函数和损失函数。她引用了亚马逊云科技博客上的一篇博文,该博文讨论了使用最初在英语数据上训练的“父模型”来微调日语语言模型的挑战,以及为缓解这些偏差而采取的策略,例如在完全微调日语数据集之前,使用两种语言的低质量数据。该博文详细介绍了使用亚马逊的Tranimum服务来微调和训练日语模型。
为了减轻LLM中的偏差,Bohannon提出了几种策略。模型监控涉及监控概念漂移、数据分布偏移和模型漂移,以确保模型保持与预期用途一致,并维持预期性能。可以使用开源库和自动化工具进行公平性审计,以评估模型输出是否存在偏差。用户反馈和报告机制允许用户对模型响应提供反馈,这些反馈可以反馈到MLOps反馈循环中,用于持续改进。
Bohannon提到的对抗性测试涉及模拟对抗性场景,以测试模型对潜在误用或利用的鲁棒性。她引用了德勤的一个例子,研究人员能够欺骗自动驾驶汽车误分类限速标志,可能导致危险情况,如将30英里/小时的限速标志误解为80英里/小时的校园区限速。为了减轻这种风险,Bohannon建议应用亚马逊Bedrock防护栏,可以确保模型输出不具有毒性、偏差或违反特定约束,例如防止模型重复脏话或提及竞争对手名称。
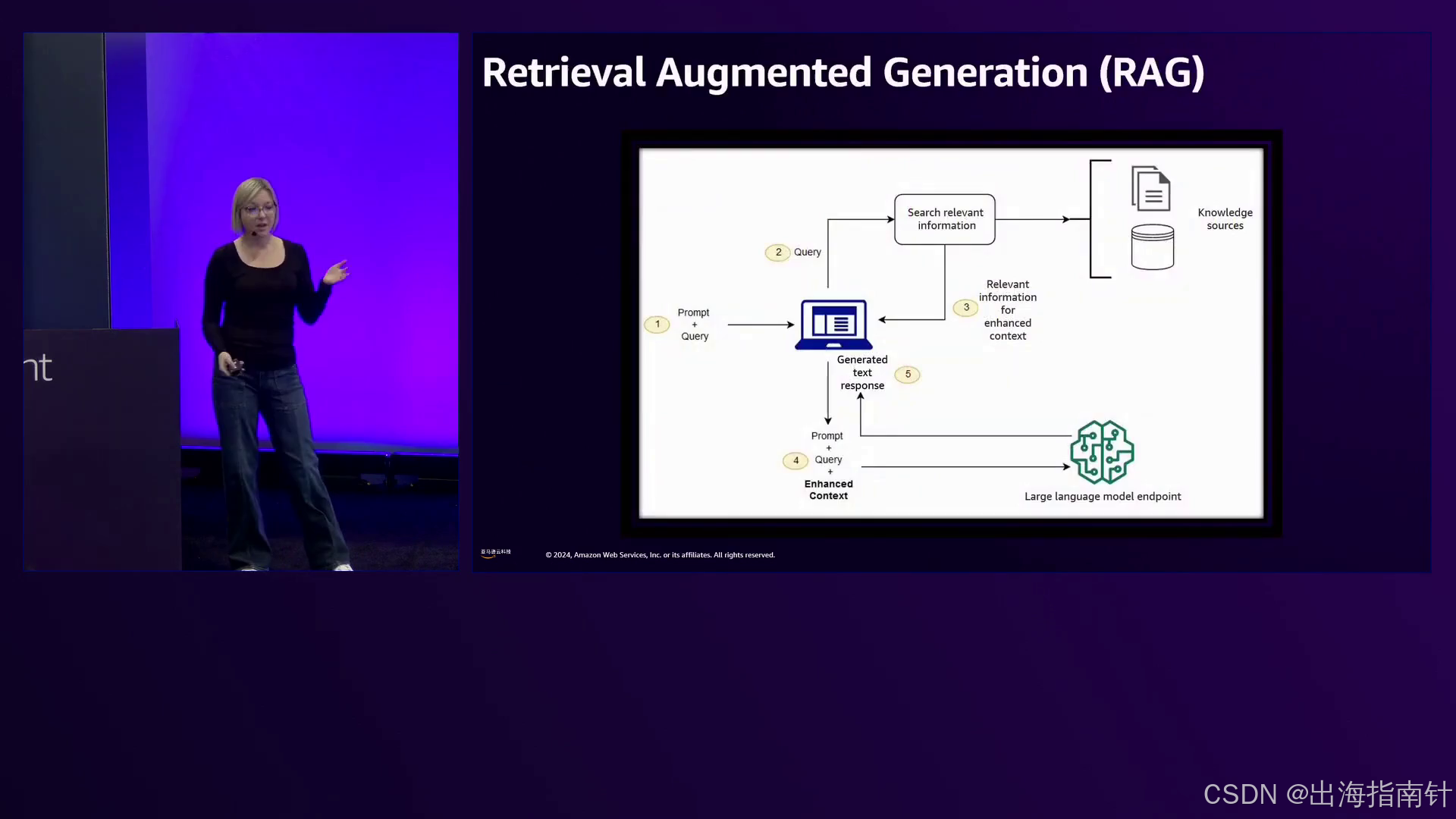
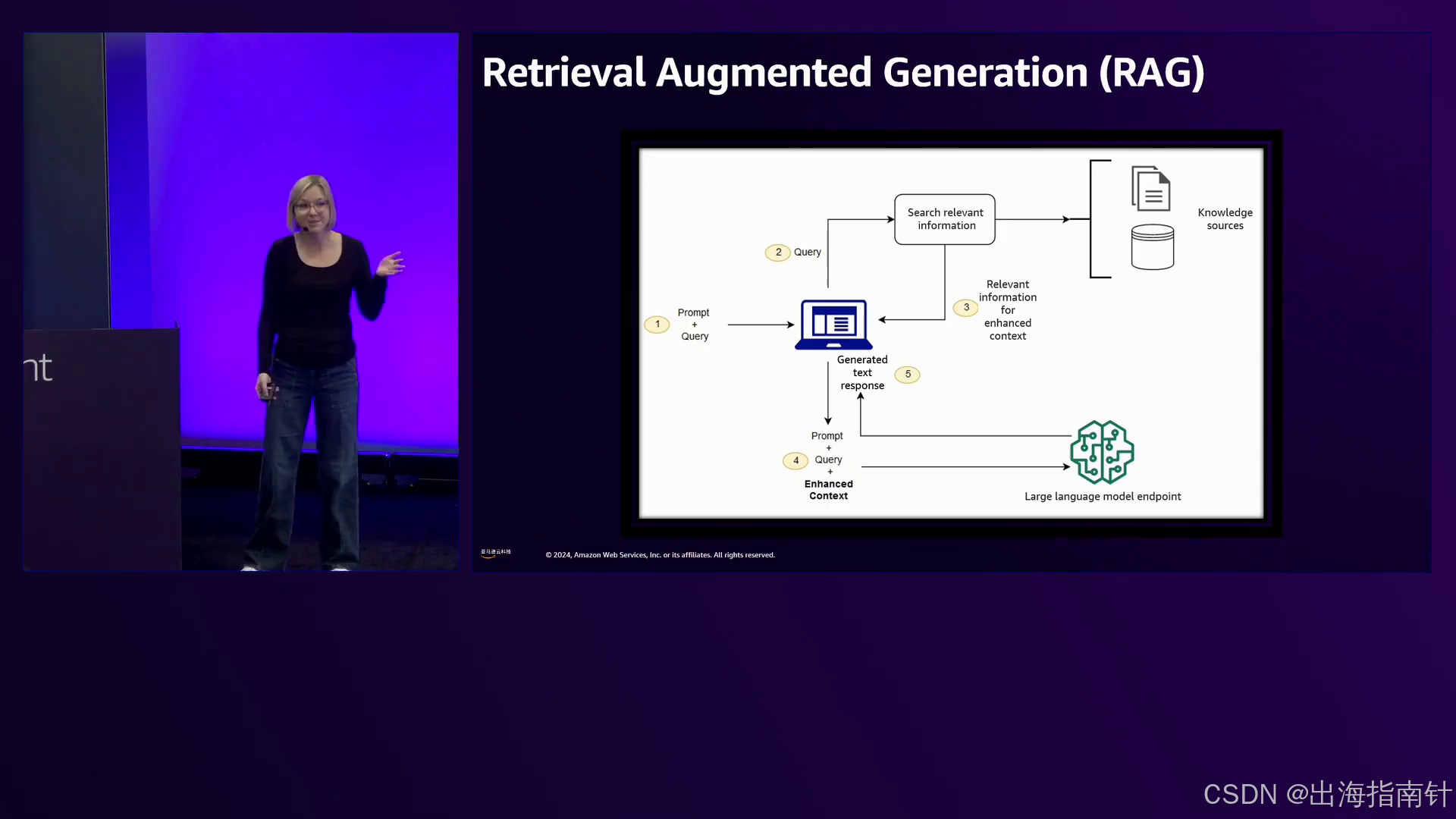
Bohannon讨论的另一种策略是检索增强生成(RAG)模型,它涉及整合特定领域的知识库来增强模型响应并提高准确性。通过利用外部知识源,RAG模型可以提供更可靠和更具上下文的输出,尽管会引入响应时间延迟。
Bohannon还强调了几个关注负责任人工智能的行业资源和倡议。她提到了她最喜欢的LLM Claude,由Anthropic开发,它融入了“宪政人工智能”的概念,以确保道德和负责任的行为。此外,她推荐了斯坦福人工智能指数中关于负责任人工智能的第3章,该章节提供了监控和减轻人工智能系统偏差的指标和指南。最后,Bohannon指出亚马逊云科技科学博客上丰富的出版物是进一步探索的宝贵资源。
总之,Bohannon在亚马逊云科技 re:Invent 2024活动上的演讲强调了在LLM生命周期的各个阶段,从数据收集到模型部署和监控,都需要融入多元化、包容性和公平性原则的重要性。通过培养更加多元化和代表性的科技行业,并采用负责任的人工智能实践,我们可以开启新的视角,确保每个人的声音都能被听到,并减轻这些强大的人工智能技术可能带来的偏差和伤害,而这些技术正迅速融入到我们生活的各个方面。
下面是一些演讲现场的精彩瞬间:
演讲者强调了大型语言模型和人工智能的巨大潜力,同时强调了确保公平性、问责制和包容性植根于这些模型中的责任。

演讲者强调了理解偏差的重要性,提供了精确的数学定义来准确测量偏差。

演讲者强调了现成的计算机视觉性别模型存在偏差和不准确性,尤其是以惊人的25%的比率错误地将较深肤色女性面孔归类。

Andy Jassy强调了在大型语言模型中上下文和文化意识的重要性,强调了透明度和人工监督的需求,以减轻潜在的偏差。

演讲者强调了一篇有趣的亚马逊云科技博客文章,讨论了使用Tranimum对日语语言模型进行微调,展示了解决机器学习中特定语言挑战的创新方法。

演讲者讨论了RAG(Retrieval Augmented Generation)模型,这些模型允许整合自定义知识库以增强模型的响应,同时保持一般知识。
演讲者表达了对由Anthropic开发的大型语言模型Claude的钦佩,并强调了该公司在Constitutional AI方面的创新方法。
总结
大型语言模型(LLM)的快速发展带来了巨大的机遇和重大的责任。在利用这些尖端技术的力量时,我们必须将公平、问责和包容性的原则融入其发展生命周期的每个阶段。本文探讨了检测和缓解数据收集、模型架构和部署过程中可能产生的偏差的策略。
首先,我们深入探讨了多样化和代表性数据集的重要性。用于训练模型的数据缺乏包容性可能导致偏见和偏见。过度采样代表性不足的群体,培养情境和文化意识是缓解这些偏差的关键步骤。
其次,我们研究了模型架构和目标函数如何无意中引入偏差。诸如对抗性测试、应用防护栏以及利用检索增强生成(RAG)模型等技术可以帮助识别和解决这些问题。
最后,我们强调了在LLM生命周期中持续监控和人工监督的必要性。用户反馈机制、公平审计以及Anthropic、斯坦福大学和亚马逊云科技等行业领导者的负责任AI实践可以指导我们将公平和包容性融入这些强大的技术中。
通过培养更加多元化和代表性的科技行业,我们可以开启新的视角,确保每个人的声音都被听到。在探索令人兴奋的LLM领域时,让我们承担起创建公平、负责任和包容的人工智能系统的责任,造福整个社会。
亚马逊云科技(Amazon Web Services)是全球云计算的开创者和引领者。提供200多类广泛而深入的云服务,服务全球245个国家和地区的数百万客户。做为全球生成式AI前行者,亚马逊云科技正在携手广泛的客户和合作伙伴,缔造可见的商业价值 – 汇集全球40余款大模型,亚马逊云科技为10万家全球企业提供AI及机器学习服务,守护3/4中国企业出海。

















 1038
1038

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









