






4.2.1 什么是过拟合与欠拟合
过拟合:
一个假设在训练数据上能够获得比其他假设更好的拟合,但是在测试数据集上却不能很好地拟合数据,此时认为这个假设出现了过拟合的现象。(模型过于复杂)
欠拟合:
一个假设在训练数据上不能获得更好的拟合,并且在测试数据集上也不能很好地拟合数据,此时认为这个假设出现了欠拟合的现象。(模型过于简单)
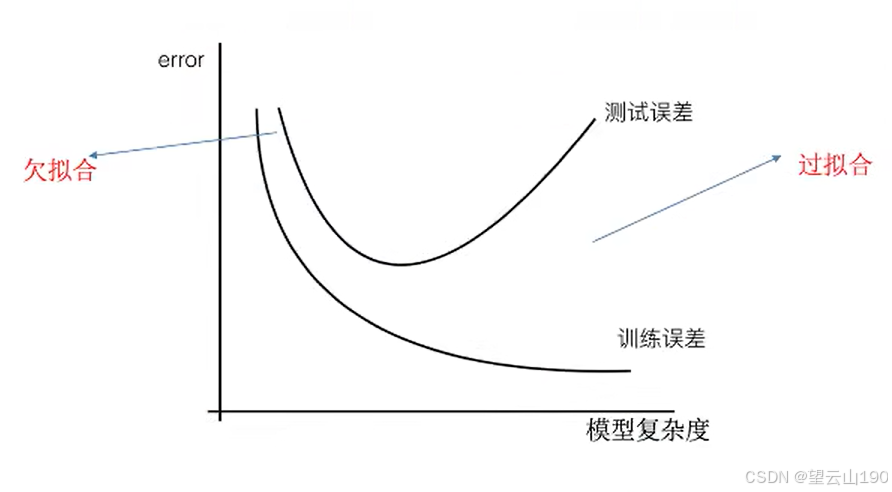
那么是什么原因导致模型复杂?线性回归训练学习的时候编程模型会变得复杂,这里就对应前面再说的线性回归的两种关系,非线性关系的数据,也就是存在很多无用的特征或者现实中的事物特征跟目标值的关系并不是简单的线性关系。
4.2.2 原因以及解决方法
欠拟合原因以及解决办法:
原因:学习到数据的特征过少
办法:增加数据的特征数量
过拟合原因以及解决办法:
原因:原始特征过多,存在一些嘈杂特征,模型过于复杂是因为模型尝试去兼顾各个测试数据点。
办法:正则化
在这里针对回归,我们选择了正则化,但是对于其他机器学习算法如分类算法来说也会出现这样的问题,除了一些算法本身作用之外(决策树,神经网络),我们更多的也是去自己做特征选择,包括之前说的删除,合并一些特征。
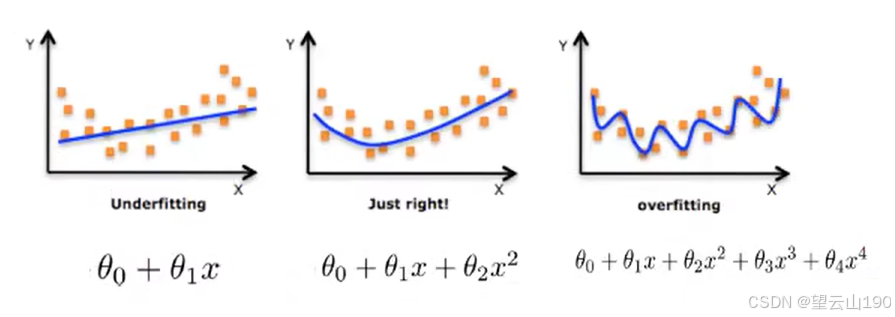
在学习的时候,数据提供的特征有些影响模型复杂度或者这个特征的数据点异常较多,所以算法在学习的时候尽量减少这个特征的影响(甚至删除某个特征的影响),这就是正则化。
1 正则化类别
L2正则化:
作用:可以让其中一些W的都很小,都接近于0,削弱某个特征的影响
优点:越小的参数说明模型越简单,越简单的模型则越不容易产生过拟合现象
又叫Ridge回归--岭回归
加入L2正则化后的损失函数

λ为惩罚系数,λ后面的项称为惩罚项,λ前面的叫做损失函数
L1正则化:
作用:可以让其中一些W的值直接为0,删除这个特征的影响
又叫LASSO回归


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









