







1.
1.TensorFlow的实现
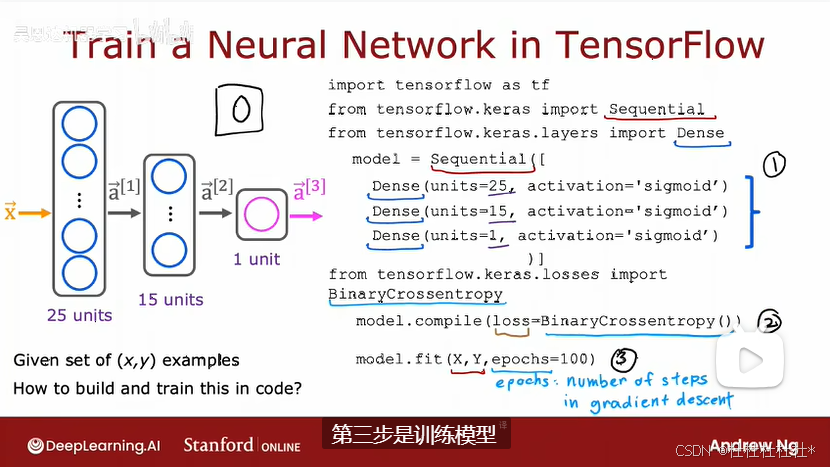
第一步是指定告诉TensorFlow你的模型
第二步用特定的损失函数编译模型,是要求TensorFlow编译模型,关键步骤是指定使用的损失函数(范畴交叉熵)
第三步训练模型,是调用fit函数,它告诉TensorFlow拟合在步骤一中使用损失指定的模型或者再第二步中指定的数据集x y的成本函数(圈3处100是要运行多少步)
2.训练细节
步骤 


2.
1.sigmoid的替代品
relu和线性激活函数
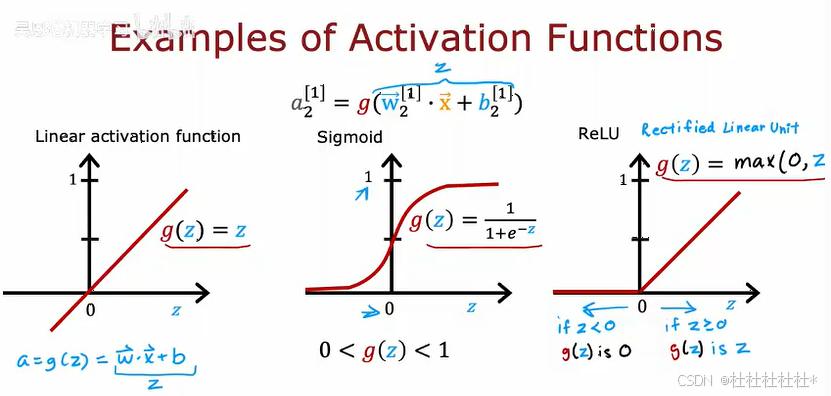
2.选择激活函数
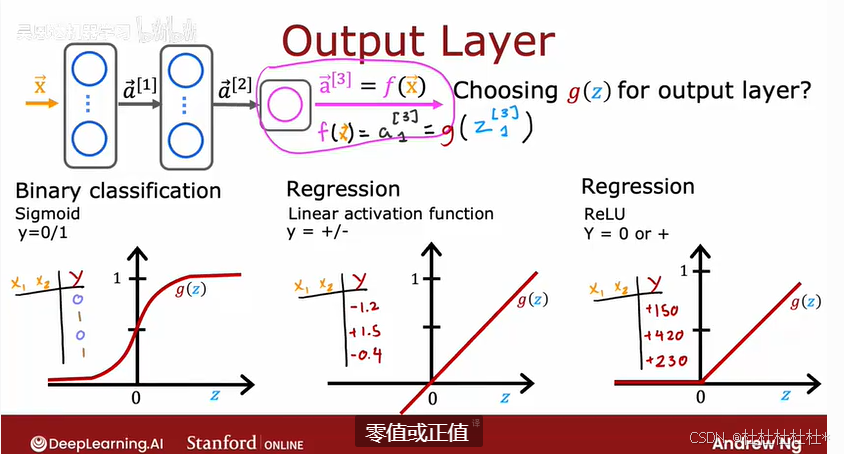
取决于标签y的具体目标
输出层:
隐含层:建议relu
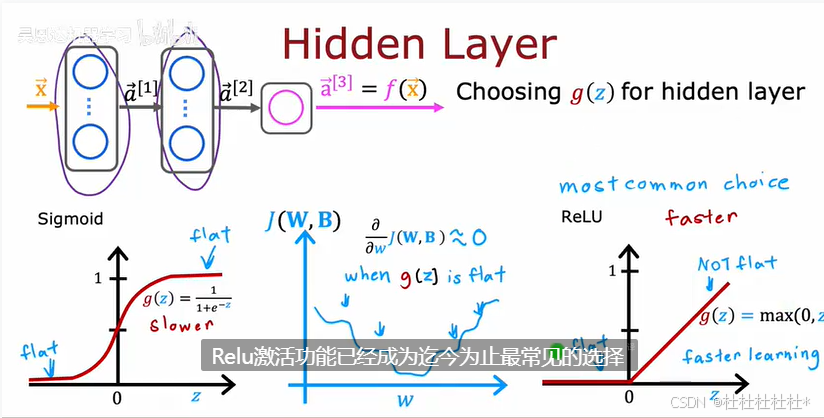
总结:

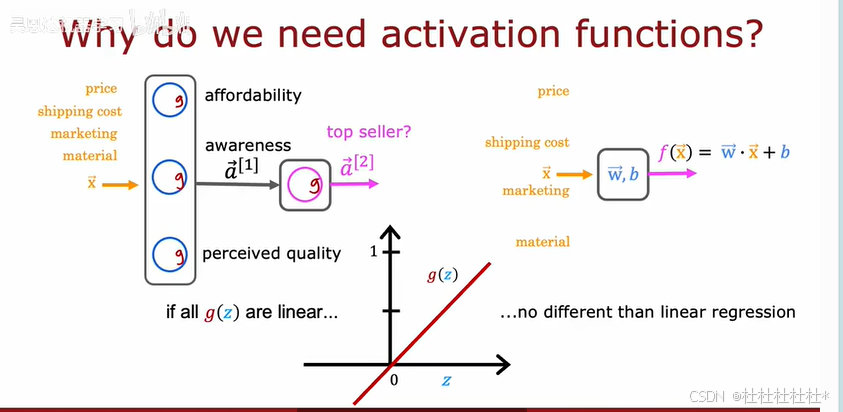
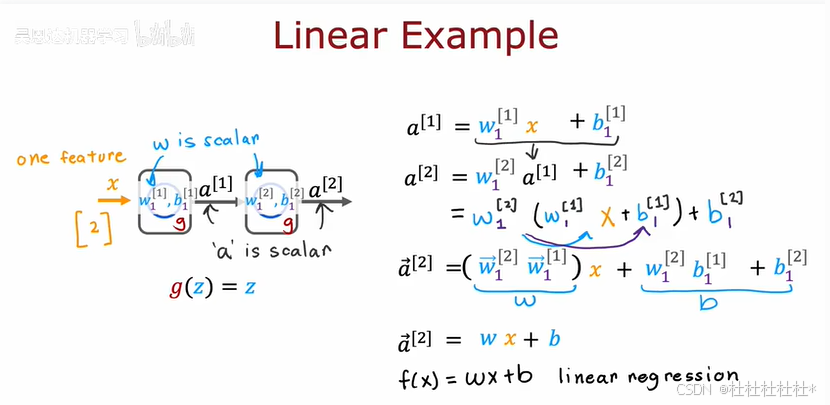
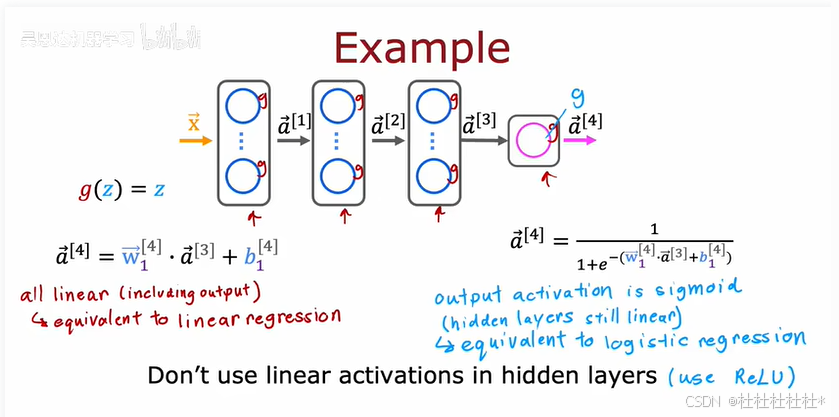
3.为什么我们需要激活函数
神经网络需要激活函数,因为线性激活函数无法拟合更复杂的数据。神经网络使用激活函数可以拟合复杂的非线性关系。激活函数可以应用于分类和回归问题。
3.
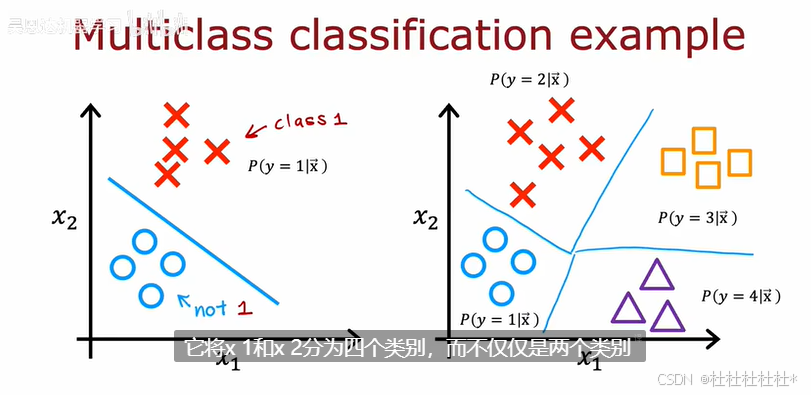
1.多类
多类分类:有多个输出的分类问题

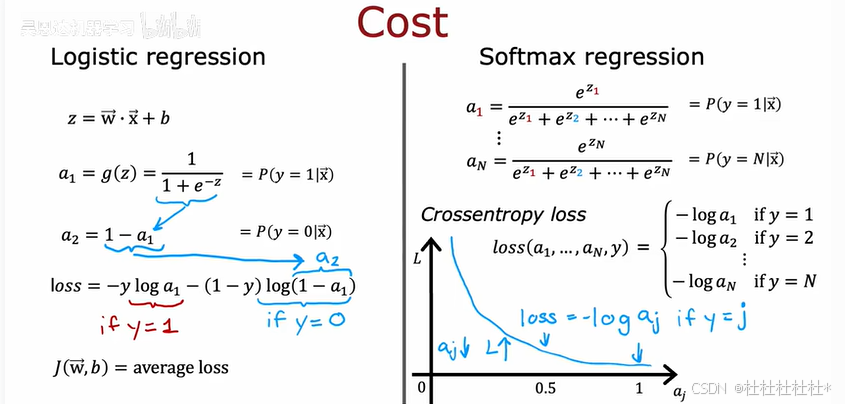
2.softmax回归算法
用于多类分类问题

损失函数
3.神经网络的softmax输出
用softmax建立一个能进行多类分类问题的神经网络(用于输出层)
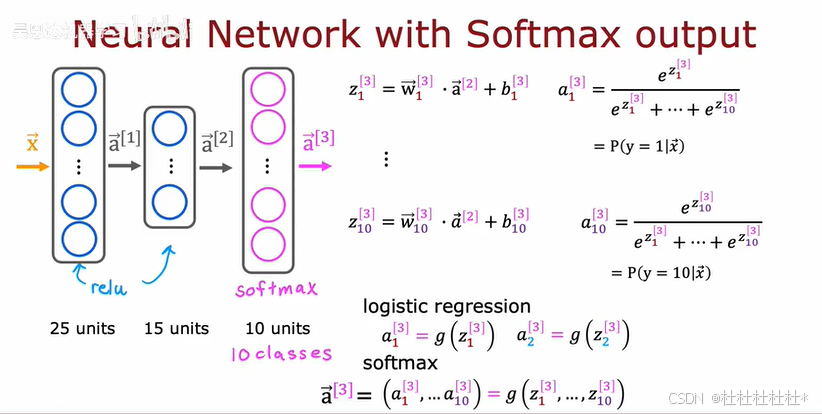
步骤
4.softmax改进

两种方式表达含义相同,但softmax计算产生了误差。
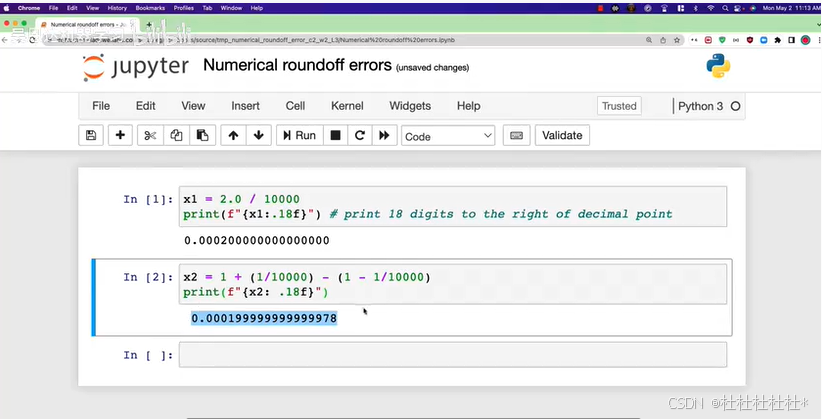
利用TensorFlow的灵活性来减少误差:
直接指定明确的表达式作为损失函数,如下图直接把a换成计算的式子。


输出层用线性激活函数,然后再把它转化为概率:


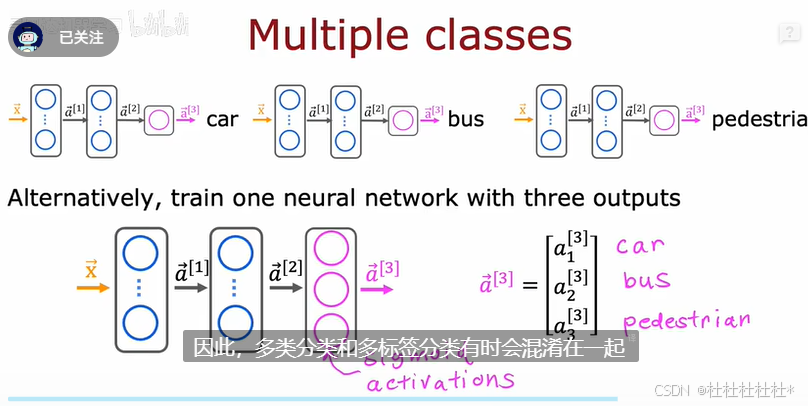
5.多个输出的分类
多标签输出分类和多类分类的区别:
多类分类(Multi-class Classification)
- 定义:多类分类问题是指模型需要从多个类别中选择一个作为预测结果的问题。例如,识别一张图片中的物体是猫、狗还是鸟。
- 输出:对于每个输入样本,模型只能输出一个类别标签。
- 标签关系:不同类别之间是互斥的,即一个样本在给定时间只能属于一个类别。
- 常见应用:手写数字识别、垃圾邮件过滤、疾病诊断等。
多标签分类(Multi-label Classification)
- 定义:多标签分类问题是指模型需要为每个输入样本分配一个或多个标签的问题。例如,一篇文章可能同时属于“科技”、“教育”和“新闻”等多个类别。
- 输出:对于每个输入样本,模型可以输出多个类别标签。
- 标签关系:不同类别之间不是互斥的,即一个样本可以同时属于多个类别。
- 常见应用:文本分类(一篇文章可以属于多个主题)、图像标注(一张图片可以包含多种物体)、音乐分类(一首歌曲可以同时属于“摇滚”和“流行”)等。
区别总结
- 标签数量:多类分类每个样本只能有一个标签,而多标签分类每个样本可以有多个标签。
- 标签互斥性:多类分类的标签是互斥的,多标签分类的标签不是互斥的。
- 模型复杂度:多标签分类通常比多类分类更复杂,因为它需要考虑标签之间的相关性和依赖性。
- 损失函数:多类分类常用的损失函数是交叉熵损失,而多标签分类可能使用二元交叉熵损失或者汉明损失等。
4.
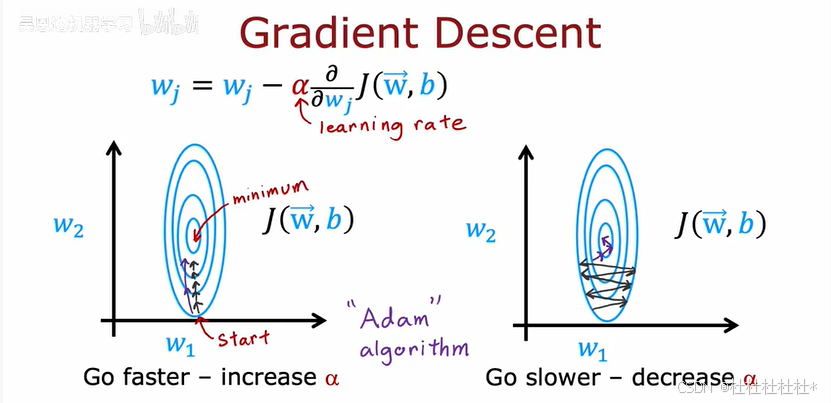
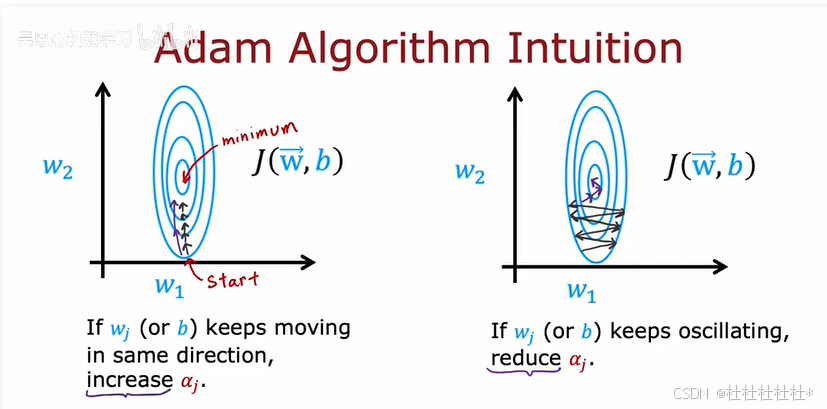
1.高级优化算法
Adam算法:自动调整学习率

2.Additional Layer Types
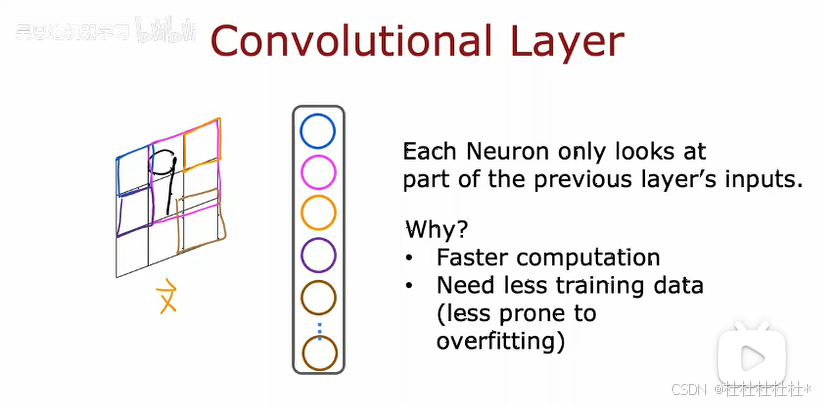
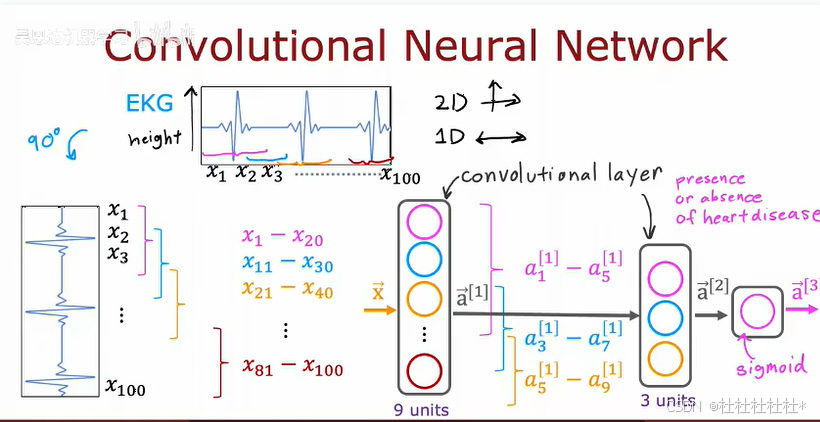
卷积层
卷积层可以加快计算速度,减少训练数据的需求,并降低过度拟合的风险。(每个神经元对应n个输入特征或者激活值,这些值可以相互交叉重叠)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









