






一、丹摩平台的核心特色
1.友好便捷的操作体验:
(1)一键部署:使开发者能够在极短的时间内启动开发环境,快速进入到算法和模型的开发工作中,无需花费大量时间在复杂的配置上。
(2)丰富的资源配置:多样化的 GPU 选择、灵活的付费模式、充足的数据存储
2.高性能的计算能力:
(1)自建 IDC 与全新设备:平台采用自建 IDC 和全新的 GPU 设备,能够为用户提供高效、稳定的计算能力,保证模型训练、推理部署和数据分析等任务的快速完成,显著缩短项目开发和模型优化的时间。
(2)高性能网络与存储:计算节点之间以及计算节点与存储节点之间均采用高性能网络,同时提供高并发、高性能的存储服务,避免了网络及存储性能瓶颈,使算力节点性能得到充分发挥。
3.全面的服务支持:
(1)多种服务类型:提供模型训练、模型推理、开源模型镜像与开源数据集社区服务等。
(2)定制化部署:能够根据用户的需求提供从方案设计、部署实施,到日常运维、系统优化等全流程的服务,满足不同用户的个性化需求。
4.高性价比:与市场上的其他智算平台相比,丹摩平台提供了具有竞争力的价格体系,并且会定期推出优惠活动,让用户能够以较低的成本享受到优质的算力资源。
- 如何使用丹摩平台
- 先进入丹摩智算官网(https://www.damodel.com/home),完成账号的注册并通过实名认证。
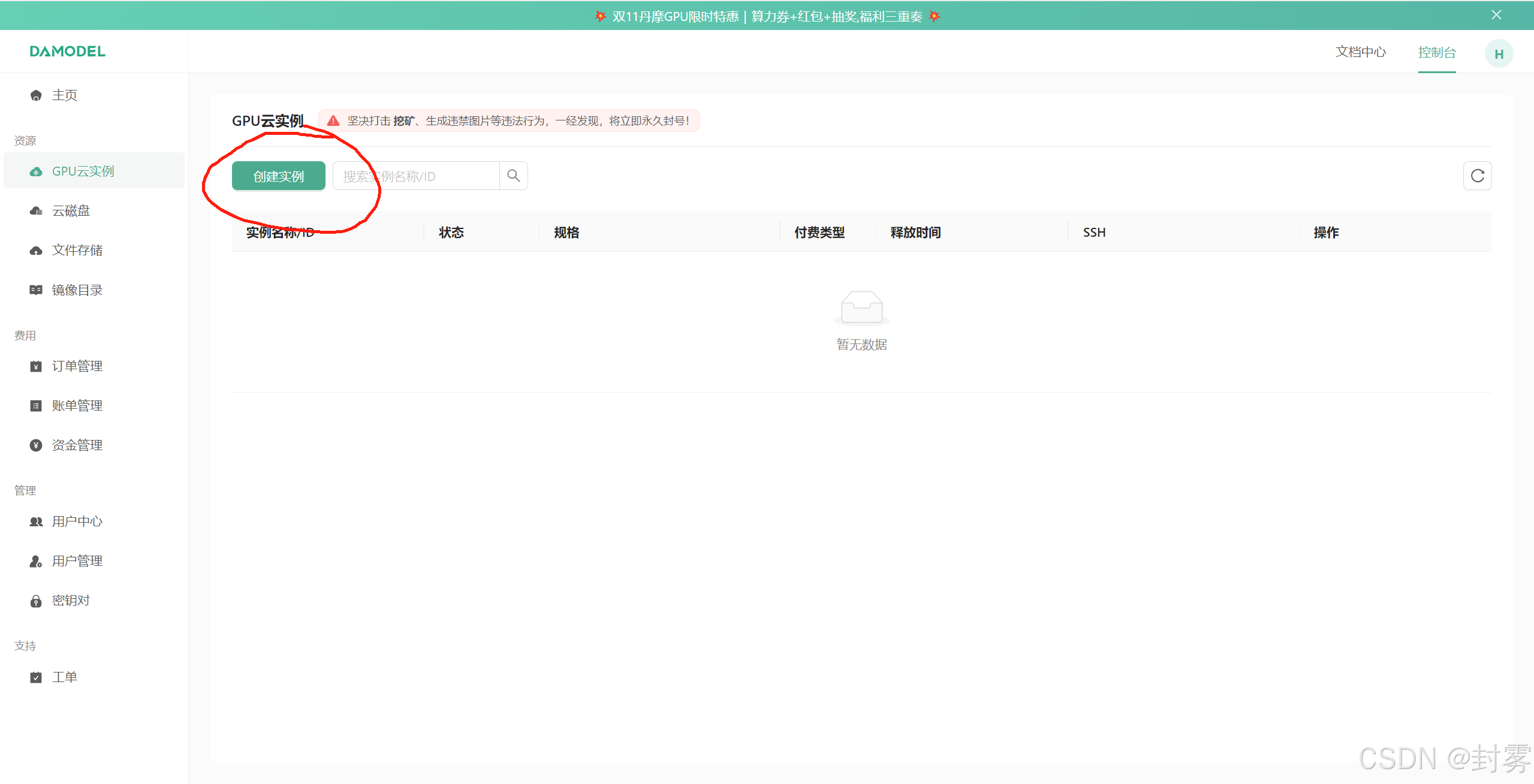
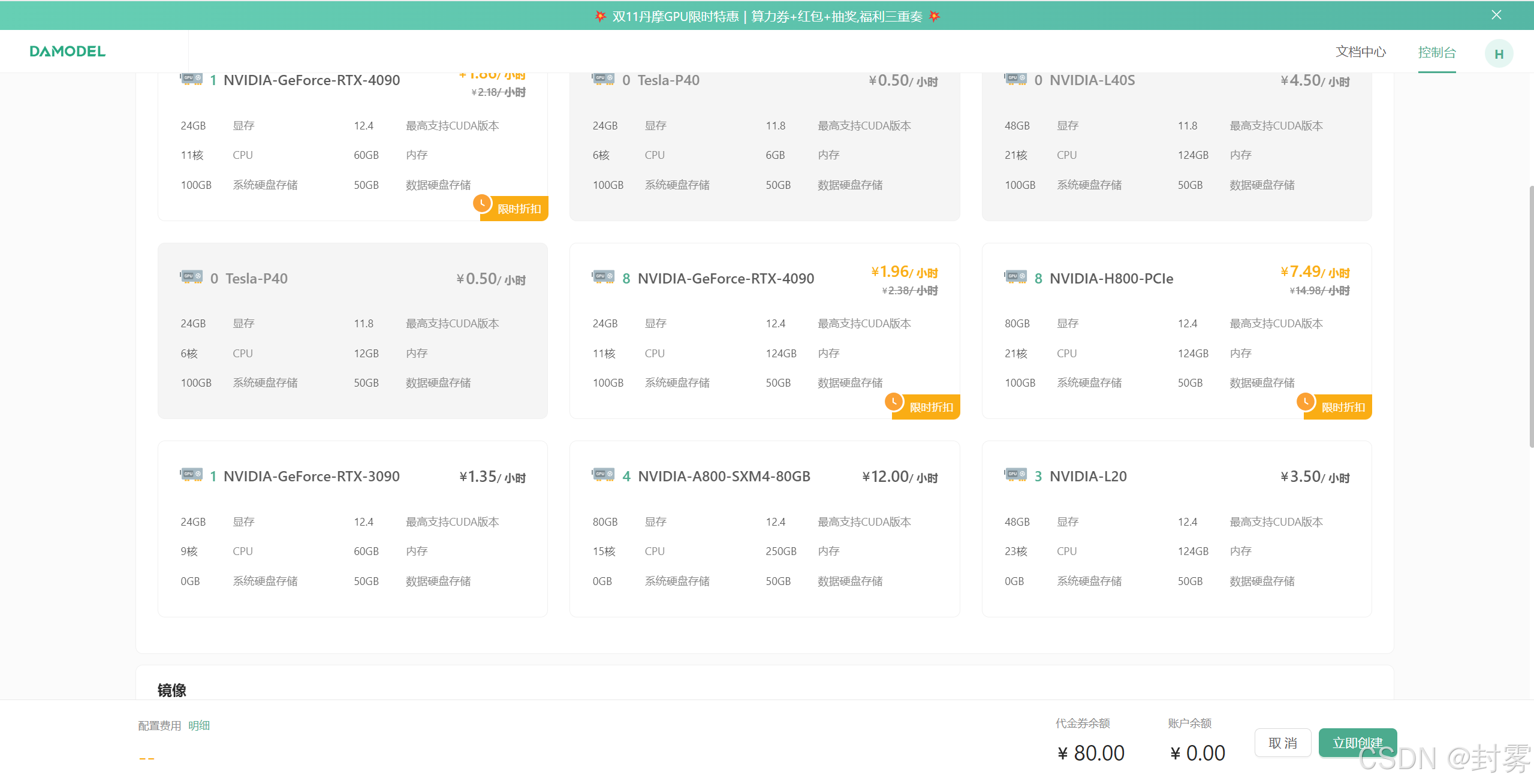
2、登录账号后,进入控制台,点击 “GPU 云实例”,然后点击 “创建实例”。在实例配置中,选择付费类型、GPU 数量和型号、镜像、登录实例等选项。点击 “立即创建”,等待实例创建完成。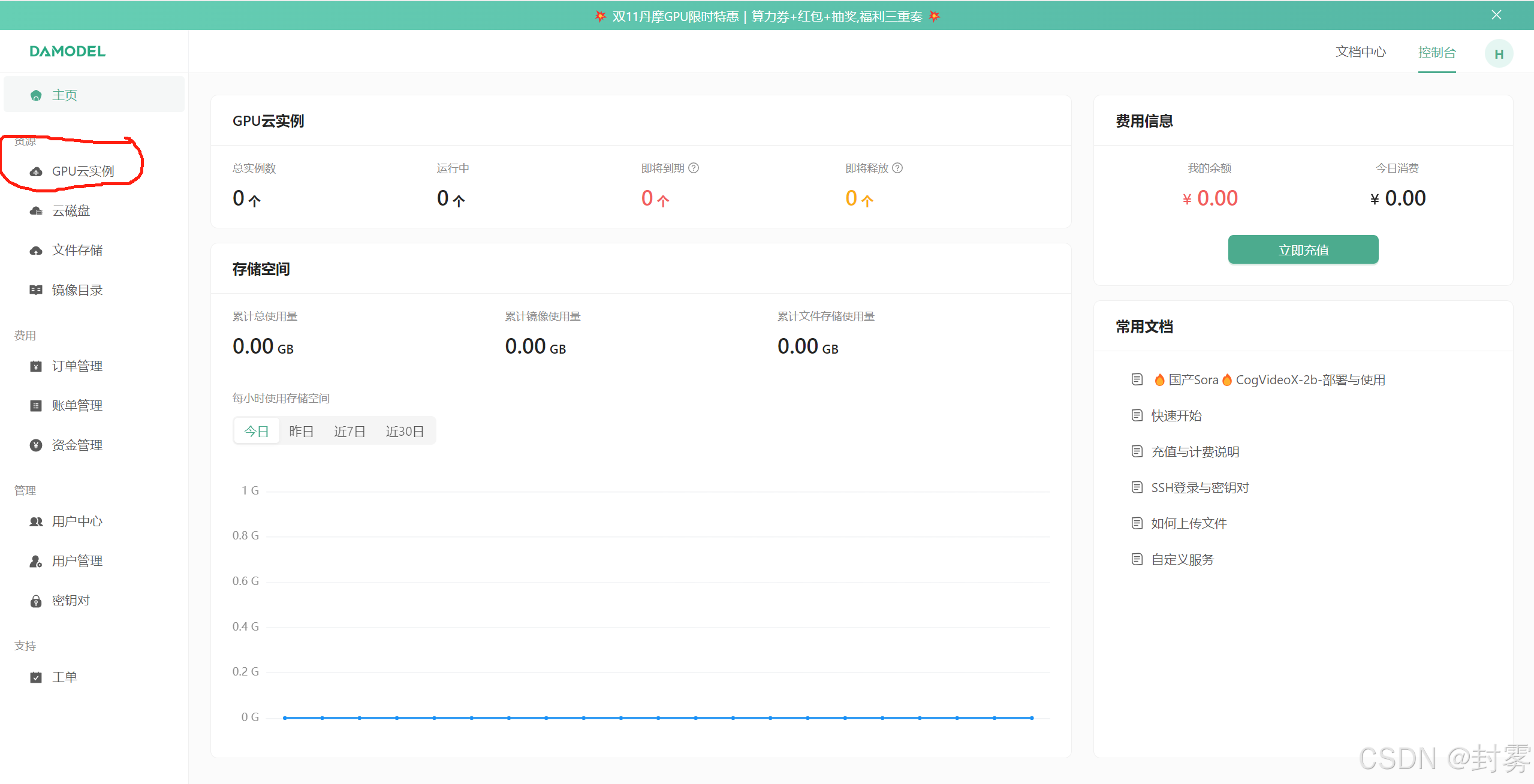
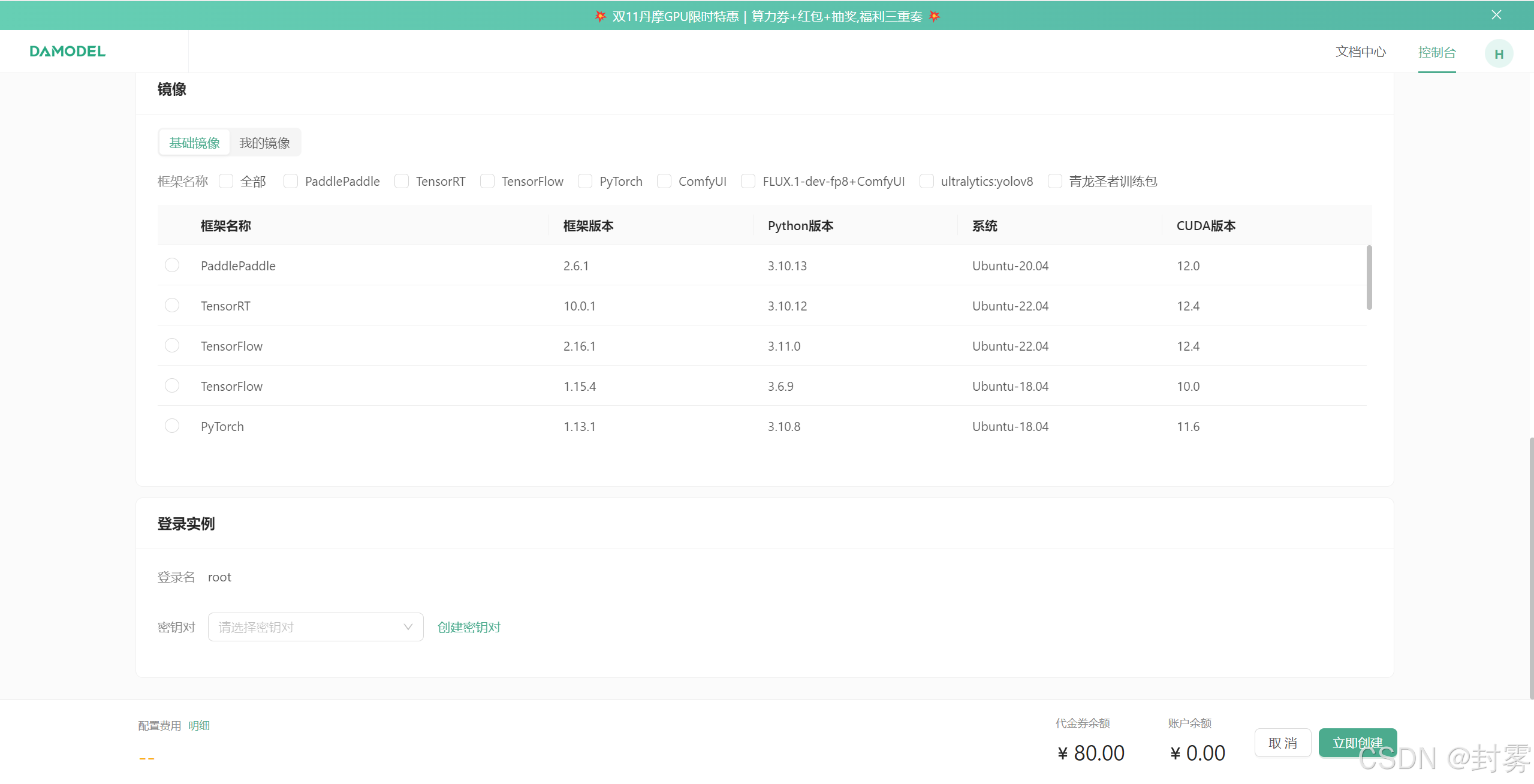
3、上传数据:在控制台中点击 “文件存储”,然后点击 “上传文件”,选择需要上传的文件或文件夹,并等待上传完成。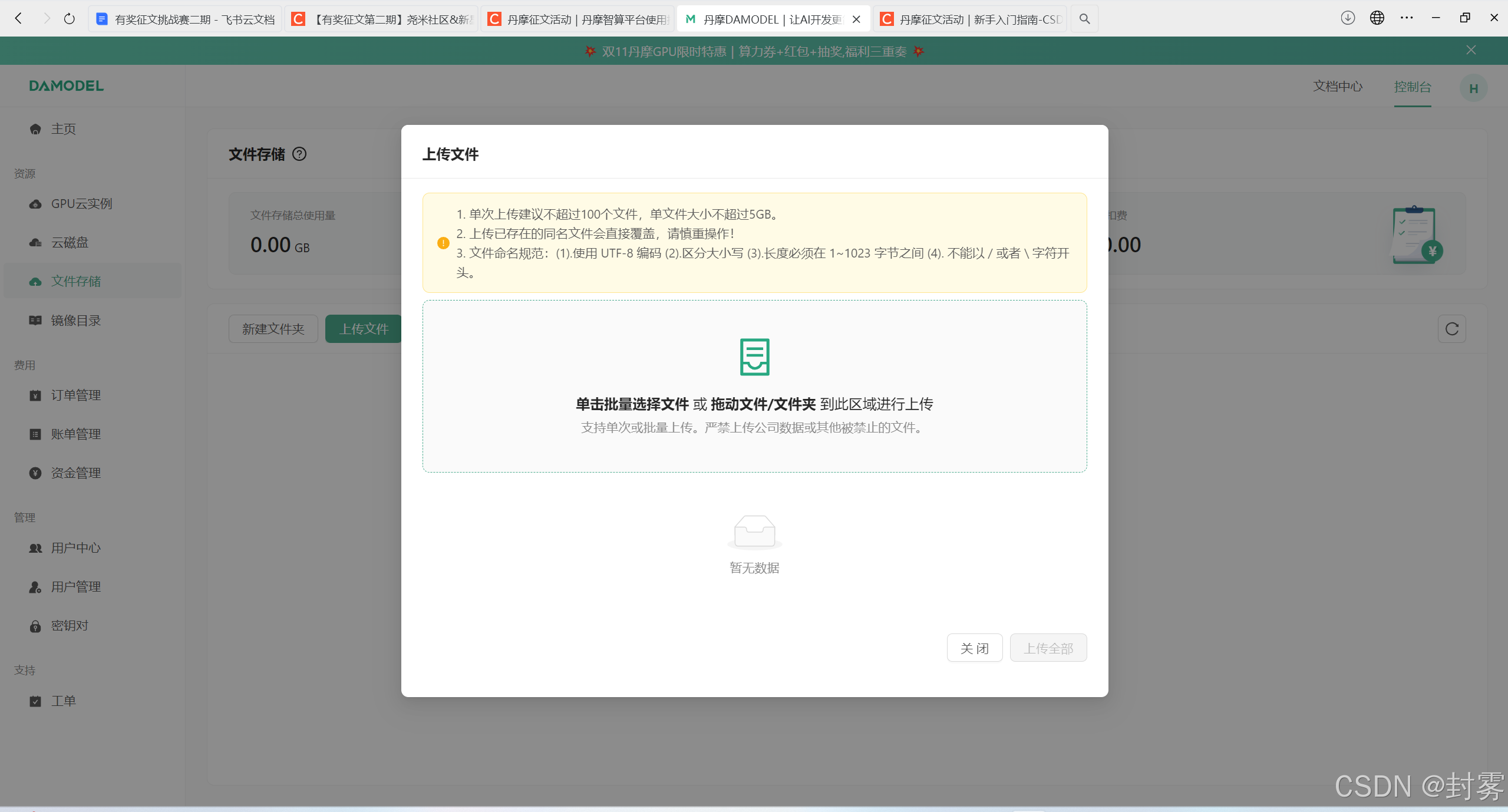
4、连接实例:获取实例的 SSH 访问信息,包括主机地址、端口号和用户名。使用 SSH 客户端连接到实例,输入私钥文件路径进行身份验证。
5、使用平台:连接成功后,你可以在实例上进行各种操作,如运行代码、安装软件等。
三、常见问题见解
1、实例创建与使用相关
(一)如何选择合适的实例配置:
1、如果您的任务对计算性能要求较高,如深度学习训练、大规模数据分析等,建议选择 GPU 数量较多、型号较新的实例。
2、对于一般性的开发测试任务,CPU 性能和内存大小是关键因素。可以根据任务的内存需求选择合适的数据硬盘大小,一般来说,50GB 的数据硬盘对于大多数应用是足够的,但如果您需要存储大量的数据文件,可能需要扩容数据硬盘。
(二)、实例创建失败的原因有哪些:
1、账户余额不足,确保您的账户有足够的资金支付所选的实例配置。
2、所选的 GPU 型号或资源在当前地区不可用,尝试更换其他可用的 GPU 型号或地区。
3、网络问题导致与平台的通信异常,检查您的网络连接是否稳定,或者尝试在不同的网络环境下创建实例。
2、数据存储与传输相关:
(一)、如何上传和下载数据:
1、上传数据:在控制台中点击 “文件存储”,然后点击 “上传文件”,选择需要上传的文件或文件夹,并等待上传完成。
2、下载数据:在实例中找到需要下载的文件,通过 SFTP 工具将文件从实例下载到本地计算机,或者在控制台中找到相应的下载选项。
(二)、数据存储容量不够怎么办:
1、如果您的免费存储空间不够用,可以考虑删除一些不必要的数据文件,释放存储空间。
2、联系丹摩平台的客服或技术支持,了解是否可以扩容数据存储,以及扩容的费用和操作方法。
3、模型部署与运行相关
(一)、模型部署过程中遇到依赖包冲突如何解决:
1、首先,确定冲突的依赖包具体是哪些。可以查看模型部署过程中的错误提示信息,或者在终端中查看依赖包安装过程中的输出日志。
2、尝试卸载冲突的依赖包,然后重新安装所需的依赖包。在卸载和安装依赖包时,确保按照正确的顺序进行操作,以避免再次出现冲突。
3、如果依赖包之间的冲突无法解决,可以尝试使用虚拟环境来隔离不同的依赖包版本,确保模型能够正常运行。
(二)、模型运行速度慢的原因及解决方法:
1、原因可能是 GPU 资源利用率不高,可以检查模型是否正确配置了 GPU 加速,以及是否使用了适合 GPU 计算的算法和框架。
2、数据预处理过程可能过于复杂或耗时,优化数据预处理代码,减少不必要的操作,提高数据处理效率。
3、网络带宽不足也可能影响模型的运行速度,如果您需要从远程数据源获取数据,确保网络连接稳定且带宽足够。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









