









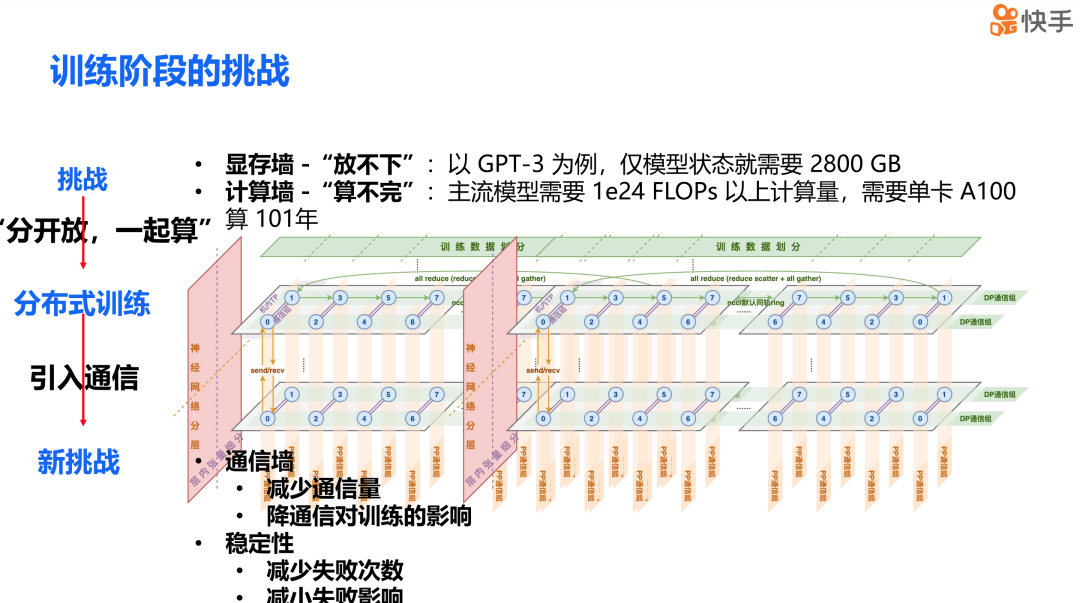
分布式训练的主要难点

简单介绍一下混合并行中经典的三种并行方案。首先是数据并行,简称 DP。正如其名,数据并行是将数据分割到不同的计算设备上,然后由这些设备完成各自的计算任务。第二种是张量并行,简称 TP。张量并行是将模型中某些层的参数分散到不同的设备上,每个设备负责完成部分的计算工作。第三种是流水并行,简称 PP。流水并行是将模型的不同层切分到不同的计算设备上,类似于流水线的工作方式,各个设备协同完成整个模型的计算过程。


大模型训练在超大规模集群下
的挑战与解决方案
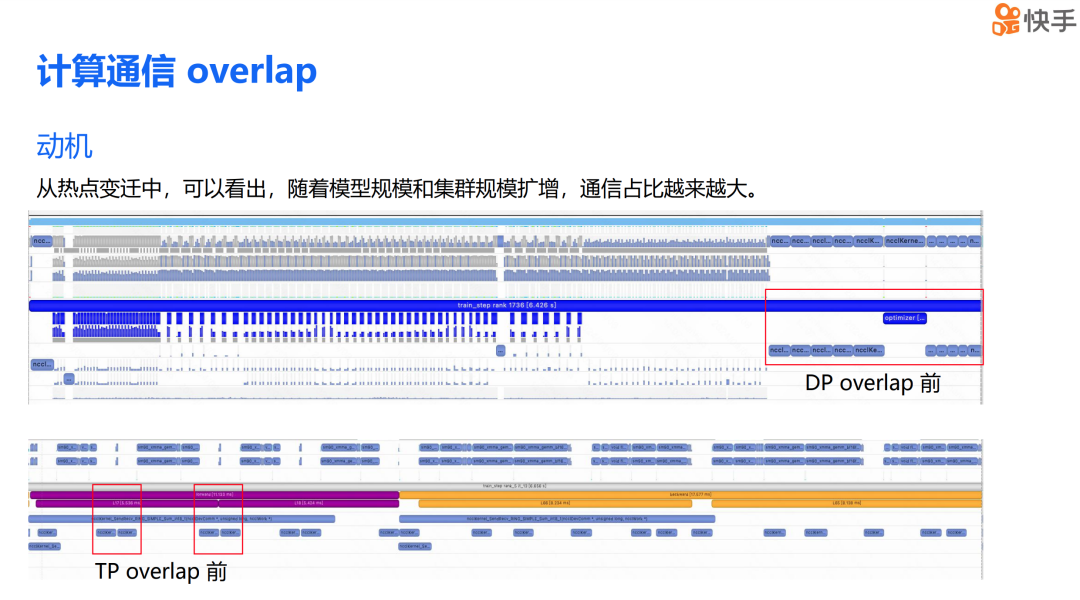
随着模型规模和集群规模的扩大,通信在训练过程中的占比越来越大。为了更直观地展示这一现象,我提供了两张时间线图,它们没有应用计算通信重叠技术。第一张图突出显示了在实现 DP 重叠前的数据并行通信状态,第二张图则突出显示了在实现 TP 重叠前的张量并行通信情况。
从图中我们可以看到,在端到端的训练过程中,DP 的通信占比实际上超过了 15%,而 TP 的通信时间占比也超过了 30%。因此,减少通信对训练的影响,对提升训练效率至关重要。
DP Overlap

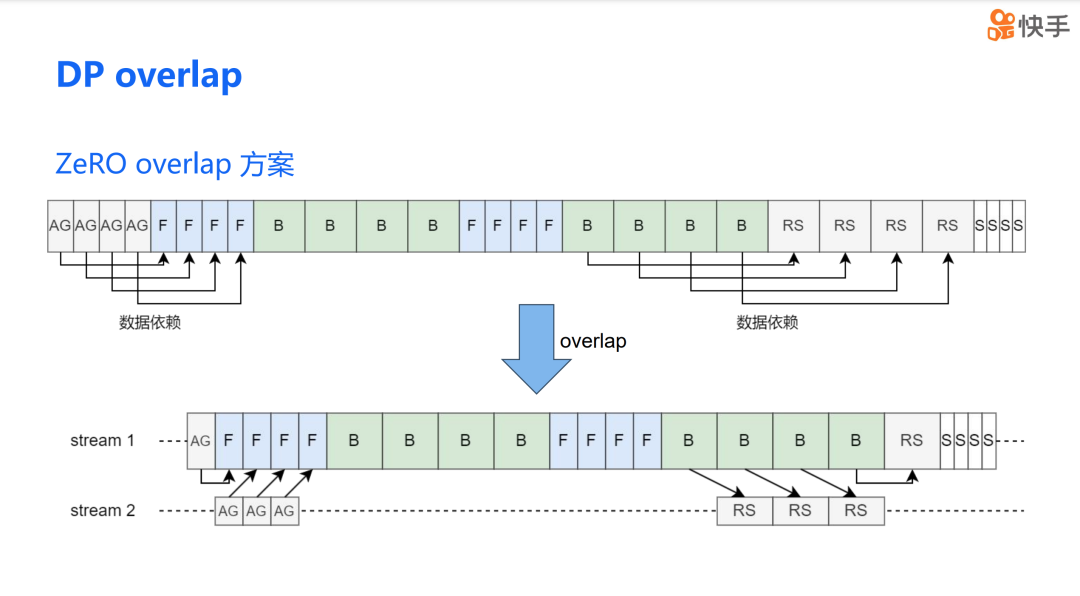
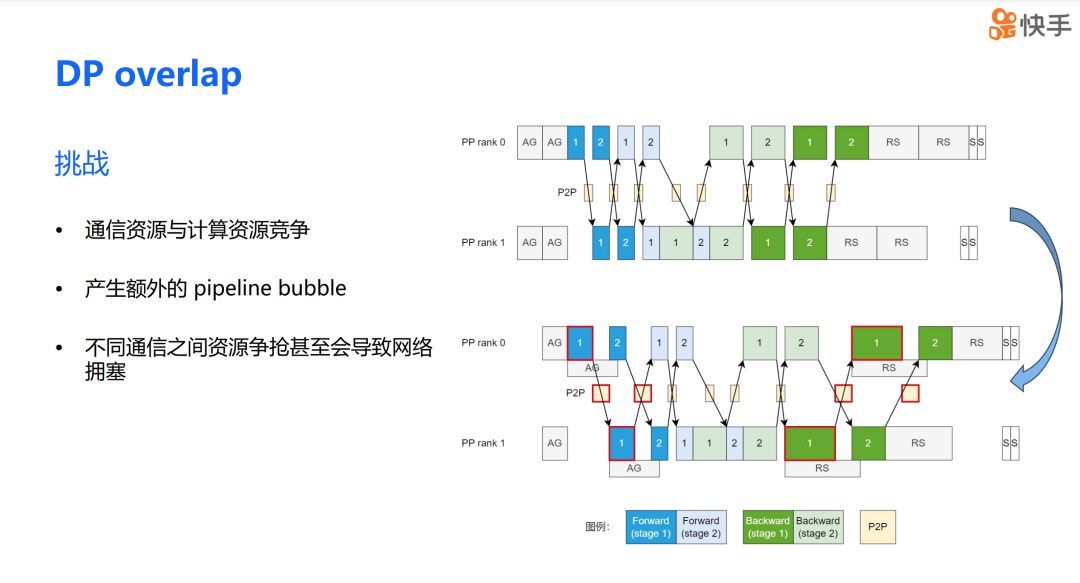
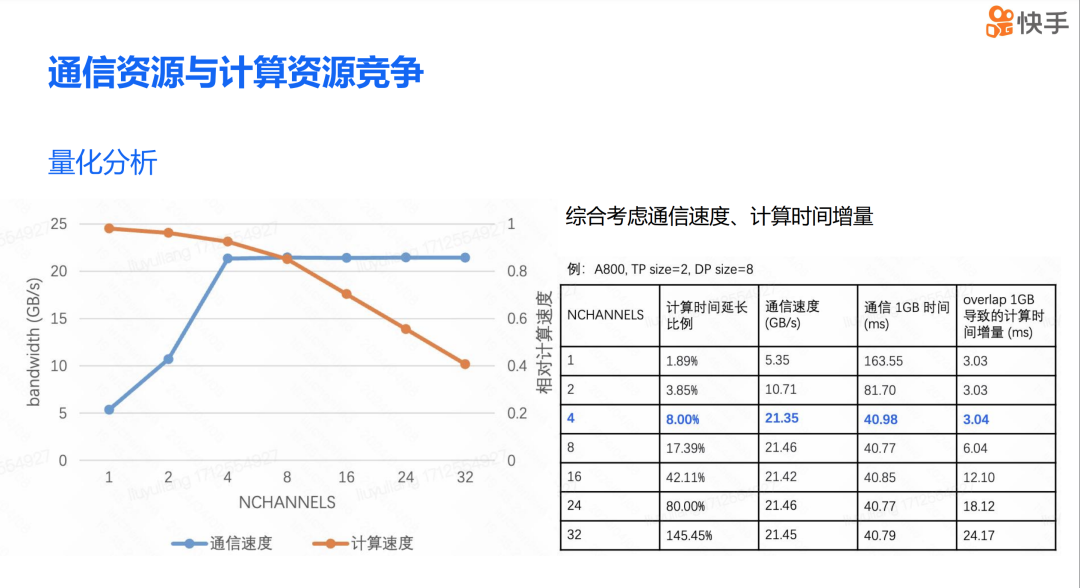
DP overlap 的方案在理论上看起来非常吸引人,但实际应用中,我们真的能显著提升训练效率吗?在进行 DP overlap 优化时,我们遇到了三个主要问题。首先,是通信和计算资源之间的竞争问题。当通信和计算操作同时进行时,它们会争夺有限的硬件资源,这可能会影响整体的系统性能。其次,在混合并行场景下,DP overlap 还可能带来 PP bubble 的问题。第三,不同通信资源的争抢还可能导致网络拥塞。

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









