






概念理论学习
三种编码的学习
原码编码
定义:最高位为符号位(0表示正数,1表示负数),其余位直接表示数值的绝对值
特点:最高位区分正负
举例:假设最高位是8位
+5的原码编码为00000101
-5的原码编码为10000101
反码编码
定义:正数的反码与原码相同;负数的反码为原码符号位不变,其余位按位取反
特点:最高位区分正负,相反数互为取反值
举例:假设最高位是8位
+5的反码编码为00000101
-5的反码编码为11111010
补码编码
定义:正数的补码与原码相同;负数的补码为其反码加1
特点:最高位区分正负,只存在唯一0
举例:假设最高位为8位
+5的补码编码为00000101
-5的补码编码为11111011
了解位移运算
位移运算是一种针对整数类型二进制数据的运算,主要分为逻辑位移,算数位移,循环位移三类
逻辑位移
作用对象: 无符号整数,不考虑符号位(也就是不管负号)
运算规则:
左移(<<):高位丢弃,低位补0;例如: 10011 << 2 结果为 01100
右移(>>):低位丢弃,高位补0;例如: 10111 >> 3 结果为00010
算术位移
作用对象: 有符号整数(注:这里分为原码,反码,补码讨论),需保留符号位(要考虑负号对结果精确度的影响)
运算规则:
原码的算术位移
规则:符号位固定,仅对数值部分进行移位。
左移(<<):高位丢弃,低位补0;
右移(>>):低位丢弃,高位补0;
举例:
对于正数+5,原码编码为(000101)
算数左移:000101 << 2结果为010100
算数右移:000101 >> 2结果为000001
对于负数-5,原码编码为(100101)这里要注意移动时只对数值位运算,符号位保持不动
算数左移:100101 << 2结果为110100
算数右移:100101 >> 2结果为100001
反码的算数位移
规则:
正数反码:与原码相同,移位补0
负数反码:与原码相反,移位补1
同样符号位固定,仅对数值部分进行移位
举例:
对于正数+5
反码编码为000101
算数左移:000101 <<2 结果为010100
算数右移:000101>> 2 结果为000001
对于负数-5
反码编码为111010
算数左移:111010 <<2 结果为101011
算数右移:111010 <<2 结果为111110
补码的算数位移
规则:
正数补码:与原码相同,移位补0。
负数补码:符号位固定,右移高位补1,左移低位补0,同时符号位保持为1
举例:
对于正数+5
补码编码为:000101
算数左移:000101 << 2结果为010100
算数右移:000101 >> 2结果为000001
对于负数-5
补码编码为:111011
算数左移:111011 << 2结果为101100
算数右移:111011 >> 2结果为111110
循环位移
总的原理: 循环左移(ROL):所有位左移,最高位移出并补到最低位。
循环右移(ROR):所有位右移,最低位移出并补到最高位。
作用对象:原码,反码,补码所编码的字符
运算规则:
原码的循环位移
符号位固定在最左侧,数值位单独处理;原码的循环位移仅作用于数值部分,符号位不变
对于正数5:原码编码为00000101
符号位是0,数值位是0000101
循环左移1位:数值部分变成0001010,符号位是0,那么最后的结果是00001010
循环右移1位:数值部分变成1000010,符号位是0,那么最后的结果是01000010
对于负数-5,原码编码为10000101
符号位是1,数值位是0000101
循环左移1位:数值部分变成0001010,符号位是1,那么最后的结果是10001010
循环右移1位:数值部分变成1000010,符号位是,那么最后的结果是11000010
反码的循环位移
规则:所有位(包括符号位)共同参与循环位移。
举例:
对于5,反码编码为11111010
循环左移1位,最后的结果为11110101
循环右移1位,最后的结果为01111101
补码的循环位移
规则:所有位(包括符号位)共同参与循环位移。
对于-5,补码编码为11111011
循环左移1位:最后的结果是11110111
循环右移1位:最后的结果是11111101
关于实战
如何识别这三种编码方式
原则上来说,补码编码在当今计算机编码中占据绝对地位,因为另外两种编码均存在局限性,例如0的唯一性。
大部分实战环境中采用的编码方式都是补码;原码,反码,补码的转换可能会放在中间步骤求解密钥的过程中,以上只是个人理解,可能存在局限性
如何判断和区分逻辑位移,算数位移和循环位移
看是否有位丢失
在逻辑位移运算中,无论数据是否带符号,左移还是右移,移动时永远会丢失位数,丢失位数补零;算数位移会保留符号位;循坏位移是不会丢失位数的。
但是这种判断方式有很大的局限性,就是不能高效准确地判断出算数位移和逻辑位移
看汇编指令
这个方法是比较准确的,根据在IDA中查看汇编指令可以准确判断出位移运算的类型的
逻辑位移:x86指令SHL(左移)、SHR(右移)。
算术位移:x86指令SAR(算术右移)、SAL(算数左移)
循环位移:x86指令ROL(循环左移)、ROR(循环右移)
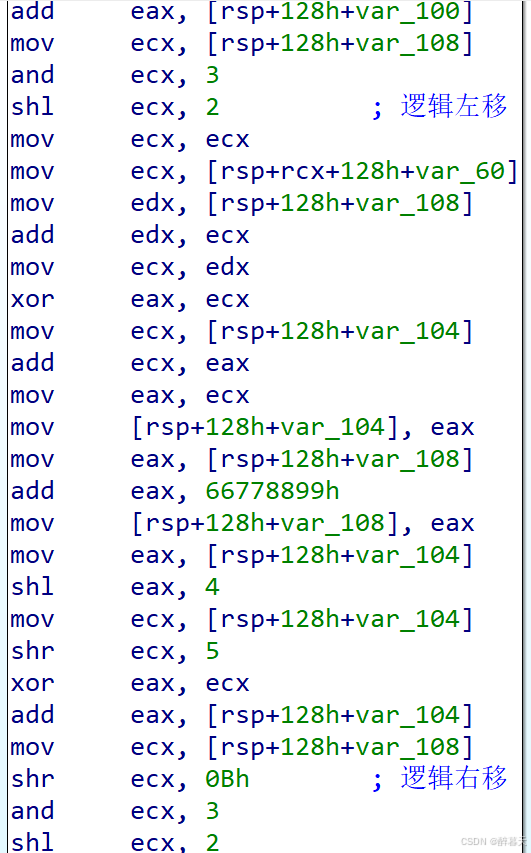 通过对汇编语言的识别可以快速准确地判断出位移运算类型,这个也是最常用的方法
通过对汇编语言的识别可以快速准确地判断出位移运算类型,这个也是最常用的方法
python中的判断方式
在python中<<默认是逻辑左移,而>>默认是算数右移。(要注意位移掩码的存在)
循环位移的特征比较明显,而且考察也最多
a = ((x >> 6) | (x << 7))
长这种格式的就是循环位移的格式,先向右移动6位,再向左移动七位
例题
这是一道python题目:
import base64,hashlib,math
def _kernalize(s):
return hashlib.md5(s.encode()).hexdigest()[:8]
def redcordage(sakura, glg=0x1F):
Franxx = []
for i, char in enumerate(sakura):
a = ord(char) ^ (glg + i % 111 )
x = ord(char) ^ (glg + i % 8)
a = ((x >> 6) | (x << 7)) & 0xFF
x = ((x >> 3) | (x << 5)) & 0xFF
a = ord(char) ^ (glg + i % 111)
a = ((x >> 6) | (x << 7)) & 0xFF
Franxx.append(x)
return base64.b64encode(bytes(Franxx)).decode()
if __name__ == "__main__":
text = input("这里就是加密flag的入口噢")
print(redcordage(text))
#redcordage(text)=yKrpS0nrCELPgojiCMJoAmUiIgjIgmLCb0Ij6AiDo+gF4mIC4mIL
根据这个特征,可以判断出来是循环位移加密,这题更重要的是绕过干扰代码,因为里面存在冗余代码,可以发现,第一个定义的函数没用过,第二段循环位移的过程中a变量没用输出,判断为冗余代码,所以重新整编一下代码:
import base64
def redcordage(sakura, glg=0x1F):
Franxx = []
for i, char in enumerate(sakura):
x = ord(char) ^ (glg + i % 8)
x = ((x >> 3) | (x << 5)) & 0xFF
Franxx.append(x)
return base64.b64encode(bytes(Franxx)).decode()
if __name__ == "__main__":
text = input("这里就是加密flag的入口噢")
print(redcordage(text))
#redcordage(text)=yKrpS0nrCELPgojiCMJoAmUiIgjIgmLCb0Ij6AiDo+gF4mIC4mIL
这里主要讨论循环位移,就重点讲一下循环位移算法在python中的解法,最简单的解法就是把移动位置交换一下,例如:
x = ((x >> 3) | (x << 5)) & 0xFF
这里先进行逻辑右移3位,再进行逻辑左移5位,最终达成循环位移的效果
上面提到过,在python语言中,>>默认是算数右移,那这里为什么会判断成逻辑右移呢?
关键在这串代码后面的掩码& 0xFF,这里涉及到python的语法,通过 & 0xFF 等位掩码限制数值范围,强制高位补0,就达成了逻辑位移的效果
解密时:最简单的方式就是将位移方向调换一下
x = ((x << 3) | (x >> 5)) & 0xFF
最后的解密脚本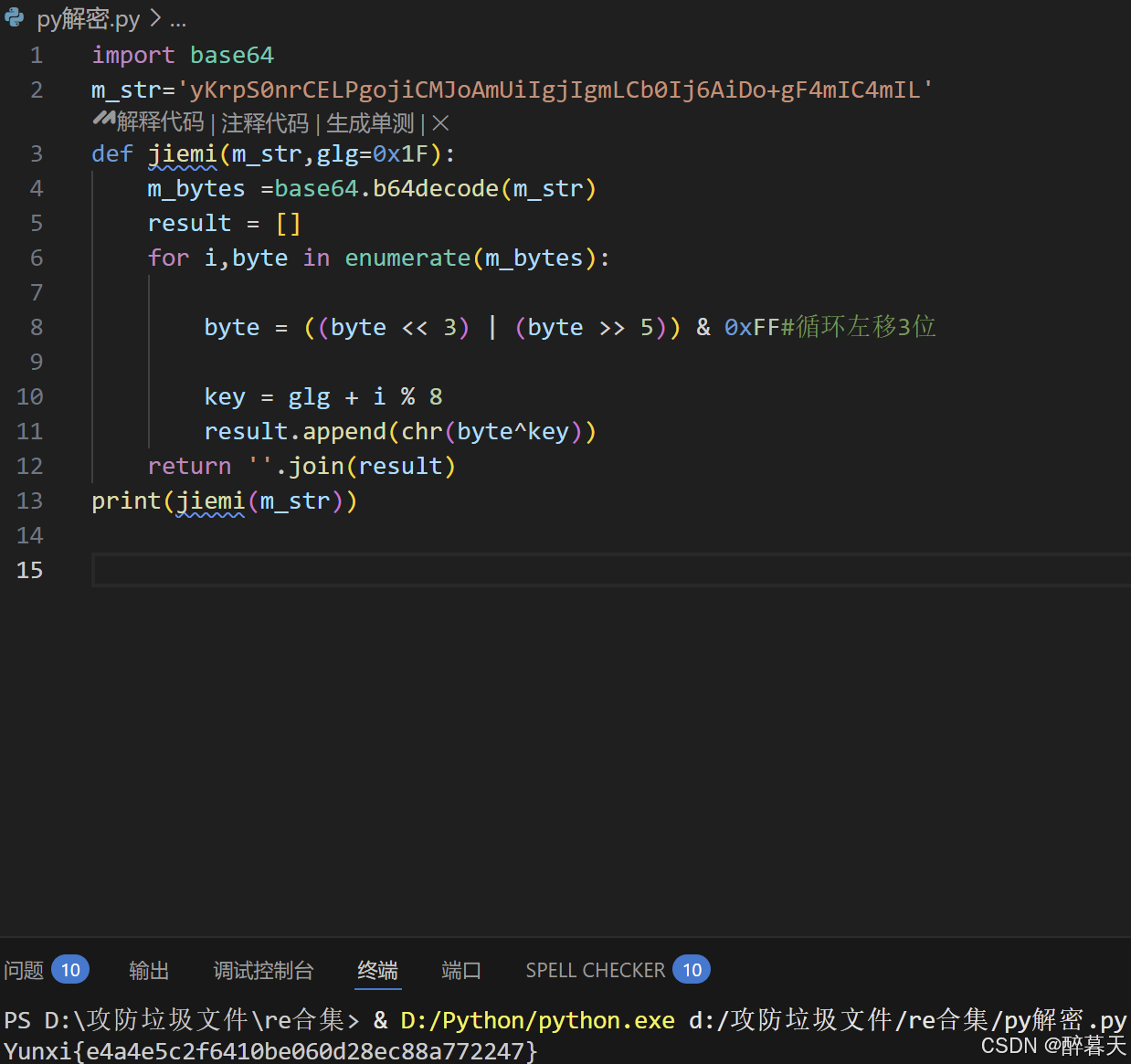


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









