






数据结构
什么是数据结构,数据结构就是数据的储存位置与顺序。
这里有电话薄,我们有两种方式储存信息。
这里有两种顺序,一个是获取顺序,一个是按拼音排列顺序。获取顺序是什么样的呢?就是获得了一个人新的数据,将其添加到在表格的最后一行。每次想要查找某个人的电话时,要从头查找,直到找到那个人的电话。这种方式查找比较麻烦,但添加很方便。
如果用拼音顺序排序,每次按照姓名的拼音首字母,就可以知道大概处在哪个位置。比如说知道姓张的应该排在最后,比较靠后,姓何的可能排在中间。这样查找起来会方便一些
但是如果要添加一个人的名字到表格里,会发现要从中间插入,这样就需要将其他人的都往后移一个,然后插入新的名字和电话。这样查找方便了,但添加变得更麻烦。
那么有没有一种方法能让查找和添加都方便呢?可以创建多个表格,每个表格是同一个拼音的。比如姓贺的和姓黄的,h 开头的都在一个表格里面,然后每一个表格里面都是按获取顺序排序。这样子添加和查找都方便。
链表
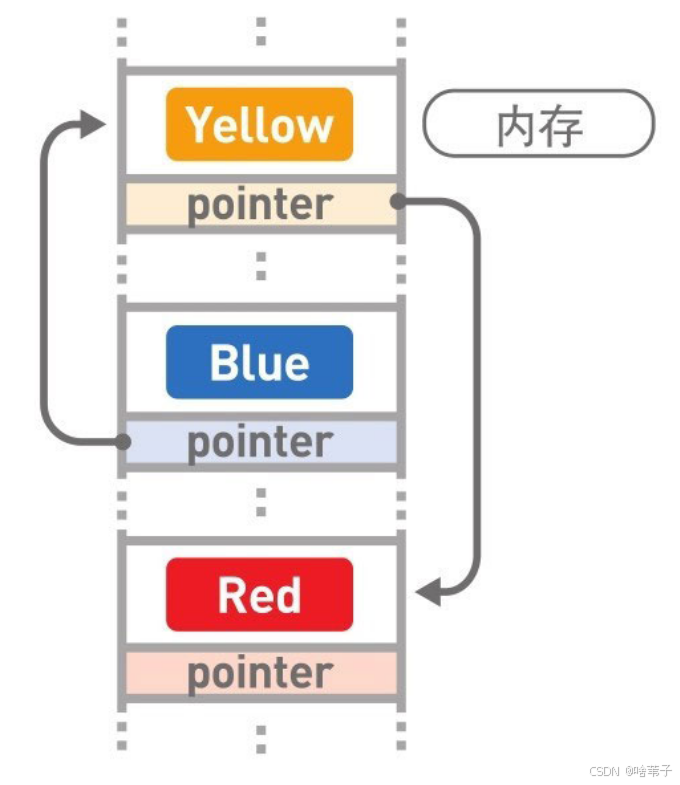
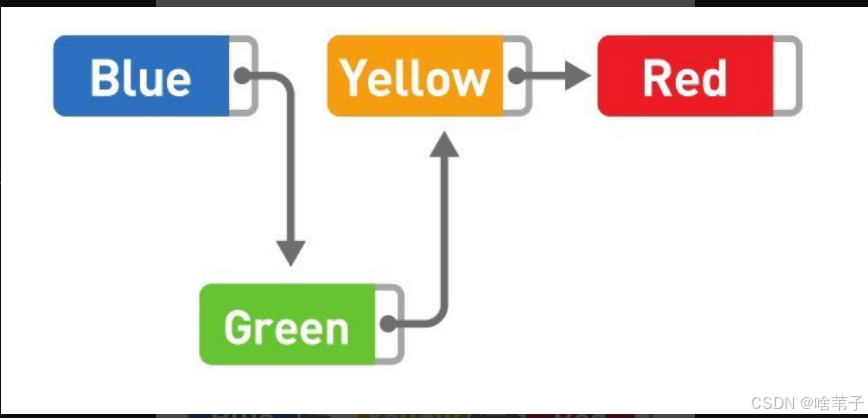
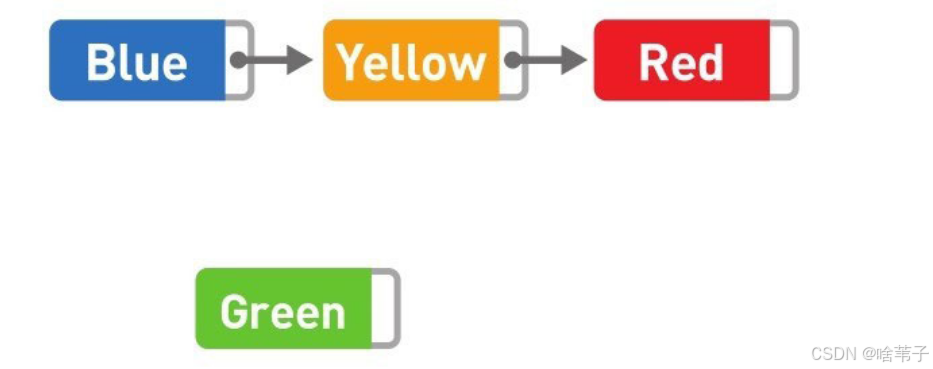
链表是数据储存的一种线性结构。它储存的数据是分散的,而非集中的。它需要有箭头从第一个数据一直指向最后一个数据。但也正因如此,它的添加与删除较为方便,只要改变箭头的顺序就行,无需移动其他数据。只要改变两个箭头,或者说改变一个箭头,就可以添加和删除数据。
数组
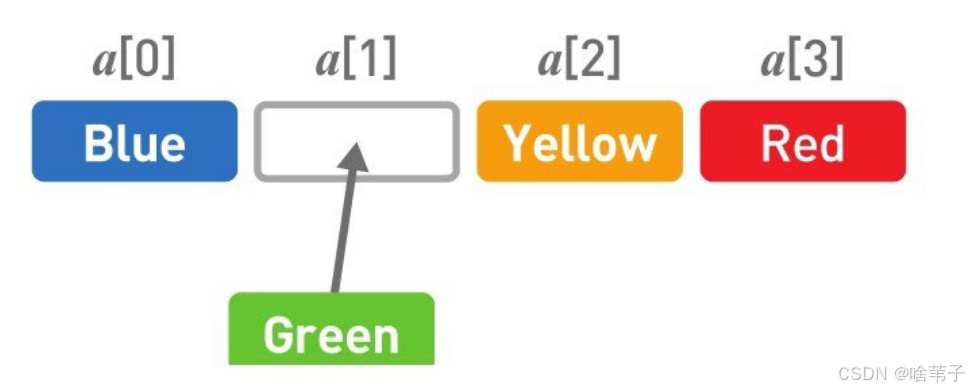
然后我们现在介绍一下数组,数组是储存在一个连续的空间里面的。可以根据数组的标号判断内存的储存位置。所以相当于直接访问,不需要箭头从头到尾查找,直接访问就行。所以它的查找速度非常快,但是添加和删除比较慢。假如在 1号位置添加一个数据,要在最后一个位置多拿出一个内存空间,然后将 1 号及后面的数据都移一个位置,再把新数据添加进去,所以比较麻烦。删除数据也是一样。那么总结一下,链表访问比较久,但添加和删除容易;数组访问容易,但添加和删除难。

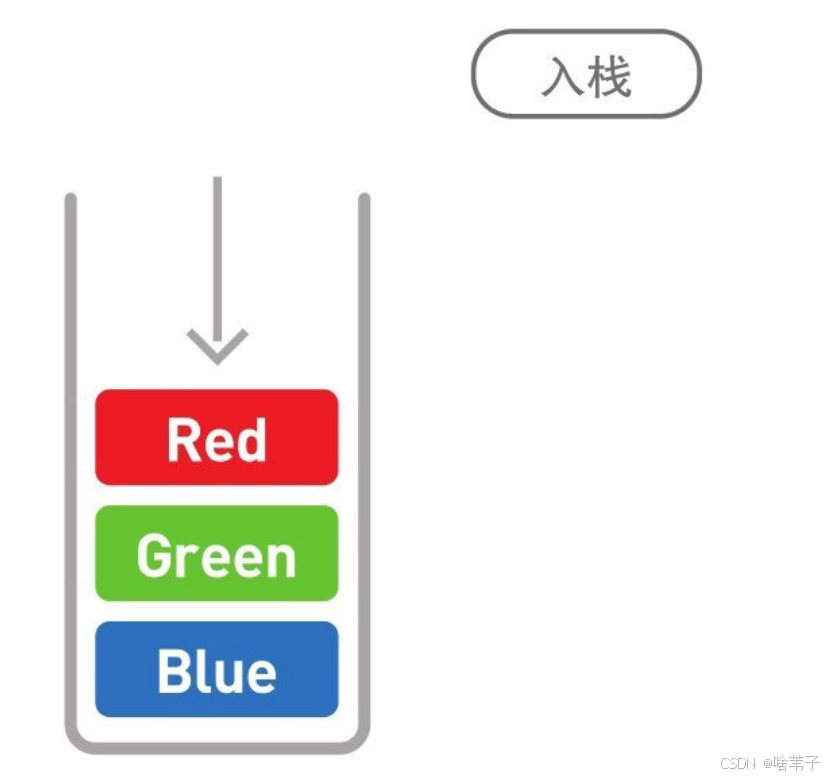
栈
栈也是呈线性排列的数据结构。可以把栈看作一垛书,先放第一本书在栈里,再放第二本、第三本,第一本书肯定在最下面一层。然后从栈里拿数据时,肯定从最上面的数据开始拿,所以这个顺序是先进去的最后才能出来。将往栈里放数据的动作称为入栈,拿数据的动作叫出栈。入栈的英文是 push ,出栈的英文是 pop 。

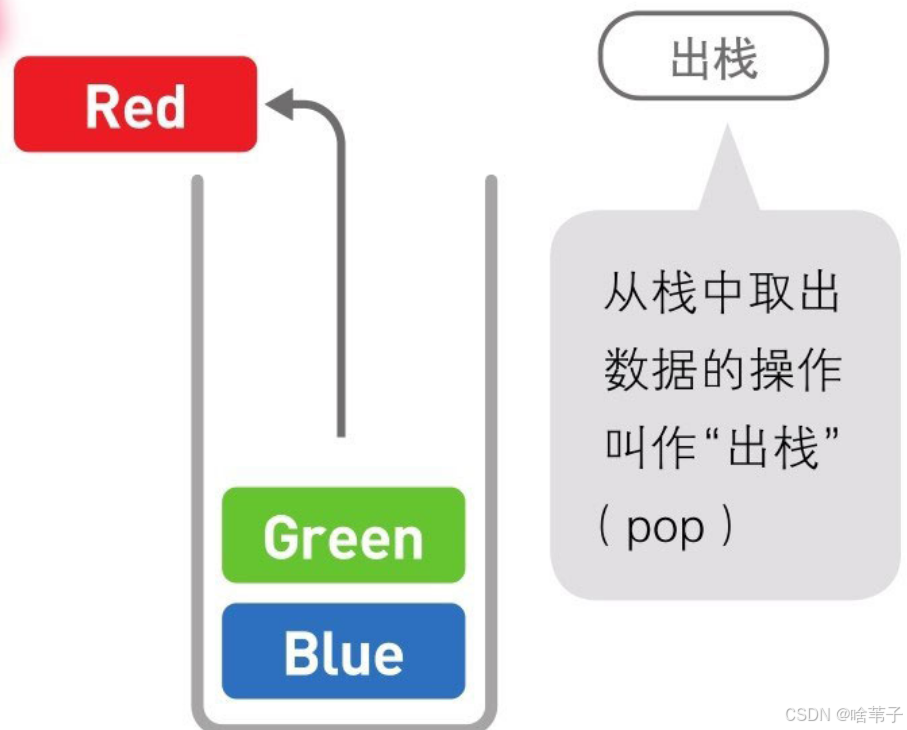
那个先进后出,用英文表示就是 first in last out 。
栈有一个很有用的功能,就是配对括号。比如说有很多括号,括号里还套着小括号,再套着括号。反括号和它最近出来的正括号是配对在一起的。因为它遵循着先进后出的原则,最后出去的一个括号和第一个进来的左括号配对。比如,规定(AB(C(DE)F)(G((H)I J)K))这一串字符中括号的处理方式如下:首先从左边开始读取字符,读到左括号就将其入栈,读到右括号就将栈顶的左括号出栈。
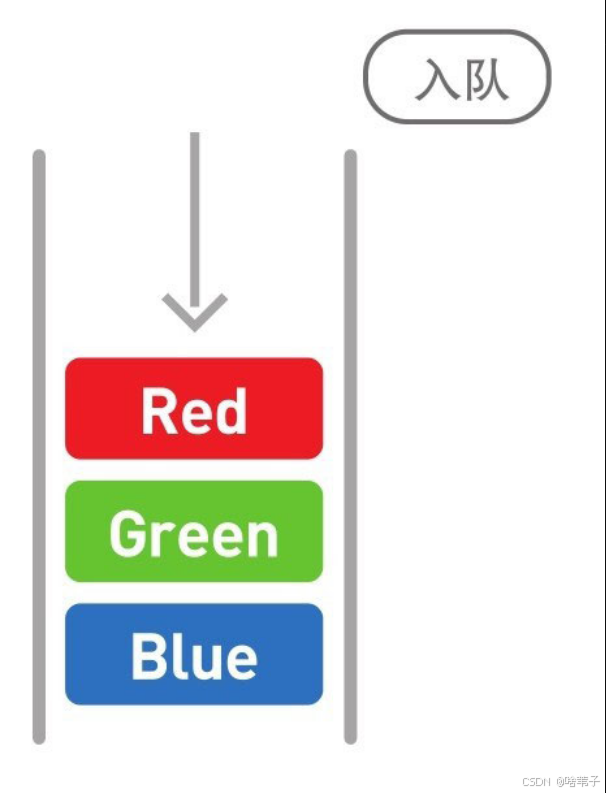
列队
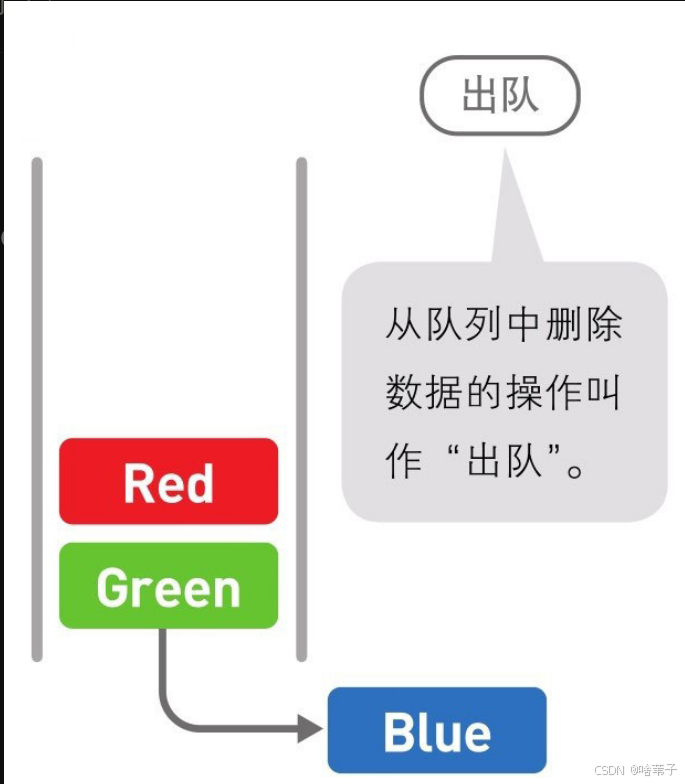
然后队列也是线性的数据结构,但是它遵循先进先出的原则。添加数据叫入队,删除数据叫出队。第一个进去的数据肯定是第一个删除的。
堆
然后讲一下堆。堆是一种图形,它是一个每次取出最小值的队列。它比较复杂,规则是父节点必须小于子节点。
每次添加数据是添加到最下面一层的最左边,如果没有位置就往右移动,反正就是从下层开始从左到右添加。然后调整堆的结构,满足父节点小于子节点的规则。
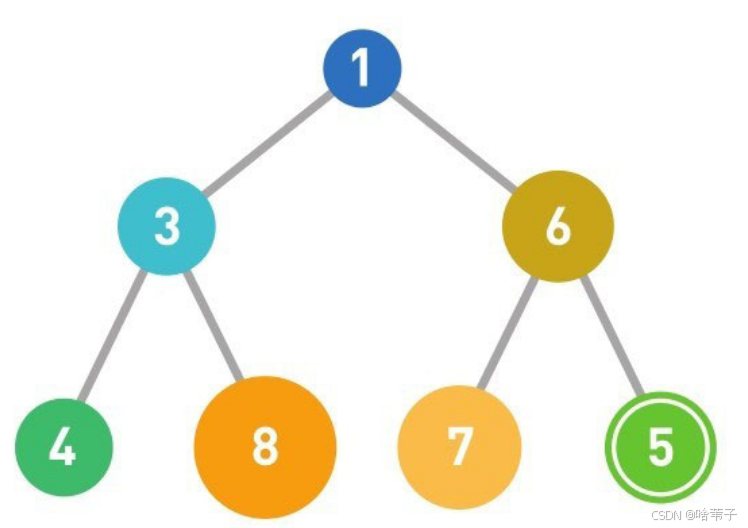
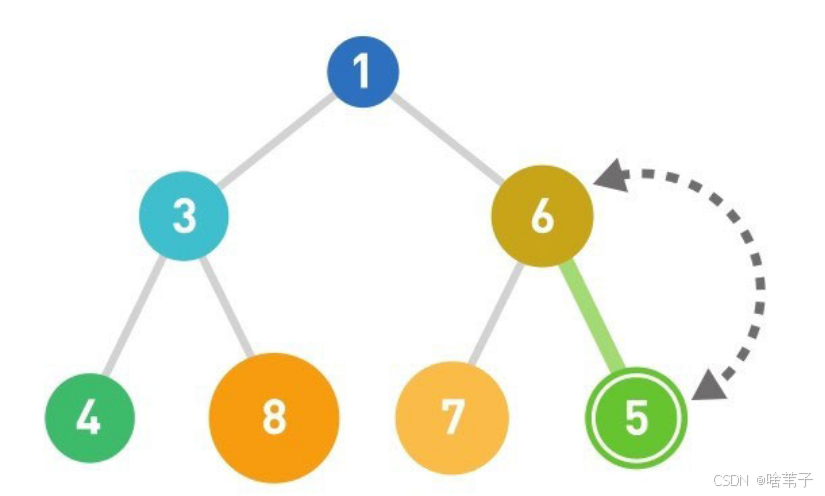
删除数据是从最上面开始,如果删除了第一个数据,就要把最上面那个位置补上。从最下面一层的最右边那个数补到删除数据的位置,也就是顶点的位置,因为删除数据是删除顶点位置。然后调整堆的结构。
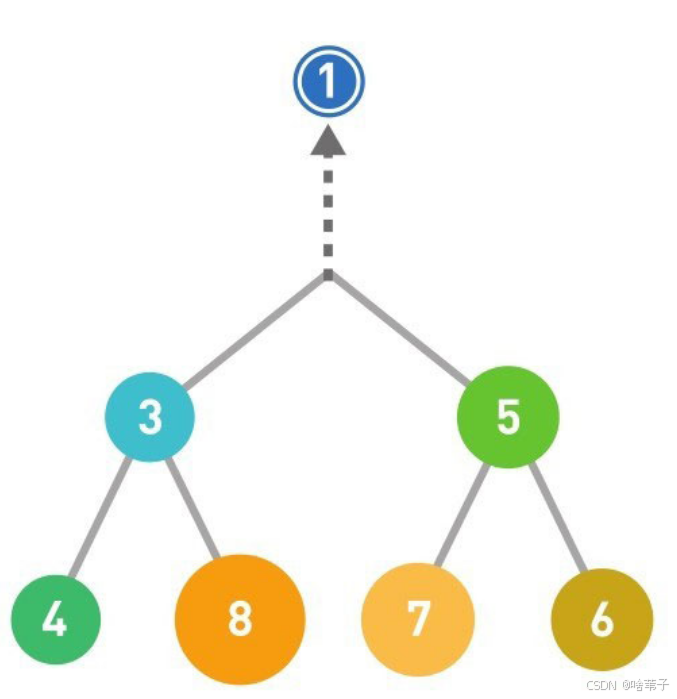
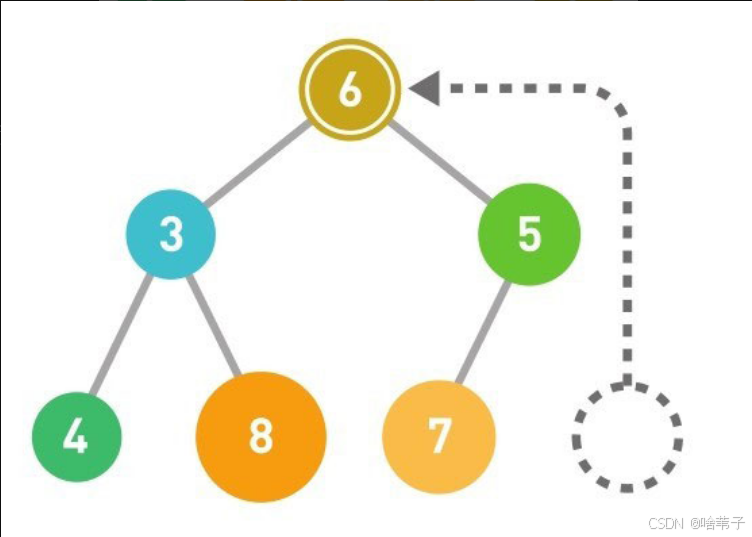
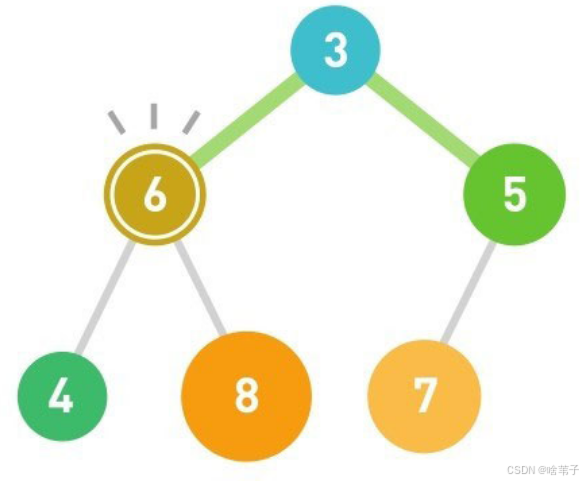
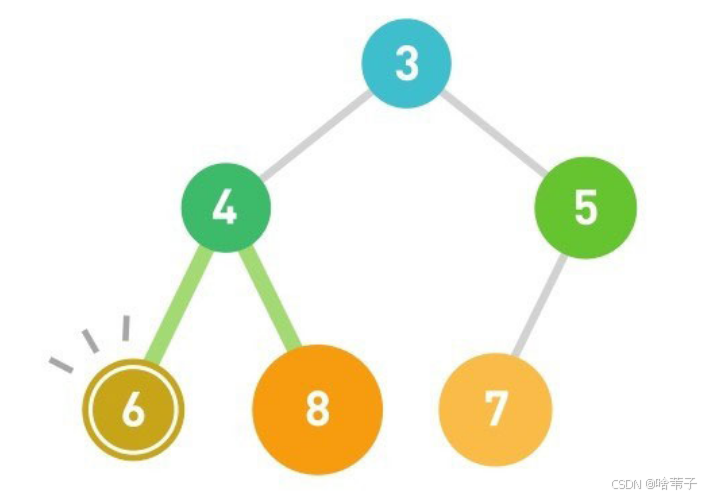
不论添加数据还是删除数据,都再重新调整堆的结构。调整堆的结构的时间复杂度是 LOG2 的 n 。这是因为每次调整都是一层一层移动,只需要计算包含 n 个数据的堆有多少层。利用等比数列求和公式,我们知道x层会有2的x次方-1个数据。忽略-1,反推如果有 n 个数据,层数就是 log 2的 n 。
二叉树
等一下,我先讲一下二叉树。什么是二叉树呢?二叉树也是一种树形结构。它有个规则,子节点必须有两个,而且一个节点必须大于它左子树上的所有节点,必须小于它右子树的所有节点。这意思是越往左越往下数越小,越往右越往下数越大。我们可以想象一下,把这个树横向压扁,不是竖着压扁。把它压成一条横着的直线,就会发现是从小到大排列的。
那我们怎么对这个树进行添加数据和删除数据呢?
比如要添加一个数字 1 ,就从树顶开始比较,一直到最后一个子节点。
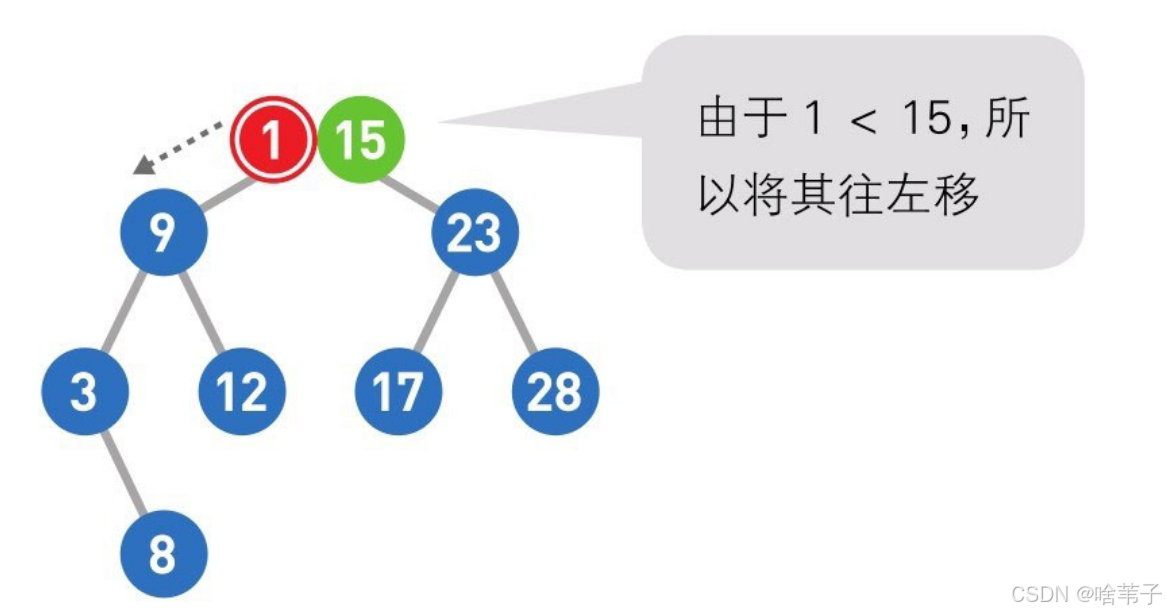
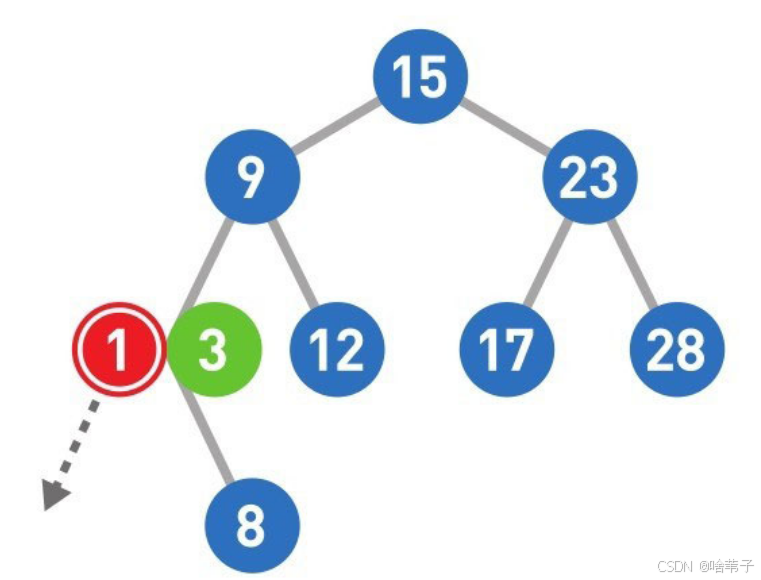
然后我们删除数据,如果它是最下面的子节点,且没有自己的子节点,就直接删除。如果它本身有一个子节点,就把它删除,用它的子节点代替。如果它有很多孩子,就用它左子树的最大数或右子树的最小数来顶替,这样就满足二叉树的规则。二叉树的规则是这个节点的位置要大于它左边所有的数,小于它右子树上的所有的数。把这个节点的数字删掉后,在左边子树上找到一个最大的数字,一定会大于左边所有的子节点,且这个最大的数字肯定小于刚刚删除的数字,小于刚刚删除数字右边节点的数字。
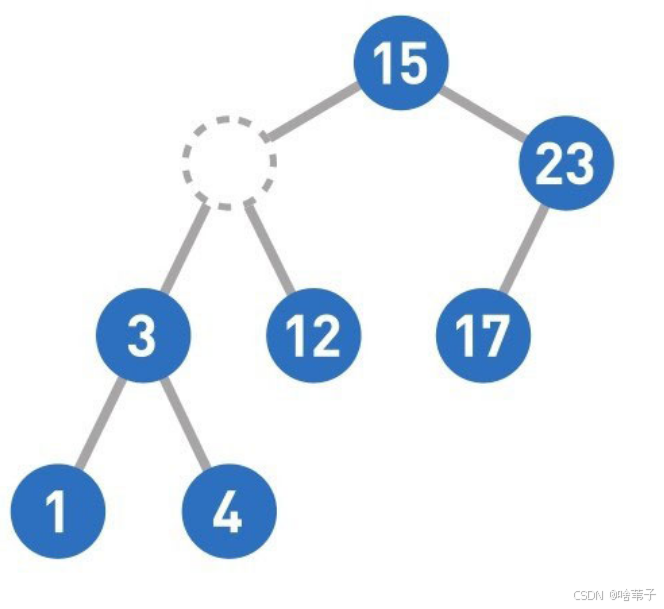
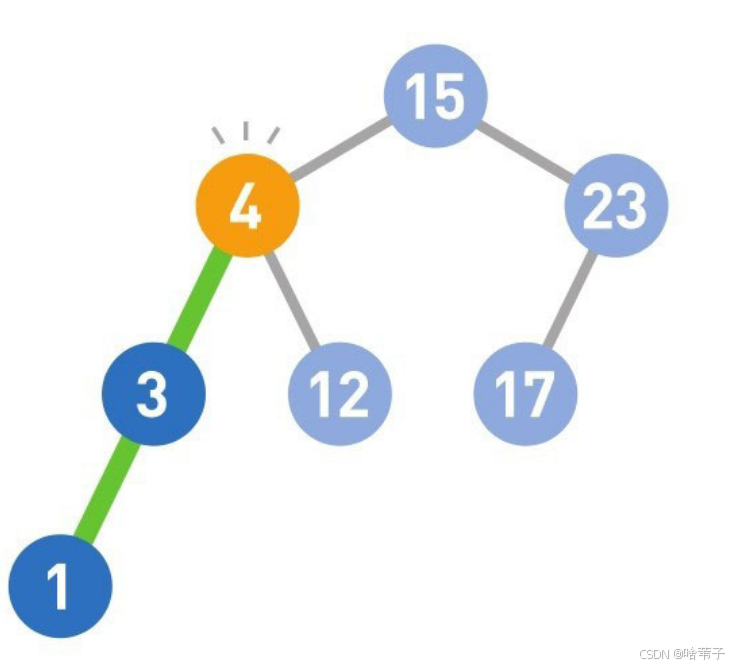
哈希表
我们前面提到数组的时候,它相对于列表查找很方便。只要知道要查找数据的数组下标,就可以直接访问对应的内存地址。但是怎么知道要查找数据的数组下标呢?比如说有很多人的姓名和性别,这是需要储存的数据。知道小明是男生,把他储存在数组里,不知道他的下标是什么。这个时候还是需要一个个访问,查找依旧比较耗时。这样怎么解决呢?
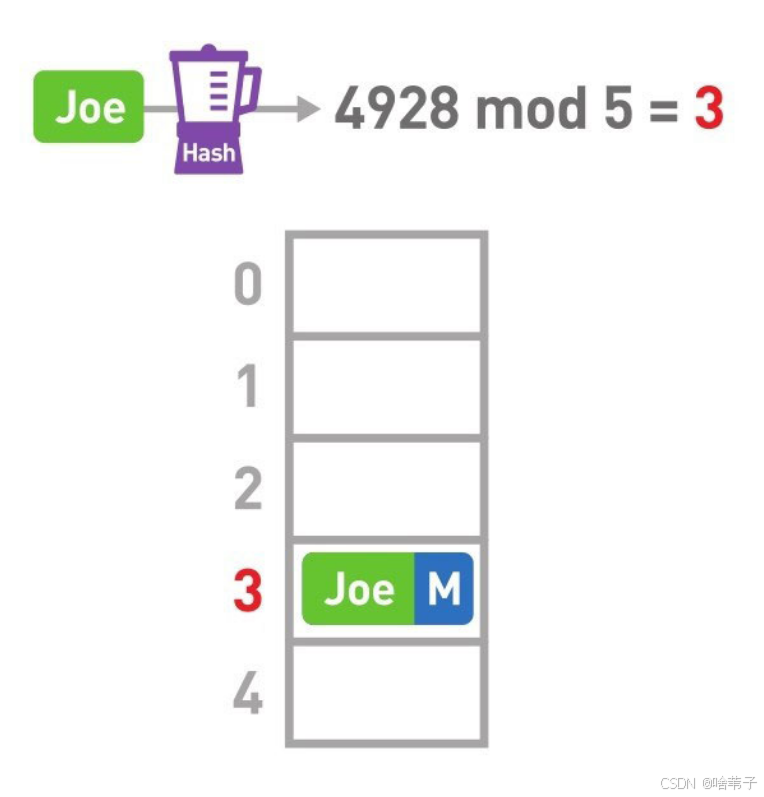
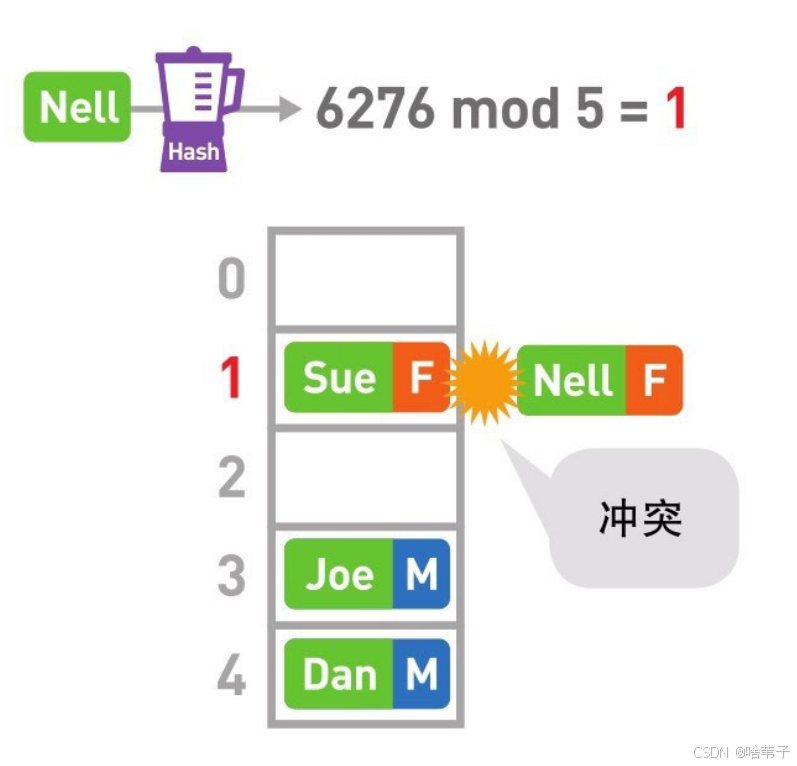
就要用到哈希表。哈希表首先要用到哈希函数,将小明的名字输入到函数里,就可以得到一个哈希值,也就是一个数字。然后用这个数字对整个数组的个数取余,就可以得到对应的数组下标位置,把它储存在数组的那个位置,查找时就很方便了。
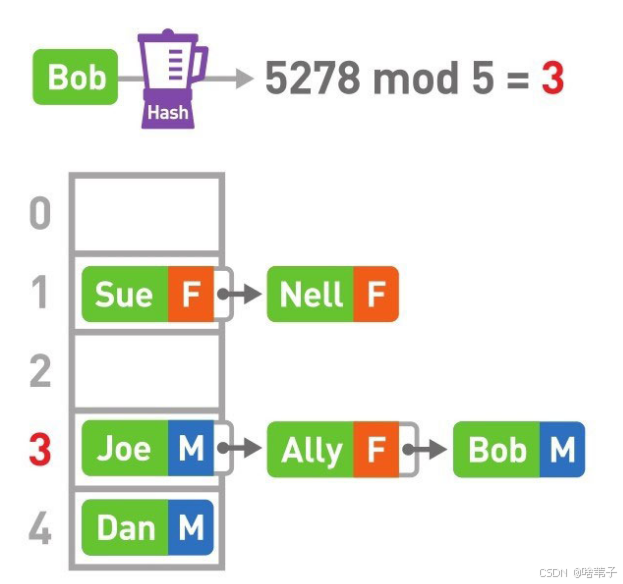
但是有一种情况,有可能小明和小美的哈希值不一样,但除以某一个数时余数一样,就会储存在同一个位置,这种情况叫做冲突,那怎么解决呢?
用一个链表,在同一个位置后面接一个链表就行。
本文所用的图片均来自《我的第一本算法书》


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









