



LSTM+注意力机制,是一种非常热门且有效的处理序列数据的方法,在各顶会顶刊都备受关注!模型Attention-LSTM,便通过该方法,一举拿下Nature子刊!
主要在于,一方面,注意力机制动态分配权重的特点,能够克服LSTM在处理序列数据时,难以有效识别并聚焦于关键信息局限。另一方面,注意力机制通常可以并行计算,与LSTM结合后,这种并行计算能力可以进一步被利用,从而提高整体系统的效率。
目前该方法在时间序列预测、医学图像处理、多模态信息融合等领域都取得了显著效果。像是在轨迹预测中性能飙升47.7%的模型MALS-Net……
为让大家能够获得更多idea启发,落地到自己的文章里,实现高效涨点,我给大家准备了9种创新思路,并对核心内容进行了梳理!
论文原文+开源代码需要的同学看文末
论文:Attention-LSTM based prediction model for aircraft 4-D trajectory
内容
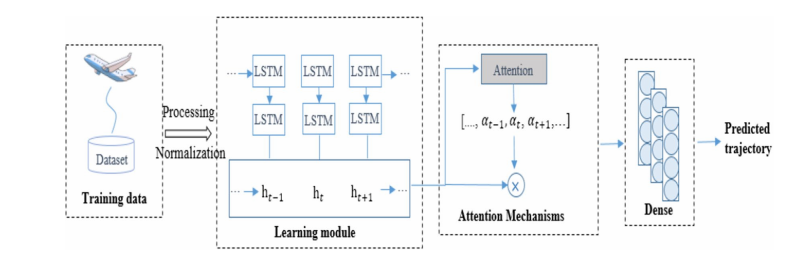
该论文这提出了一种基于注意力机制和长短期记忆网络(LSTM)的飞机4D轨迹预测模型。该模型通过提取飞行轨迹的时间序列特征,并利用注意力机制来增强主要影响因素的作用,从而提高轨迹预测的准确性。
论文:ULDNA: integrating unsupervised multi-source language models with LSTM-attention network for high-accuracy protein–DNA binding site prediction
内容
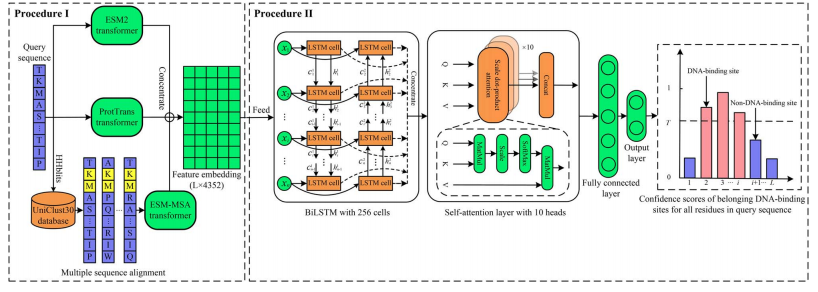
该论文介绍了一种名为ULDNA的新型深度学习模型,用于从蛋白质序列中预测蛋白质-DNA结合位点。该模型结合了三种预训练的无监督蛋白质语言模型和LSTM-注意力网络,通过提取具有进化多样性的特征嵌入来提高预测准确性,证明了其在大规模高精度预测蛋白质-DNA结合位点方面的有效性.
论文:Machine Fault Detection Using a Hybrid CNN-LSTM Attention-Based Model
内容
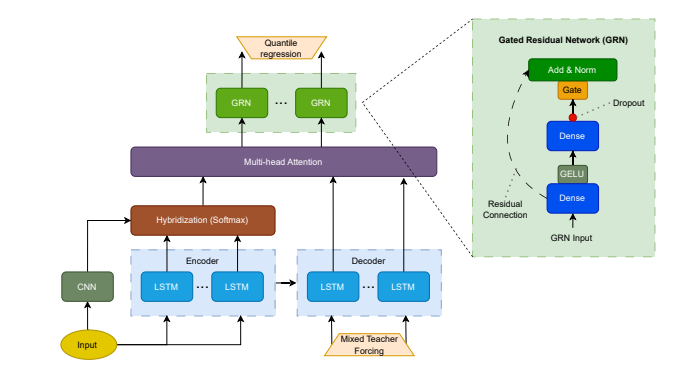
该论文提出了一种基于混合CNN-LSTM注意力模型的机器故障检测方法,用于预测电气设备的潜在故障。该方法通过分析从电气设备上安装的振动传感器收集的时间序列数据,结合分位数回归来管理数据中的不确定性,该模型在预测电气设备故障方面优于传统模型,能够帮助企业优化维护计划,提高设备性能,降低维护成本和停机时间。
论文:A Model for EEG-Based Emotion Recognition: CNN-Bi-LSTM with Attention Mechanism
内容
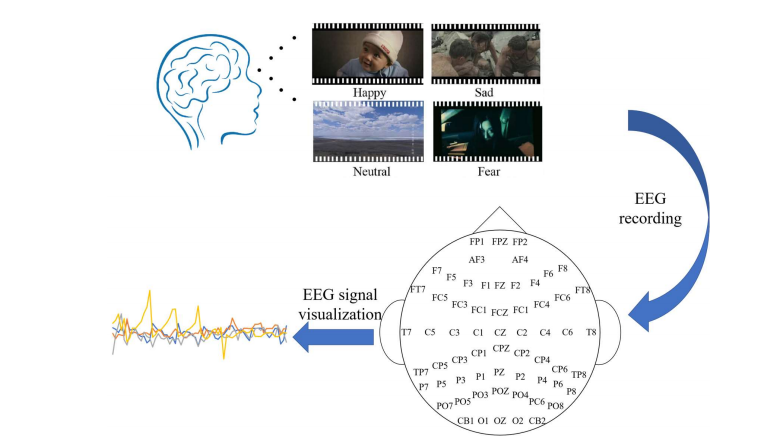
该论文提出了一种基于CNN-Bi-LSTM和注意力机制的深度学习模型,用于基于脑电图(EEG)的情绪识别。该模型通过卷积神经网络(CNN)提取EEG信号的空间特征,双向长短期记忆网络(Bi-LSTM)提取时间特征,并通过注意力机制自动平衡电极通道权重,从而提高情绪分类的准确性。
关注下方《人工智能学起来》
回复“ALSTM”获取全部论文+开源代码
码字不易,欢迎大家点赞评论收藏

















 1752
1752

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









