







tanh激活函数的作用:
tanh(双曲正切)激活函数是一种在神经网络中常用的非线性激活函数。它的主要作用是引入非线性因素,使得神经网络可以学习和模拟更复杂的函数关系。同时,tanh函数的输出范围在(-1, 1)之间,具有零均值特性,有助于模型的收敛。
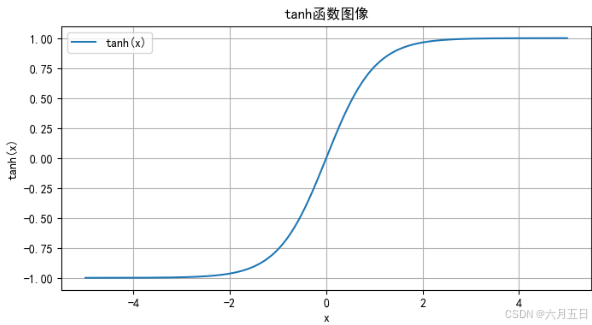
输出范围:(-1, 1)
对称性:关于原点对称的S型曲线
公式:
双曲正切函数(Tanh) 定义为:
tanh
(
x
)
=
e
x
−
e
−
x
e
x
+
e
−
x
\text{tanh}(x) = \frac{e^x - e^{-x}}{e^x + e^{-x}}
tanh(x)=ex+e−xex−e−x
优点:
- 零均值输出:tanh函数的输出范围在(-1, 1)之间,且关于原点对称,这意味着其输出具有零均值特性,有助于模型的收敛。
- 非线性:tanh函数是一种非线性函数,可以引入非线性因素,增强神经网络的表达能力。
- 平滑可导:tanh函数在整个定义域内都是平滑且可导的,便于使用梯度下降等优化算法进行训练。
缺点: - 梯度消失:当输入值的绝对值较大时,tanh函数的梯度会变得非常小,导致梯度消失问题,影响模型的训练效果。
- 计算复杂度较高:相比某些其他激活函数(如ReLU),tanh函数的计算复杂度较高,可能会增加模型的计算负担。
导数计算
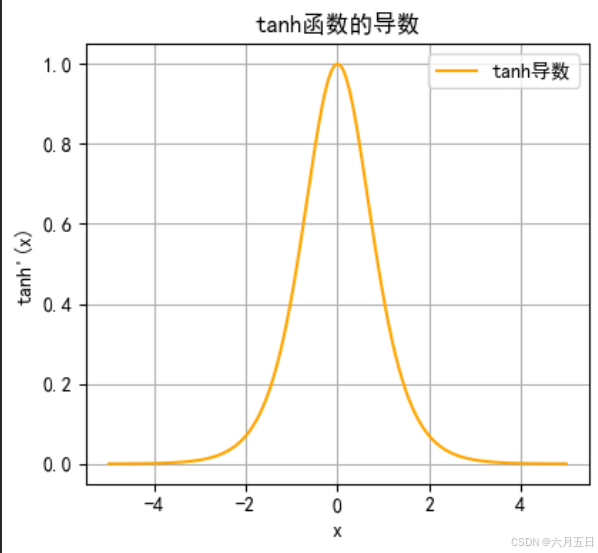
导数公式
d d x tanh ( x ) = 1 − tanh 2 ( x ) \frac{d}{dx}\text{tanh}(x) = 1 - \text{tanh}^2(x) dxdtanh(x)=1−tanh2(x)
导数特性
| 输入区间 | 导数值范围 | 梯度特性 |
|---|---|---|
| x ≈ 0 | ≈1.0 | 最大梯度,有利于学习 |
| |x| > 2 | <0.07 | 梯度消失区域 |
| -2 < x < 2 | 0.07~1.0 | 有效梯度更新区间 |
三、核心优点
-
零中心化输出
输出均值为0,比Sigmoid更有利于:- 加速模型收敛
- 缓解梯度更新震荡
-
梯度放大效应
在输入接近0时梯度最大(≈1),比Sigmoid(最大梯度0.25)的梯度信号更强 -
理论兼容性
与Xavier初始化方法配合良好,可保持各层激活值的方差稳定
四、主要缺点
-
梯度消失问题
当|x| > 2时,梯度迅速衰减至接近0,导致:- 深层网络参数更新困难
- 需要精细的权重初始化
-
计算成本较高
涉及指数运算,比ReLU系列激活函数慢约15%(实测数据) -
非稀疏激活
所有神经元都会被激活,可能降低特征表示的稀疏性
五、与常见激活函数对比
| 特性 | Tanh | Sigmoid | ReLU |
|---|---|---|---|
| 输出范围 | (-1, 1) | (0, 1) | [0, ∞) |
| 零中心化 | ✔️ | ❌ | ❌ |
| 梯度消失风险 | 高 | 极高 | 低(正区间) |
| 计算效率 | 中 | 中 | 高 |
| 主要应用场景 | RNN/LSTM | 二分类输出 | 隐藏层默认 |
实践建议
-
适用场景
- 需要对称输出的循环神经网络
- 与Xavier初始化配合的浅层网络
- 生成对抗网络(GAN)的生成器输出
-
替代方案
- 深层网络优先选用LeakyReLU/Swish
- 需要零中心化时使用SELU
与其他激活函数的对比:
与sigmoid函数对比:
- 相似之处:两者都是非线性激活函数,且都具有平滑可导的特性。
- 不同之处:sigmoid函数的输出范围在(0, 1)之间,而tanh函数的输出范围在(-1, 1)之间,具有零均值特性;此外,tanh函数在解决梯度消失问题上相对优于sigmoid函数。
与ReLU函数对比: - 相似之处:两者都可以引入非线性因素,增强神经网络的表达能力。
- 不同之处:ReLU函数的输出范围在[0, +∞)之间,不存在梯度消失问题,计算复杂度较低,但在负输入区域存在死亡ReLU问题;而tanh函数具有零均值输出特性,但在大输入值时可能出现梯度消失问题。
与Leaky ReLU函数对比: - 相似之处:两者都可以解决ReLU函数的死亡ReLU问题。
- 不同之处:Leaky ReLU函数在负输入区域引入了一个小的正斜率,而tanh函数在负输入区域的斜率逐渐减小;Leaky ReLU函数通常更容易训练,而tanh函数在特定情况下可能表现更好。
总之,tanh激活函数具有零均值输出和非线性特性等优点,但也存在梯度消失和计算复杂度较高等缺点。在选择激活函数时,需要根据具体问题和模型需求进行权衡。

















 2000
2000

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









