






包装类
1.包装类:
基本数据类型对应的引用类型
2.定义:
用一个对象,把基本数据类型给包起来了
3.
| 基本数据类型 | 对应的包装类 |
|---|---|
| byte | Byte |
| short | Short |
| char | Character |
| int | Integer |
| long | Long |
| float | Float |
| double | Double |
| boolean | Boolean |
4.JDk5以后对包装类新增了什么特性
自动装箱和自动拆箱
- 自动装箱:
当编译器发现程序在应该使用包装类对象的地方却使用了自动包装类和自动解包类基本数据类型时,编译器将自动把该数据包装为该基本类型对应的包装类的对象,这个过程叫做自动包装
如类型参数T所接受的是int,double,T所代表的类型自动包装成Integer,Double等类型 - 自动拆箱
当编译器发现程序在应该使用基本类型数据的地方却使用了包装类的对象时,编译器会把该包装类对象解包,从中取出所包含的基本类型数据,这个过程叫做自动解包
如一个对象是包装类型Integer,Double等类型时,,那么可直接将这个元素赋给一个基本类型的变量
5.获取包装类对象
不需要new,不需要调用方法,直接赋值即可
Integer i =10;
Integer成员方法
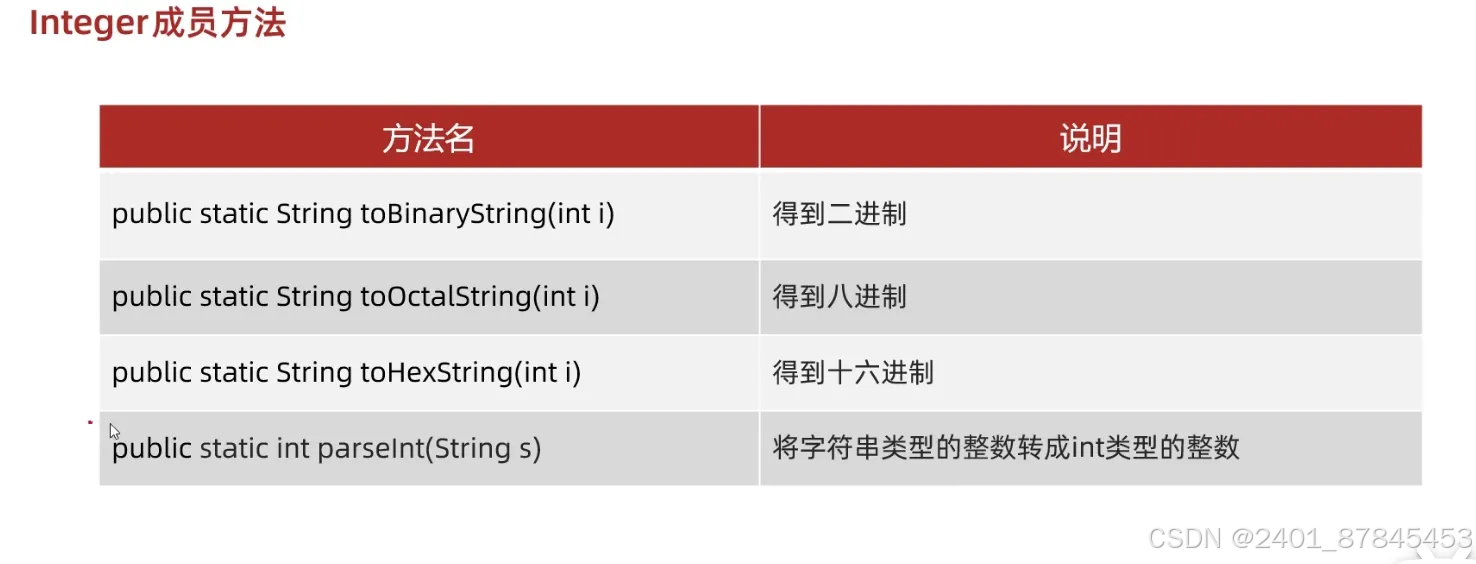
6.转换
- 进制之间的转换
例子:把整数转成二进制,十六进制
String str1=Integer.同Binary String(100);//100
System.out.println(str1);//1100100 - 类型之间的转换
将字符串类型的整数转成int类型的整数 - 强类型语言:每种数据在java中都有各自的数据类型
在计算的时候,如果不是同一种数据类型,是无法直接计算的 - 细节:
- 在类型转换的时候,括号中的参数只能是数字不能是其他,否则代码会报错
- 8种包装当中,除了Character都有对应的parseXxx的方法,进行类型转换
泛型
1.泛型:
是JDK5中引入的特性,可以编译阶段约束操作的数据类型,并进行检查
2实质:
将数据的类型参数化
3.泛型只支持引用数据类型
例子:
ArrayList<Integer>list=new ArrayList<>();
list.add(123);
list.add(456);
list.add(789);
4.优点:
- 统一数据类型,编写的代码可以被多种类型不同的对象所重用,从而减少数据类型转换的潜在错误
- 能够在编译时而不是在运行时检测出错误
- 泛型可以在添加数据的时候就把类型进行统一
5. 没有泛型的时候,集合如何存储数据
结论:
- 如果没有给集合指定类型,默认认为所有的数据类型都是Object类型,此时可以往集合添加任意的数据类型
- 带来一个坏处:我们在获取数据的时候,无法使用他的特有行为
6. 泛型的细节:
- 泛型中不能写基本数据类型
- 指定泛型的具体类型后,传递数据时,可以传入该类类型或者其子类类型 、
- 如果不写泛型,类型默认是Object
7. 泛型还可以在很多方面进行定义
1.泛型类
类后面声明时称为泛型类
- 使用场景:当一个类中,某个变量的数据类型不确定时,就可以定义带有泛型的类
- 创建泛型类对象必须规定类型
格式:修饰符 class 类名<类型>{}
public class ArrayList<E>{}
//此处的E可以理解为变量,但是不是用来记录数据的,而是记录数据的类型,可以写成:T,E,K,V
例子:
public class MyArrayList<E>{
Object []obj=new Object[10];//创建了一个object数组,这个数组将存储添加到的元素
int size;//表示当前列表中实际存储的元素个数
//E:表示是不确定的类型,该类型在类名后面已经定义过了e:形参的名字,变量名
public boolean add(E e){//添加元素的方法
obj[size]=e;//将传入到的元素e存储到obj中,存储的位置是当前size索引后
size++;//每次添加元素后,将size的值+1,以反映列表中元素个数的增加
return true;//添加成功返回true
}
2. 泛型接口
- 接口后面声明时称泛型接口
泛型接口是一种在接口定义中使用类型参数的接口 - 优点:
允许在实现接口或者使用接口时指定的类型,使代码更加灵活和可复用
例子:
interface MyList<T> { //T是类型参数
void add(T element);
T get(int index);
}
两个方法add,get,当你实现这个接口时,可以确定T的具体类型,如果T被指定为String,那么add方法就用于添加字符串
3. 泛型接口的两种使用方式
1)实现类给出具体的类型
(实现类能够确定类型)
2)实现类延续泛型,创建实现类对象时在确定类型
(实现类无法确定类型)
3.接口方法
- 方法上面声明时称泛型方法
-
格式:修饰符<类型>返回值类型 方法名(类型 变量名){} 举例:public<T>void show (Tt){} - 方法中形参类型不确定时
方案1.使用类名后面定义的泛型;所有方法都能用
方案2.在方法申明上定义自己的泛型;只有本方法能用
4. 泛型的继承和通配符
-
泛型不具备继承类,但是数据具备继承类
-
弊端
利用泛型方法有一个小弊端,此时他可以接受任意的数据类型
此时就可以使用泛型的通配符: -
? 表示不确定的类型,它可以进行类型的限定
?extends E:表示可以传递E或者E所有的子类类型
?super E:表示可以传递E或者E所有父类类型 -
使用场景
- 定义类,方法,接口的时候,如果类型不确定,就可以定义泛型
- 如果类型不确定,但能知道是哪个继承体系中的,就可以使用泛型的通配符
注意:
- 一个static方法,无法访问泛型类的类型参数,所以如果satic方法需要使用泛型能力,必须使其成为泛型方法
- 不能使用泛型的类型参数T创建对象
- 在泛型中可以用类型参数T声明一个数组,但不能使用类型参数T创建数组对象
- 异常类不能泛型的,即泛型类不能继承java.lang.Throwable类
泛型方法与泛型类在传递类型实参方面区别 - 对于泛型方法,不需要把实际的类型传递给泛型方法;
但泛型类恰恰相反,即必须把实际的类型参数传递给泛型类
常见算法
基本算法
1. 基本查找:
数据没有任何顺序
从0索引开始挨个往后查找
2. 二分查找/折半查找
- 优势:提高查找效率
- 前提条件:数组中的数据必须是有序的
- 如果数据是乱的,先排序再用二分查找得到的索引没有实际意义,只能确定当前数字在数组中是否存在,因为排序之后数字的位置可能就发生变化了
- 核心逻辑:每次排除一半的查找范围
- 二分查找的过程
1.min和max表示当前要查找的范围
2.mid是在min和max中间的
3.如果要查找的元素在mid的左边,缩小范围时,min不变,max等于mid-1
4.如果要查找的元素在mid的右边,缩小范围时,max不变,mid等于mid+1
例子:
int[]arr={7,23,79,81,127,131};
System.out.println(binarySearch(arr,150));
public static int binarySearch(int[]arr,int number){
int min=0;
int max=arr.length-1;
while(true){
if(min>max){
return-1;
}
int mid =(min+max)/2;
if(arr[mid]>number){
max=mid-1;
}else if(arr[mid]<number){
min=mid+1;
}else{
return mid;
}
}
3.斐波那契查找
- 黄金分割点为 1:0.618
- mid=min+黄金分割点左半边长度-1
- 相同点:都是通过不断的缩小范围来查找对应的数据的
分块查找 - 原则:
- 原则1:前一块中的最大数据,小于后一块中所有的数据(块内无序,块间有序)
- 原则2:块数数量一般等于数字的个数开根号。比如:16个数字一般分为4块左右
- 核心思路:先确定要查找的元素在哪一块,然后在块内挨个查找
4.冒泡排序
- 冒泡排序:相邻的数据两两比较,小的放前面,大的放后面
- 过程:
1. 相邻的数据两两比较,小的放前面,大的放后面
2. 第一轮循环结束,最大值已经找到,在数组的最右边
3. 第二轮循环只要在剩余的元素中招最大就行了
4. 每二轮循环结束,次大值已经确定,第三论循环继续再剩余数据中循环
后面以此类推
5. 如果数组中有n个元素,总共我们只要执行n-1轮的代码就可以
i
int 【】arr={2,4,5,3,1};
for(int i=0;i<arr.length-1;i++){
for(int j=0;j<arr.length-1-i;j++){
if(arr[j]>arr[j+1];j++){
int temp=arr[j];
arr[j]=arr[j+1];
arr[j+1]=temp;
}
}
}
printArr(arr);
}
private static void printArr(int[]arr){
for(int i=0;i<arr.length;i++){
System.out.println( );
}
}
5. 选择排序
选择排序:从0索引开始,拿着每一个索引上的元素跟后面的元素依次比较,小的放前面,大的放后面,以此类推
6. 插入排序
- 插入排序:将0索引的元素到n索引的元素看作是有序的,把n+1索引的元素到最后一个当作是无序的,遍历无序的数据,将遍历到的元素插入有序序列中适当位置,如遇到相同数据,插在后面。
- n的范围:0-最大索引
7. 递归算法
- 递归值得是方法中调用方法本身的现象
- 注意:递归一定要有出口,否则就会出现内存溢出
- 作用:
- 把一个复杂的问题层层转化为一个与原问题相似的规模较小的问题来求解
- 递归策略只需少量的程序就可以描述出解题过程所需要的多次重复计算
- 书写递归的两个核心
找出口:什么时候不在调用方法
找规律:如何把大问题变成规模较小的问题
核心:方法内部再次调用方法的时候,参数必须要更加靠近出口
8. 快速排序
1.过程:
- 把0索引的数字作为基准数,确定基准数在数组中正确的位
- 比基准数小的全部在左边,比基准数大的全部在右边
- 将排序范围中的第一个数字作为基准数,在定义两个变量start,end
Arrays
- 操作数组的工具类
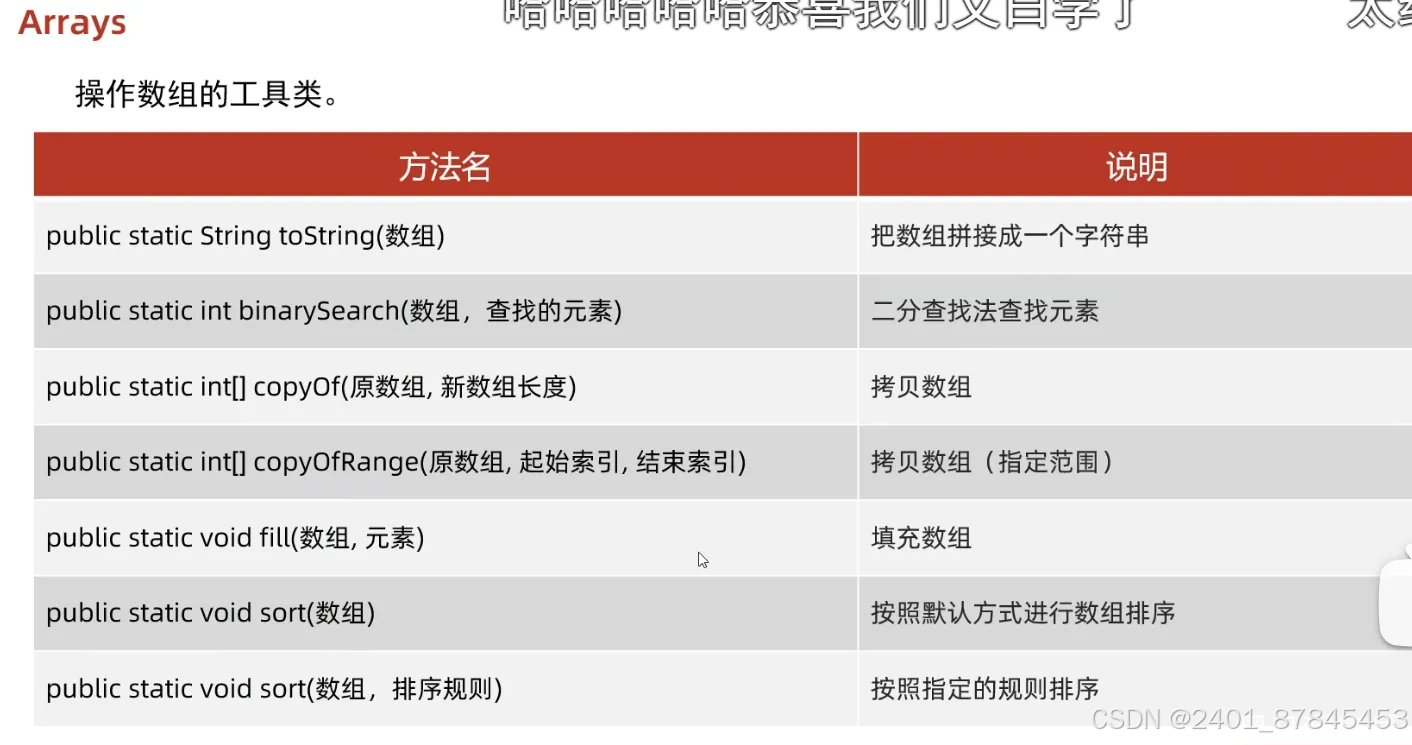
例子
toString:
System.out.println(Arrays.toString(arr) );
binarySearch
{1,2,3,4,5,6,7,8,9}
- 细节:如果查找的数据是不存在的,那么返回的是-插入点-1
- 为什么会减一
如果要查找数字0,此时0是不存在的,如果返回值是-插入点,应该是-0,就会出现问题,为了避免这样的情况,会在此基础上减一
System.out.println(Arrays.binarySearch(arr,20) );
copyOf:
int[]newArr1=Arrays.toString(arr,9);
System.out.println(Arrays.toString(newArr1) );
- 细节:
- 参数1:老数组
- 参数2:新数组的长度
- 底层会根据第二个参数来创建新的数组
- 如果新数组的长度是小于老数组的长度,会部分拷贝
如果新数组的长度等于老数组的长度,会完全拷贝
如果新数组的长度是大于老数组的长度,会补上默认初始值 0
copyOfRange:
- 细节:包头不包围,包左不包右
int[]newArr2=Arrays.toString(arr,0,9);
System.out.println(Arrays.toString(newArr2) );//【1,2,3,4,5,6,7,8】
fill:
Arrays.fill(arr,100);
System.out.println(Arrays.toString(arr) );
sort:
int[]arr2={10,2,3,5,6,7,1,8,4,9,}
Arrays.sort(arr2);
System.out.println(Arrays.toString(arr2) );
void sort
参数1:要排序的数组
参数2:排序的规则
2. 细节:
- 只能给引用数据类型的数组进行排序
- 如果数组是基本数据类型,需要变成其对于的包装类
Lambda
- Lambda表达式是jdk8后开始的一种新语法形式
-
格式:()->{ } 。()对应着方法的形参 。->固定格式 。{}对应着方法的方法体 - 注意:Lambda表达式可以用来简化匿名内部类的书写
Lambda表达式只能简化函数式接口的匿名内部类的写法
函数式接口:有且仅有一个抽象方法的接口叫做函数式接口,接口上方可以加@Functionallnterface - 好处:Lambda是一个匿名函数,我们可以把Lambda表达式理解为是一段可以传递的代码,它可以写出更简洁,更灵活的代码,作为一种更紧凑的代码风格,提升java语言
- Lambda的省略规则
- 参数类型可以省略不写
- 如果只有一个参数,参数类型可以省略,同时()也可以省略
- 如果Lambda表达式的方法体只有一行,大括号,分号,return可以省略不写,需要同时省略
- Lambda完整格式
Arrays.sort(arr,(Integer o1,Integero2)->{
return o1-o2;
}
);
- Lambda省略写法
Arrays.sort(arr,(o1-o2)->o2-o1);
简写格式:小括号:数据类型可以省略,如果参数只有一个,小括号还可以省略
大括号:如果方法体只有一个,return,分号,大括号都可以省略
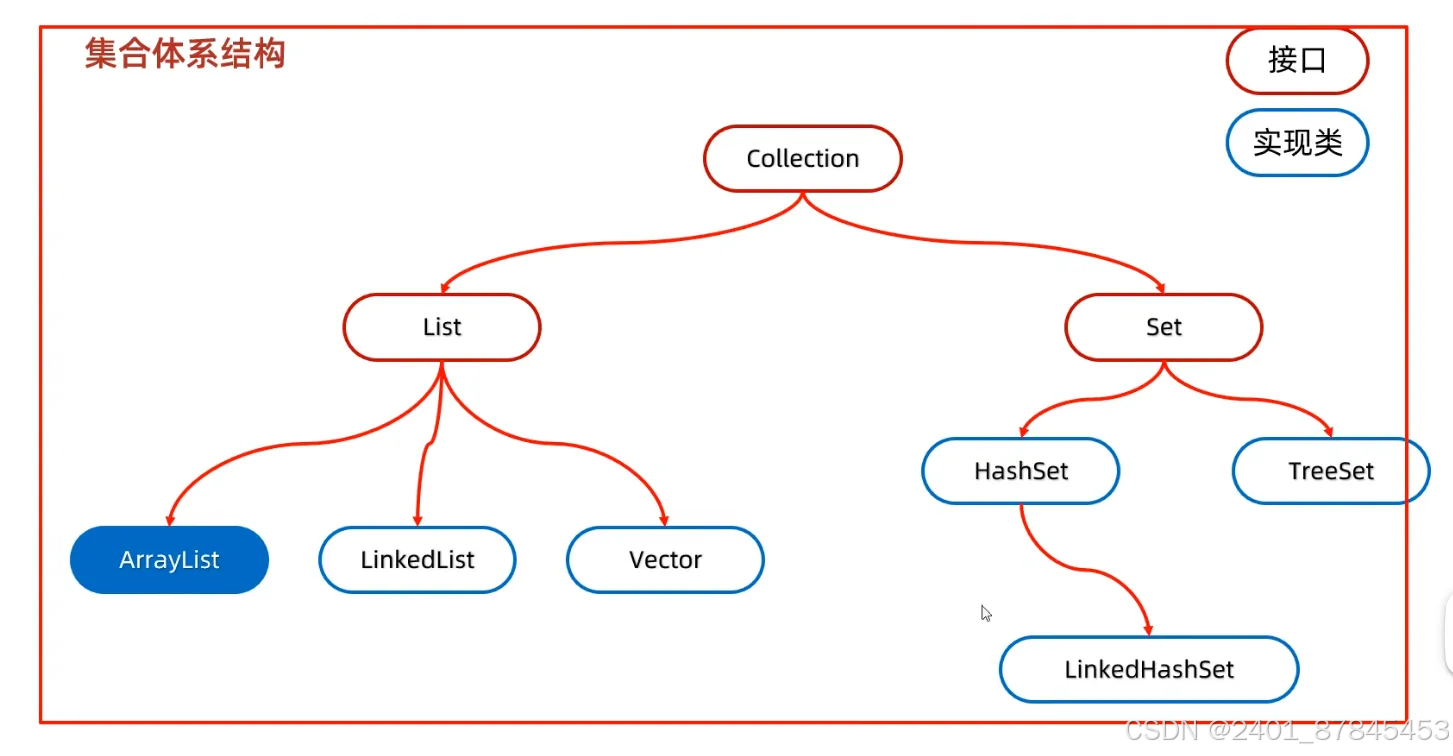
集合体系结构
Collection:单列集合
- Collection是单列集合的祖宗接口,它的功能是全部单列集合都可以继承使用的
- Collection是一个接口,我们不能直接创建他的对象,所以只能创建实现类的对象
(实现类:ArrayList)、 - 包括:
1.list系列集合
添加的元素是有序,可重复,有索引
2.set系列集合
添加的元素是无序,不重复,无索引
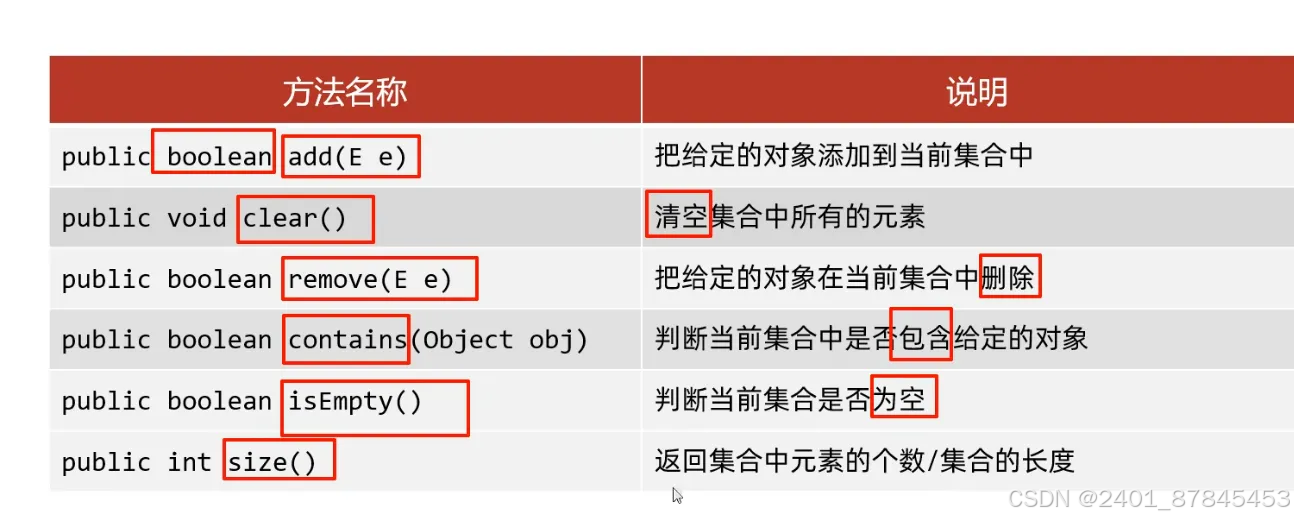
- 方法:
- 添加
- 细节1:如果我们往List系列中添加数据,那么方法永远返回true,因为List系列是允许元素重复的
- 细节2:如果我们往 Set系列集合中添加数据,如果添加的元素不存在,返回true,表示添加成功。
- 如果当前要添加的元素已经存在,方法返回false,表示添加失败。因为Set系列的集合不允许重复
- 删除:
- 细节1:因为Collection里面定义的是共性的方法,因此不能通过索引进行删除,只能通过元素的对象进行删除
- 细节2:方法会有一个布尔类型的返回值,删除成功返回true,删除失败返回false
- 如果要删除的元素不存在,就会删除失败
- 判断元素是否包含
- 细节:底层是依赖equals方法进行判断是否存在的
- 如果集合中存储的是自定义对象,也想通过contains方法来判断是否包含,那么在javabean类中,一定要重写equals方法
Map:双列集合
- Collection的遍历方式
迭代器遍历
增强for遍历
Lambda表达式遍历
迭代器遍历
- 迭代器在遍历集合的时候是不依赖索引的
- 迭代器在java中的类是Iterator,迭代器是集合专用的遍历方法
- Collection集合获取迭代器

Iterator<String>it=list.iterator();
while(it.hasNext()){
String str=it.next();
System.out.println(str);
}
- 细节注意点:
- 报错NoSuchElementException
- 迭代器遍历完毕,指针不会复位
- 循环只能用一次next方法
- 迭代器遍历时,不能用集合的方法进行增加或者减
增强for的底层
- 增强for的底层就是迭代器,为了简化迭代器的代码书写的
- 它是jdk5之后出现的,其内部原理就是一个Iterator迭代器
- 所有的单列集合和数组才能用增强for进行遍历
-
格式: for(数据类型 变量名:集合/数组){ }
- 快速生成方式:集合的名字+for 回车
- 细节:修改增强for中的变量,不会改变集合中原本的数据
Lambda表达式遍历


迭代器:
- 在遍历的过程中需要删除元素,请使用迭代器
- 仅仅想遍历,那么增强for或Lambda表达式
数据结构

二叉树(tree)
-
度:每一个节点的子节点数量
(二叉树中,任意节点的度<=2) -
根节点:最顶层的节点
-
左子节点:左下方的节点
-
右子节点: 右下方的节点
-
根节点的左子树:蓝色虚线
-
根节点的左子树:蓝色虚线
-
根节点的右子树:绿色虚线
-
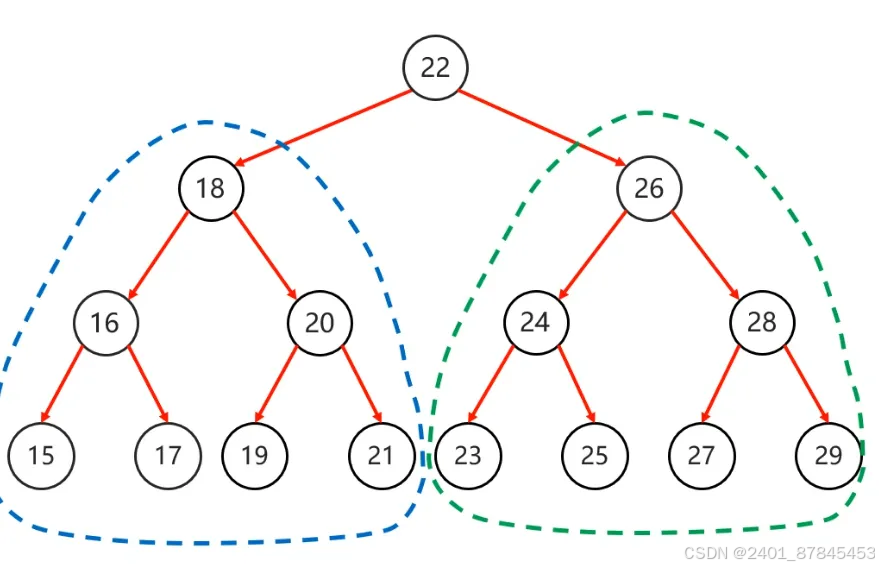
-
二叉树遍历方式:
- 前序遍历:当前节点,左子节点,右子节点
- 中序遍历;左子节点,当前节点,右子节点
- 后序遍历:左子节点,右子节点,当前节点
- 层序遍历:一层一层的去遍历二叉查找树
二叉查找树
- 二叉查找树,又称二叉排序树或者二叉搜索数
- 特点:
1. 每一个节点上最多有两个子节点
2. 任意节点左子树上的值都小于当前节点
3. 任意节点右子树上的值都大于当前节点 - 添加节点的规则
小的存左边,大的存右边,一样的不存
平衡二叉数
规则:任意节点左右字数高度差不超过1
set系列集合
- 特点
无序:存取顺序不一致
不重复:可以去除重复
无索引:没有带索引的方法,所以不能使用普通for循环遍历,也不能通过索引获取元素 - set集合的实现类
HashSet:无序,不重复,无索引
LinkHashSet:有序,不重复,无索引
TreeSet:可排序,不重复,无索引
- set接口中的方法上基本上与Collection的API一致
-
哈希表
哈希表是一种对于增删改查数据性能都较好的结构 -
hashset集合的底层数据结构
Jdk8之前:数组+链表
jdk8开始:数组+链表+红黑树
红黑树
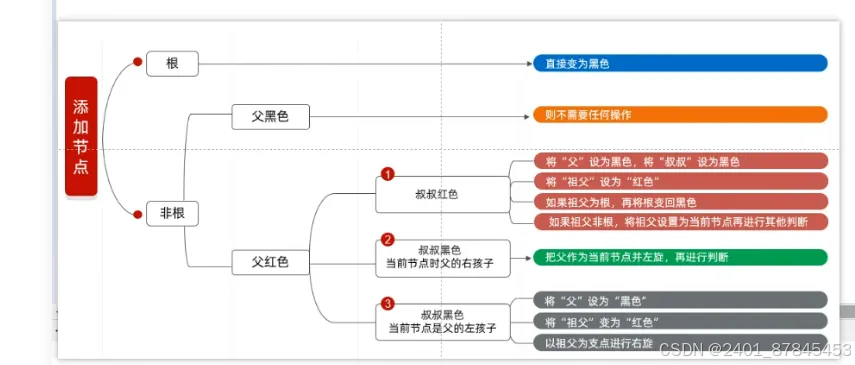
-
哈希值:
- 对象的整数表现形式(根据hashCode方法算出来的int类型的整数)
- 该方法定义在Object类中,所有对象都可以调用,默认使用地址值进行计算
- 一般情况下,会重写hashCode方法,利用对象内部的属性值计算哈希值
int index=(数组长度-1)&哈希值
-
对象的哈希值特点
- 如果没有重写hashCode方法,不同对象计算出的哈希值是不同的
- 如果已经重写hashCode方法,不同对象只要属性值相同,计算出的哈希值就是一样的
- 在小部分情况下,不同的属性值或者不同的地址值计算出来的哈希值也有可能一样
(哈希碰撞)
-
加载因子:哈希code的扩容时机
默认长度为16,默认加载因子为0.75的数组
当数组长度为16*0.75时,就会发生扩容
HashSet底层原理
- 创建一个默认长度16,默认加载因子为0.75的数组,数组名为table
- 根据元素的哈希值跟数组的长度计算出应存入的位置
- 判断当前位置是否为null,如果是null直接存入
如果位置不为null,表示有元素,则调用equals方法比较属性值 - 一样:不存
不一样:存入数组,形成链表 - Jdk8之前:新数组存入数组,老数组挂在新数组下面
jdk8以后:新数组直接挂在老元素下面 - 注意:jdk8以后,当链表长度大于等于64时,自动转换为红黑树
- 如果集合中存储的是自定义对象,必须重写hashCode和equals方法
- hashset利用什么机制保证去重的
HashCode方法:得到哈希值->数值添加到哪个位置
equals方法:比较对象内部的属性值
LinkedHashSet
- 集合的特点
有序,不重复,无索引 - 原理:底层基于哈希表,使用双链表记录添加顺序
- 在以后如果要数据去重,我们使用那个?
默认使用HashSet - 如果要求去重且存取有序,才使用LinkedHashSet
TreeSet集合默认的规则
- 对于数值类型:Integer,Double,默认按照从小到大的顺序进行排序
- 对于 字符,字符串:按照字符在ASCII码表中的数字升序进行排序
- 底层结构:红黑树
- 接口里的实现方法指定排序规则
例子:
public int compare(Student o){
return this.getAge()-o.getAge();
}
- this:表示当前要添加的元素
o:表示已经在红黑树存在的元素 - 返回值:
负数:认为要添加的元素是小的,存左边
正数:认为要添加的元素是大的,存右边
0:认为要添加的元素已经存在,舍弃 - TreeSet的两种比较方式
方式1:默认排序/自然排序:javabean类实现Comparable接口指定比较规则
方式2:比较器排序:创建你TreeSet对象时候 ,传递比较器Comparator指定规则 - 使用原则:默认使用第一种,如果第一种不能满足当前需求,就使用第二种
如果两种方式都存在,以第二种为准
红黑树:
使用场景:
- 如果想要集合中的元素可重复
用ArrayList集合,基于数组的(用的最多) - 如果想要集合中的元素可重复,而且当前的增删操作明显多于查询
用ListsdList集合,基于链表的 - 如果想对集合中的元素去重
用hashset集合,基于哈希表(用的最多) - 如果想对集合中的元素去重,而且保证存取数据
用ListedHashSet集合,基于哈希表和双链表,效率低于HashSet - 如果想对集合中的元素进行排序
用TreeSet集合,基于红黑树,后续也可用List集合实现排序



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









