






比如进程正在执行一个重要的
IO,突然一个终止信号发出,IO立即终止,对进程、磁盘都不好
因此信号在 产生 后,需要等进程将 更重要 的事忙完后(合适的时机),才进行 处理
合适的时机:进程从 内核态 返回 用户态 时,会在操作系统的指导下,对信号进行检测及处理
至于处理动作,分为:默认动作、忽略、用户自定义
搞清楚 “合适” 的时机 后,接下来需要学习 用户态 和 内核态 相关知识
2、用户态与内核态
对于 用户态、内核态 的理解及引出的 进程地址空间 和 信号处理过程 相关知识是本文的重难点
2.1、概念
先来看看什么是 用户态和内核态
**用户态**:执行用户所写的代码时,就属于 用户态
**内核态**:执行操作系统的代码时,就属于 内核态
自己写的代码被执行很好理解,操作系统的代码是什么?
- 操作系统也是由大量代码构成的
- 在对进程进行调度、执行系统调用、异常、中断、陷阱等,都需要借助操作系统之手
- 此时执行的就是操作系统的代码
也就是说,**用户态** 与 **内核态** 是两种不同的状态,必然存在相互转换的情况
**用户态** 切换为 **内核态**:
- 当进程时间片到了之后,进行进程切换动作
- 调用系统调用接口,比如
open、close、read、write等 - 产生异常、中断、陷阱等
**内核态** 切换为 **用户态**:
- 进程切换完毕后,运行相应的进程
- 系统调用结束后
- 异常、中断、陷阱等处理完毕
信号的处理时机就是 **内核态** 切换为 **用户态**,也就是 当把更重要的事做完后,进程才会在操作系统的指导下,对信号进行检测、处理
下面来结合 进程地址空间 深入理解 操作系统的代码 及 状态切换 的相关内容(拓展知识)
2.2、重谈进程地址空间
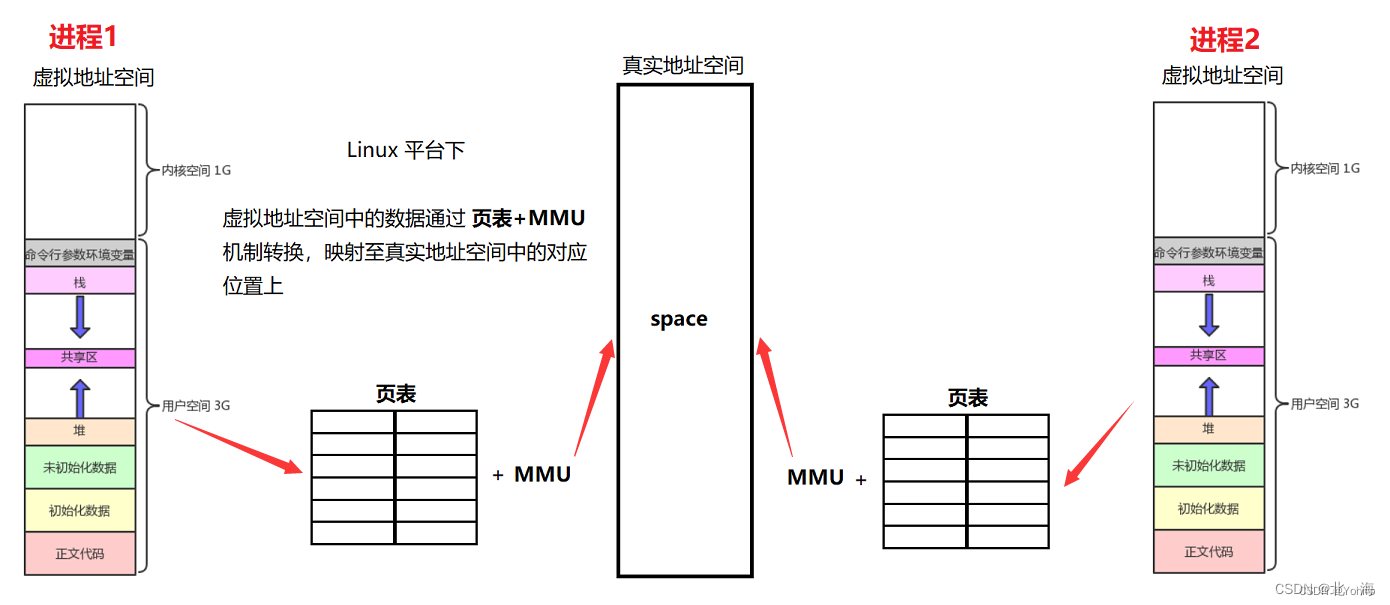
首先简单回顾下 进程地址空间 的相关知识:
- 进程地址空间 是虚拟的,依靠 页表+
MMU机制 与真实的地址空间建立映射关系 - 每个进程都有自己的 进程地址空间,不同 进程地址空间 中地址可能冲突,但实际上地址是独立的
- 进程地址空间 可以让进程以统一的视角看待自己的代码和数据
关于 进程地址空间 的相关知识详见 《Linux进程学习【进程地址】》
不难发现,在 进程地址空间 中,存在 1 GB 的 内核空间,每个进程都有,而这 1 GB 的空间中存储的就是 操作系统 相关 代码 和 数据,并且这块区域采用 内核级页表 与 真实地址空间 进行映射
为什么要区分
**用户态**与**内核态**?
- 内核空间中存储的可是操作系统的代码和数据,权限非常高,绝不允许随便一个进程对其造成影响
- 区域的合理划分也是为了更好的进行管理

所谓的 执行操作系统的代码及系统调用,就是在使用这 1 GB 的内核空间
进程间具有独立性,比如存在用户空间中的代码和数据是不同的,难道多个进程需要存储多份 操作系统的代码和数据 吗?
- 当然不用,内核空间比较特殊,所有进程最终映射的都是同一块区域,也就是说,进程只是将 操作系统代码和数据 映射入自己的 进程地址空间 而已
- 而 内核级页表 不同于 用户级页表,专注于对 操作系统代码和数据 进行映射,是很特殊的
当我们执行诸如 open 这类的 系统调用 时,会跑到 内核空间 中调用对应的函数
而 跑到内核空间 就是 **用户态** 切换为 **内核态** 了(用户空间切换至内核空间)
这个 跑到 是如何实现的呢?
在 CPU 中,存在一个 CR3 寄存器,这个 寄存器 的作用就是用来表征当前处于 **用户态** 还是 **内核态**
- 当寄存器中的值为
3时:表示正在执行用户的代码,也就是处于**用户态** - 当寄存器中的值为
0时:表示正在执行操作系统的代码,也就是处于**内核态**
通过一个 寄存器,表征当前所处的 状态,修改其中的 值,就可以表示不同的 状态,这是很聪明的做法

重谈 进程地址空间 后,得到以下结论
- 所有进程的用户空间
[0, 3] GB是不一样的,并且每个进程都要有自己的 用户级页表 进行不同的映射 - 所有进程的内核空间
[3, 4] GB是一样的,每个进程都可以看到同一张内核级页表,从而进行统一的映射,看到同一个 操作系统 - 操作系统运行 的本质其实就是在该进程的 内核空间内运行的(最终映射的都是同一块区域)
- 系统调用 的本质其实就是在调用库中对应的方法后,通过内核空间中的地址进行跳转调用
那么进程又是如何被调度的呢?
- 操作系统的本质
- 操作系统也是软件啊,并且是一个死循环式等待指令的软件
- 存在一个硬件:操作系统时钟硬件,每隔一段时间向操作系统发送时钟中断
- 进程被调度,就意味着它的时间片到了,操作系统会通过时钟中断,检测到是哪一个进程的时间片到了,然后通过系统调用函数
schedule()保存进程的上下文数据,然后选择合适的进程去运行
2.3、信号的处理过程
当在 **内核态** 完成某种任务后,需要切回 **用户态**,此时就可以对信号进行 检测 并 处理 了
情况1:信号被阻塞,信号产生/未产生
信号都被阻塞了,也就不需要处理信号,此时不用管,直接切回 **用户态** 就行了
下面的情况都是基于 信号未被阻塞 且 信号已产生 的前提
情况2:当前信号的执行动作为 默认
大多数信号的默认执行动作都是 终止 进程,此时只需要把对应的进程干掉,然后切回 **用户态** 就行了

情况3:当前信号的执行动作为 忽略
当信号执行动作为 忽略 时,不做出任何动作,直接返回 用户态

情况4:当前信号的执行动作为 用户自定义
这种情况就比较麻烦了,用户自定义的动作位于 **用户态** 中,也就是说,需要先切回 **用户态**,把动作完成了,重新坠入 **内核态**,最后才能带着进程的上下文相关数据,返回 **用户态**
在
**内核态**中,也可以直接执行 自定义动作,为什么还要切回**用户态**执行自定义动作?
- 因为在
**内核态**可以访问操作系统的代码和数据,自定义动作 可能干出危害操作系统的事- 在
**用户态**中可以减少影响,并且可以做到溯源为什么不在执行完 自定义动作 直接后返回进程?
- 因为 自定义动作 和 待返回的进程 属于不同的堆栈,是无法返回的
- 并且进程的上下文数据还在内核态中,所以需要先坠入内核态,才能正确返回用户态

注意: 用户自定义的动作,需要先切换至 **用户态** 中执行,执行结束后,还需要坠入 **内核态**
通过一张图快速记录信号的 处理 过程

图片来源:Linux进程信号
3、信号的捕捉
接下来谈谈 信号 是如何被 捕捉 的
3.1、内核如何实现信号的捕捉?
如果信号的执行动作为 用户自定义动作,当信号 递达 时调用 用户自定义动作,这一动作称为 信号捕捉
用户自定义动作 是位于 用户空间 中的
当 **内核态** 中任务完成,准备返回 **用户态** 时,检测到信号 递达,并且此时为 用户自定义动作,需要先切入 **用户态** ,完成 用户自定义动作 的执行;因为 用户自定义动作 和 待返回的函数 属于不同的 堆栈 空间,它们之间也不存在 调用与被调用 的关系,是两个 独立的执行流,需要先坠入 **内核态** (通过 sigreturn() 坠入),再返回 **用户态** (通过 sys_sigreturn() 返回)
上述过程可以总结为下图:

3.2、sigaction
sigaction 也可以 用户自定义动作,比 signal 功能更丰富

#include <signal.h>
int sigaction(int signum, const struct sigaction \*act,
struct sigaction \*oldact);
struct sigaction
{
void (\*sa_handler)(int); //自定义动作
void (\*sa_sigaction)(int, siginfo_t \*, void \*); //实时信号相关,不用管
sigset_t sa_mask; //待屏蔽的信号集
int sa_flags; //一些选项,一般设为 0
void (\*sa_restorer)(void); //实时信号相关,不用管
};
返回值:成功返回 0,失败返回 -1 并将错误码设置
参数1:待操作的信号
参数2:sigaction 结构体,具体成员如上所示
参数3:保存修改前进程的 sigaction 结构体信息
这个函数的主要看点是 sigaction 结构体
struct sigaction
{
void (\*sa_handler)(int); //自定义动作
void (\*sa_sigaction)(int, siginfo_t \*, void \*); //实时信号相关,不用管
sigset_t sa_mask; //待屏蔽的信号集
int sa_flags; //一些选项,一般设为 0
void (\*sa_restorer)(void); //实时信号相关,不用管
};
其中部分字段不需要管,因为那些是与 实时信号 相关的,我们这里不讨论
重点可以看看 sa_mask 字段
sa_mask:当信号在执行 用户自定义动作 时,可以将部分信号进行屏蔽,直到 用户自定义动作 执行完成
也就是说,我们可以提前设置一批 待阻塞 的 屏蔽信号集,当执行 signum 中的 用户自定义动作 时,这些 屏蔽信号集 中的 信号 将会被 屏蔽(避免干扰 用户自定义动作 的执行),直到 用户自定义动作 执行完成
可以简单用一下 sigaction 函数
#include <iostream>
#include <cassert>
#include <cstring>
#include <signal.h>
#include <unistd.h>
using namespace std;
static void DisplayPending(const sigset_t pending)
{
// 打印 pending 表
cout << "当前进程的 pending 表为: ";
int i = 1;
while (i < 32)
{
if (sigismember(&pending, i))
cout << "1";
else
cout << "0";
i++;
}
cout << endl;
}
static void handler(int signo)
{
cout << signo << " 号信号确实递达了" << endl;
// 最终不退出进程
int n = 10;
while (n--)
{
// 获取进程的 未决信号集
sigset_t pending;
sigemptyset(&pending);
int ret = sigpending(&pending);
assert(ret == 0);
(void)ret; // 欺骗编译器,避免 release 模式中出错
DisplayPending(pending);
sleep(1);
}
}
int main()
{
cout << "当前进程: " << getpid() << endl;
//使用 sigaction 函数
struct sigaction act, oldact;
//初始化结构体
memset(&act, 0, sizeof(act));
memset(&oldact, 0, sizeof(oldact));
//初始化 自定义动作
act.sa_handler = handler;
//初始化 屏蔽信号集
sigaddset(&act.sa_mask, 3);
sigaddset(&act.sa_mask, 4);
sigaddset(&act.sa_mask, 5);
//给 2号 信号注册自定义动作
sigaction(2, &act, &oldact);
// 死循环
while (true);
return 0;
}

当 2 号信号的循环结束(10 秒),3、4、5 信号的 阻塞 状态解除,立即被 递达,进程就被干掉了
注意: 屏蔽信号集 sa_mask 中已屏蔽的信号,在 用户自定义动作 执行完成后,会自动解除 阻塞 状态
4、信号部分小结
截至目前,信号 处理的所有过程已经全部学习完毕了
信号产生阶段:有四种产生方式,包括 键盘键入、系统调用、软件条件、硬件异常
信号保存阶段:内核中存在三张表,blcok 表、pending 表以及 handler 表,信号在产生之后,存储在 pending 表中
信号处理阶段:信号在 **内核态** 切换回 **用户态** 时,才会被处理

===== 补充 =====
下面是一些补充知识
5、可重入函数
可以被重复进入的函数称为 可重入函数
比如单链表头插的场景中,节点 node1 还未完成插入时,node2 也进行了头插,最终导致 节点 node2 丢失,造成 内存泄漏

导致 内存泄漏 的罪魁祸首:对于 node1 和 node2 来说,操作的 单链表 是同一个,同时进行并发访问(重入)会出现问题的,因为此时的 单链表 是临界资源
我们学过的函数中,90% 都是 不可重入的
函数是否可重入是一个特性,而非缺点,需要正确看待
不可重入的条件:
- 调用了内存管理相关函数
- 调用了标准
I/O库函数,因为其中很多实现都以不可重入的方式使用数据结构
6、volatile
volatile 关键字可以避免 编译器 的优化,保证内存的 可见性
比如在下面这个例子中
借助全局变量 falg 设计一个死循环的场景,在此之前将 2 号信号进行自定义动作捕捉,具体动作为:将 flag 改为 1,可以终止 main 函数中的循环体
#include <stdio.h>
#include <signal.h>
int flag = 0; // 一开始为假
void handler(int signo)
{
printf("%d号信号已经成功发出了\n", signo);
flag = 1;
}
int main()
{
signal(2, handler);
while(!flag); // 故意不写 while 的代码块 { }
printf("进程已退出\n");
return 0;
}

初步结果符合预期,2 号信号发出后,循环结束,程序正常退出
这段代码能符合我们预期般的正确运行是因为 当前编译器默认的优化级别很低,没有出现意外情况
通过指令查询 gcc 优化级别的相关信息
man gcc
: /O1

其中数字越大,优化级别越高,理论上编译出来的程序性能会更好
事实真的如此吗?
让我们重新编译上面的程序,并指定优化级别为 O1
gcc mySignal mySignal.c -O1
编译成功后,再次运行程序

此时得到了不一样的结果:2 号信号发出后,对于 falg 变量的修改似乎失效了
将优化级别设为更高是一样的结果,如果设为 O0 则会符合预期般的运行,说明我们当前的编译器默认的优化级别是 O0
查看编译器的版本
gcc --version
当前版本为 gcc(GCC) 4.8.5 (不同版本编译器的默认优化级别可能略有不同)

那么我们这段代码哪个地方被优化了呢?
- 答案是
while循环判断
首先要明白:
- 对于程序中的数据,需要先被
load到CPU中的**寄存器**中 - 判断语句所需要的数据(比如
flag),在进行判断时,是从**寄存器**中拿取并判断 - 根据判断的结果,判断代码的下一步该如何执行(通过
PC指针指向具体的代码执行语句)
所以程序在优化级别为 O0 或更低时,是这样执行的:

7、SIGCHLD 信号
在 进程控制 学习时期,我们明白了一个事实:父进程必须等待子进程退出并回收,并为其 “收尸”,避免变成 “僵尸进程” 占用系统资源、造成内存泄漏
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
加入社区》https://bbs.youkuaiyun.com/forums/4304bb5a486d4c3ab8389e65ecb71ac0
中**
2. 判断语句所需要的数据(比如 flag),在进行判断时,是从 **寄存器** 中拿取并判断
3. 根据判断的结果,判断代码的下一步该如何执行(通过 PC 指针指向具体的代码执行语句)
所以程序在优化级别为 O0 或更低时,是这样执行的:
7、SIGCHLD 信号
在 进程控制 学习时期,我们明白了一个事实:父进程必须等待子进程退出并回收,并为其 “收尸”,避免变成 “僵尸进程” 占用系统资源、造成内存泄漏
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
[外链图片转存中…(img-GqA0cJEa-1725717052549)]
[外链图片转存中…(img-rPuPNwhI-1725717052550)]
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
加入社区》https://bbs.youkuaiyun.com/forums/4304bb5a486d4c3ab8389e65ecb71ac0

















 2110
2110

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









