






1.Spark框架与Hadoop的不同
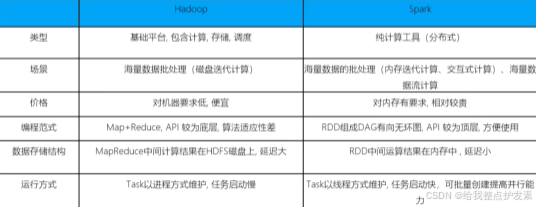
Spark相对于MapReduce又巨大的性能优势,官方说法内存中快了一百倍。
但是Hadoop由于HDFS和YARN是许多大数据体系的核心框架,所以不能代替。
2.Spark的框架模块
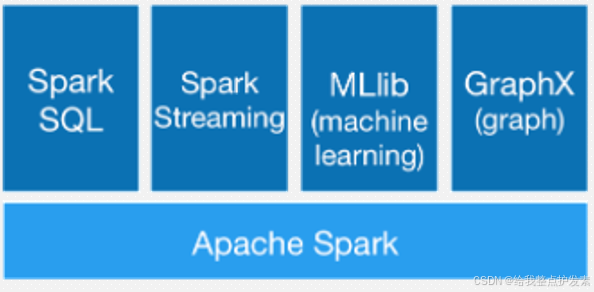
Spark Core:Spark的核心,Spak核心功能均由SparkCore模块提供,是Spark运行的基础。Spark Core以RDD为数据抽象,提供Pvthon、Java、Scala、R语言的API,可以编程进行海量离线数据批处理计算。
Sparksql:基于sparkcore之上,提供结构化数据的处理模块。SparkSQL支持以SQL语言对数据进行处理,SparksQl本身针对离线计算场景。同时基于SparksQL,Spark提供Structuredstreaming模块,可以以SparksQl为基础,进行数据的流式计算。
SparkStreaming:以SparkCore为基础,提供数据的流式计算功能。
MLlib:以sparkcore为基础,进行机器学习计算,内置了大量的机器学习库和API算法等。方便用户以分布式计算的模式进行机器学习讦算。
GraphX:以sparkcore为基础,进行图计算,提供了大量的图计算API,方便用于以分布式计算模式进行图计算。
3.Spark的运行模式
本地模式(单机):开发和测试
集群模式(standalone,hadoop yarn,kubernetes):生产环境
云模式:运行在云平台上
4.Spark的架构角色(对比yarn)
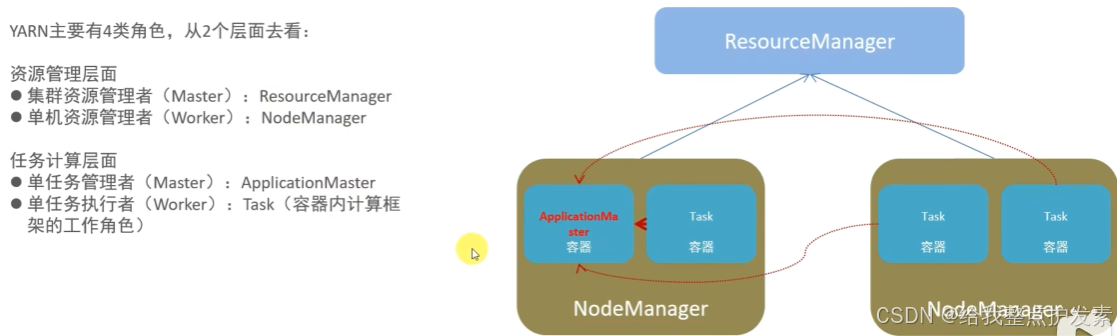
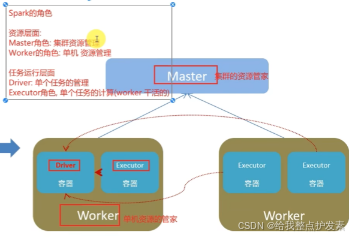
5.Spark能解决哪些问题?
海量数据的计算,可以进行离线批处理以及实时流计算。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









