






认识Hadoop
既然是要借鉴设计,自然也就需要我们先对Hadoop来细细地“盘”一下,毕竟工欲善其事必先利其器。那么,就让我来用很多人都做过的图书管理系统来帮大家梳理一下。
1.Hadoop本身:图书馆管理系统
想象你是一家超大型图书馆的馆长,这个图书馆有成千上万的书籍,Hadoop就是一个强大的管理系统,可以帮助你有效地存储、管理和处理这些书籍的信息。
那么作为管理这些图书的Hadoop此时就面临着两个关键问题需要解决:
- 如何存储大量书籍(相当于海量数据)
- 如何快速找到、处理这些书籍的信息(相当于对数据进行计算和分析)。
为了实现这两个目标,Hadoop就引入了HDFS和 MapReduce,它们分别负责存储和处理数据。
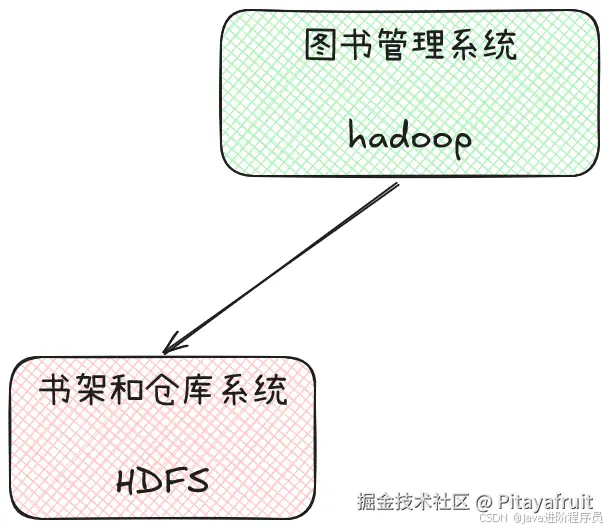
2.HDFS:图书馆的书架和仓库系统
HDFS(Hadoop Distributed File System)负责数据存储,就像图书馆中的书架和仓库系统,负责存储所有的书籍。
它的存储方式结合图书馆具有以下几个特点:
-
分布式存储:图书馆的书架并不是集中在一个房间里,而是分布在多个房间(节点)中,每个房间只存储一部分书籍。类似地,HDFS 会将文件切分为多个数据块,分别存储在不同的节点上。
-
数据块与分片存储:如果某本书非常厚,图书馆会将它 分成多个部分(数据块),分别存放在不同的房间(节点)中。这样可以加快数据的并行读取,同时避免单个节点的存储压力。HDFS 采用相同的策略,将大文件切分为多个块存储在不同的机器上。
-
冗余备份与容错性:为了避免某个房间的书架损坏(节点故障)导致书籍丢失,图书馆会将重要的书籍(数据块)复制多份,并存储在不同的房间中。这样,即使某个节点出现故障,仍然可以从其他节点恢复数据。
-
数据管理者:NameNode 与 DataNode:
1.NameNode:相当于图书馆的馆长,负责管理所有书籍的目录和位置信息。馆长不会亲自存储书籍,但他知道每本书在哪个房间的哪个书架上(即元数据)。
2.DataNode就像是图书馆中的房间管理员,负责实际存储书籍(数据块)。每个房间的管理员只知道自己管理的书籍,而不关心其他房间的情况。
3.MapReduce:图书馆的任务分配系统
在图书馆的管理系统中,除了需要分布式存储书籍外,还需要对这些书籍进行查询、统计和分析工作。为了高效处理这些任务,图书馆采用了MapReduce来对任务进行分配。这个系统通过将任务拆分为多个步骤,并行分配给不同的管理员(节点),从而加快任务的执行速度。
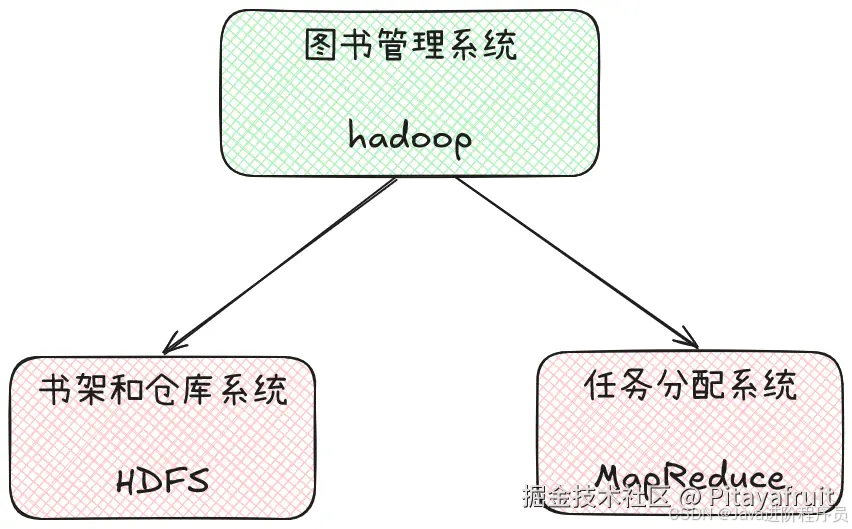
MapReduce主要分为两个阶段:Map阶段和Reduce阶段。
3-1.Map阶段(映射阶段)
假设你想知道图书馆里每本书的借阅次数。图书馆不会让一个管理员去统计所有书籍的借阅信息,而是将统计任务分配给多个房间的管理员。每个管理员只负责统计自己房间内的书籍借阅情况,并生成一个中间结果。这就是 Map阶段:每个节点负责处理自己存储的数据,生成键值对结果。
对应到实际的Hadoop系统中,Map阶段会将大规模的数据集分成多个小块,由不同的节点并行处理。每个节点负责处理自己的一部分数据,并输出中间的键值对结果。
3-2.Reduce阶段(归约阶段)
当每个房间的管理员将统计结果交给馆长后,馆长会将这些结果汇总,得到整个图书馆的借阅统计信息。这就是 Reduce 阶段:汇总Map阶段生成的键值对,得到最终的统计结果。
在 Hadoop 中,Reduce 阶段会接收来自多个Map任务的中间结果,并对这些结果进行汇总或聚合,最终生成用户所需要的输出结果。
3-3.并行与容错
每个房间的管理员可以同时统计各自房间书籍的数量,如果某个房间管理员今天请假了没来,馆长也会为这个房间指定一个临时管理员来接手任务。
MapReduce的最大优势在于它的并行处理能力。由于每个节点可以独立地处理自己的一部分数据,整个任务可以被拆分为多个小任务并行执行,这极大提高了任务的处理速度。此外,若某个节点在执行任务时发生故障,MapReduce系统能够自动重新分配任务,确保整个作业的顺利完成。
而这些也是我们今天需要实现的点。
技术实现
Hadoop在本地安装后,可以以两种模式运行,分别是本地模式和伪分布式模式。在本地模式下,它会在单个 JVM 实例中运行,不依赖于 HDFS、YARN 或 MapReduce。所有的计算都在本地机器的文件系统上进行。因此,更适合我们此时的快速开发和测试。当然,别忘了引入相关依赖:
xml
代码解读
复制代码
<dependencies> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>3.3.6</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-mapreduce-client-core</artifactId> <version>3.3.6</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-mapreduce-client-app</artifactId> <version>3.3.6</version> </dependency> </dependencies>
实现MapReduce任务
首先,我们先通过Java实现一个简单的任务-统计一段文本中的单词出现次数。首先先来实现map接口,还记得我们前面提到的map阶段是各个节点处理自己的数据。在当前的任务下,就是对文本进行分词统计即可,代码如下:
java
代码解读
复制代码
import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> { private final static IntWritable one = new IntWritable(1); private Text word = new Text(); @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String[] words = value.toString().split("\s+"); for (String w : words) { word.set(w); context.write(word, one); } } }
map实现后,我们接下来继续reduce阶段,来汇总Mapper产生的中间结果,将相同单词的频次加起来。
java
代码解读
复制代码
import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> { private IntWritable result = new IntWritable(); @Override protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int sum = 0; for (IntWritable val : values) { sum += val.get(); } result.set(sum); context.write(key, result); } }
最后是编写我们的任务入口,负责配置并提交MapReduce作业
java
代码解读
复制代码
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class WordCountJob { public static void main(String[] args) throws Exception { if (args.length != 2) { System.err.println("Usage: WordCountJob <input path> <output path>"); System.exit(-1); } Configuration conf = new Configuration(); Job job = Job.getInstance(conf, "Word Count"); job.setJarByClass(WordCountJob.class); job.setMapperClass(WordCountMapper.class); job.setReducerClass(WordCountReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); System.exit(job.waitForCompletion(true) ? 0 : 1); } }
我们准备一个txt文本,用我们的作业简单测试下效果,如下:
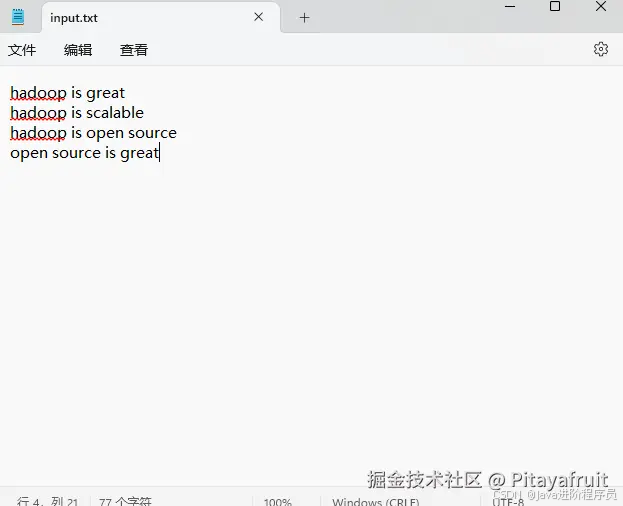
运行计数作业后,输出结果如下:
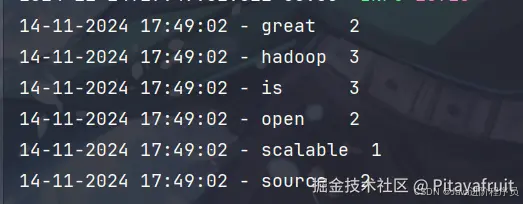
可以看到,我们这个简单的MapReduce任务就实现了。
更多的格式支持
在上面的例子里,我们用一个txt文本进行了测试。但在实际业务场景中,我们可能遇到更多形式的数据,因此,就需要我们在解析时能够支持多种数据格式,这里我们先以CSV和JSON为例,为了处理它们,我们先导入相关依赖,如下:
java
代码解读
复制代码
<!-- Apache Commons CSV --> <dependency> <groupId>org.apache.commons</groupId> <artifactId>commons-csv</artifactId> <version>1.9.0</version> </dependency> <!-- Jackson (用于解析JSON) --> <dependency> <groupId>com.fasterxml.jackson.core</groupId> <artifactId>jackson-databind</artifactId> <version>2.14.0</version> </dependency>
有了依赖的加持,我们可以通过便捷的api实现对csv和json数据的解析,把它们集成到map阶段,代码如下:
java
代码解读
复制代码
import org.apache.commons.csv.CSVFormat; import org.apache.commons.csv.CSVParser; import org.apache.commons.csv.CSVRecord; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; import java.io.StringReader; public class CSVWordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> { private final static IntWritable one = new IntWritable(1); private Text word = new Text(); @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { // 使用Apache Commons CSV解析输入行 String line = value.toString(); CSVParser parser = CSVFormat.DEFAULT.parse(new StringReader(line)); for (CSVRecord record : parser) { for (String field : record) { word.set(field.trim()); context.write(word, one); } } } }
java
代码解读
复制代码
import com.fasterxml.jackson.databind.JsonNode; import com.fasterxml.jackson.databind.ObjectMapper; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; public class JSONWordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> { private final static IntWritable one = new IntWritable(1); private Text word = new Text(); private ObjectMapper objectMapper = new ObjectMapper(); @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { // 使用Jackson解析JSON String jsonString = value.toString(); JsonNode jsonNode = objectMapper.readTree(jsonString); // 假设我们要处理的字段是 "text" String text = jsonNode.get("text").asText(); String[] words = text.split("\s+"); for (String w : words) { word.set(w.trim()); context.write(word, one); } } }
但这里我们这里需要考虑扩展性,以后有更多格式的数据,需要怎么办?来吧,掏出我们的工厂模式,先创建一个通用工厂,如下:
java
代码解读
复制代码
public class MapperFactory { public static Class<? extends Mapper> getMapperClass(String format) { switch (format.toLowerCase()) { case "csv": return CSVWordCountMapper.class; case "json": return JSONWordCountMapper.class; default: return WordCountMapper.class; // 默认文本文件格式 } } }
然后再修改WordCountJob 来动态选择 Mapper,可以通过命令行参数或者配置文件来动态选择,代码如下:
java
代码解读
复制代码
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class WordCountJob { public static void main(String[] args) throws Exception { if (args.length != 3) { System.err.println("Usage: WordCountJob <input path> <output path> <format: text|csv|json>"); System.exit(-1); } String inputPath = args[0]; String outputPath = args[1]; String format = args[2]; // 获取输入格式 Configuration conf = new Configuration(); Job job = Job.getInstance(conf, "Word Count"); job.setJarByClass(WordCountJob.class); // 根据输入格式动态设置Mapper job.setMapperClass(MapperFactory.getMapperClass(format)); job.setReducerClass(WordCountReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); FileInputFormat.addInputPath(job, new Path(inputPath)); FileOutputFormat.setOutputPath(job, new Path(outputPath)); System.exit(job.waitForCompletion(true) ? 0 : 1); } }
这样,以后再有新的格式也就可以轻松扩展了。
性能调优
能够完成基本任务是远远不够的,现在我们就需要考虑性能优化。关于它的调优是一个多维度的过程,核心目标就是最大化利用集群资源,减少网络传输和I/O操作,确保任务在大规模数据环境下高效运行。 比如,合理配置Mapper和Reducer的数量、使用Combiner减少数据传输、调整Shuffle阶段的参数等等。我们这里就不泛泛而谈了,围绕我们上面的代码讲两个优化思路。
减少中间数据传输
Combiner可以在Mapper端对数据进行局部汇总,减少传递给Reducer的中间数据量。我们当前的单词统计任务就很适合用Combiner,如下:
java
代码解读
复制代码
job.setCombinerClass(WordCountReducer.class); // 将Reducer类作为Combiner
这样,Mapper输出的数据会局部汇总后再传给Reducer,显著减少网络传输量,尤其是在处理大量数据时提升更为明显。
数据倾斜问题调优
对于单词统计任务,可能一个文本里某些单词出现的频率远高于其他单词,这样就可能导致某些Reducer的负载过重,也就是我们说的数据倾斜。它会导致某些Reducer接收到的数据远多于其他Reducer,进而导致整个作业的执行时间拖长。对于这个问题,我们的解决策略就是自定义 Partitioner 来更均匀地分配数据,代码如下:
java
代码解读
复制代码
import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Partitioner; public class CustomPartitioner extends Partitioner<Text, IntWritable> { @Override public int getPartition(Text key, IntWritable value, int numReduceTasks) { // 根据单词的首字母来进行分区 char firstChar = key.toString().toLowerCase().charAt(0); if (firstChar >= 'a' && firstChar <= 'm') { return 0; // 分配给Reducer 0 } else { return 1; // 分配给Reducer 1 } } }
然后,在作业中设置自定义 Partitioner,代码如下:
java
代码解读
复制代码
job.setPartitionerClass(CustomPartitioner.class); // 使用自定义Partitioner
这种方式可以避免某些高频单词集中在同一个Reducer,导致的数据倾斜。
小结
本篇文章主要讲述如何实现一个基础的MapReduce作业,对于输入的数据的扩展性与任务性能调优也实现了一些方法,但在实际业务场景中,肯定远不止这些,更多时候需要结合实际去优化。目前在大数据领域,Hadoop仍然是一个重要的工具,对于Java程序员来说,如果有意扩展自己的边界向大数据领域发展,Hadoop还是很值得我们去学习的。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









