






一、开篇:遇见爬虫
在如今的 互联网时代,大家有没有想过,当你在搜索引擎里输入关键词,瞬间就能得到海量相关信息;当你网购时,电商平台能迅速给出同款商品在不同店铺的价格对比;又或是各类资讯类 APP 总能精准推送你感兴趣的新闻,这背后究竟是什么在发挥神奇作用呢?其实,有个名为 “爬虫” 的 “幕后英雄” 功不可没。简单来说,爬虫就像是互联网世界里不知疲倦的 “小探险家”,按照预先设定的规则,自动穿梭于各个网页之间,把它发现的有用信息抓取并收集起来,再呈现到我们面前。
互联网时代,大家有没有想过,当你在搜索引擎里输入关键词,瞬间就能得到海量相关信息;当你网购时,电商平台能迅速给出同款商品在不同店铺的价格对比;又或是各类资讯类 APP 总能精准推送你感兴趣的新闻,这背后究竟是什么在发挥神奇作用呢?其实,有个名为 “爬虫” 的 “幕后英雄” 功不可没。简单来说,爬虫就像是互联网世界里不知疲倦的 “小探险家”,按照预先设定的规则,自动穿梭于各个网页之间,把它发现的有用信息抓取并收集起来,再呈现到我们面前。
二、爬虫究竟是什么

从专业角度讲,爬虫是一种按照一定规则,自动抓取互联网信息的程序或者脚本。它还有很多有趣的别称,像是 “网页蜘蛛”“网络机器人”,光听名字,是不是就感觉它像个在网络世界里忙碌织网、到处探索的小精灵?爬虫技术的起源其实和搜索引擎的发展紧密相连,早期搜索引擎为了能给用户提供全面且精准的搜索结果,就需要有一种工具能够快速遍历网页,把分散在各处的信息收集整合,于是爬虫技术应运而生。它可以从网页的起始链接出发,沿着页面里的超链接 “一路前行”,深入到网站的各个角落,将文字、图片、链接等各类数据一一抓取,然后带回到 “大本营” 进行后续的整理、索引,这样一来,当你搜索时,就能快速获取相关信息啦。
三、爬虫的 “骨骼内脏”
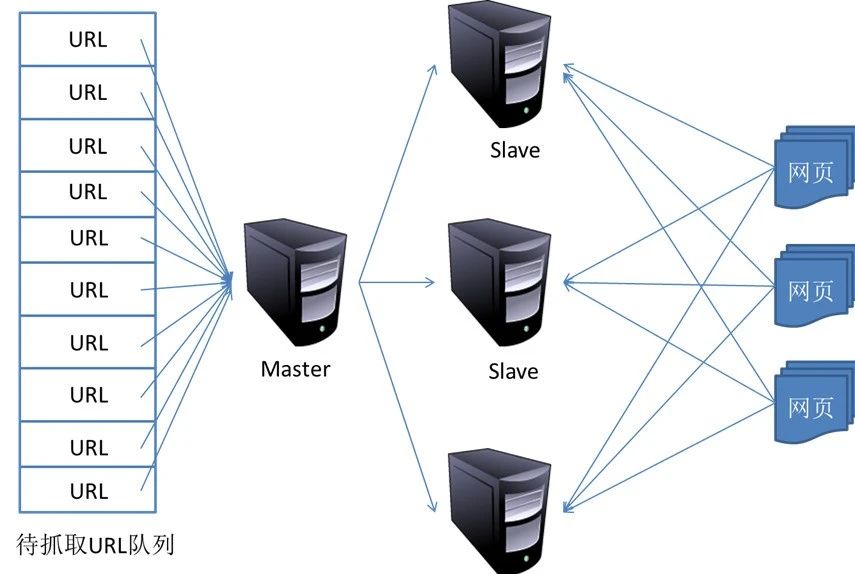
(一)基本结构
别看爬虫功能强大,它的基本结构其实并不复杂,主要由四部分构成。首先是 URL 管理器,它就像是一位严谨的 “管家”,精心管理着待爬取和已爬取的 URL 。一方面,它要确保不会让爬虫重复抓取相同的 URL,陷入无用的 “死循环”;另一方面,当发现新的链接时,它又能有条不紊地将其加入待爬取队列。打个比方,如果把网页比作一个个神秘的房间,URL 就是打开房间的钥匙,而 URL 管理器就是拿着钥匙串、清楚知道哪些房间已经探索过、哪些还等着开启的那个 “智慧向导”。
紧接着是网页下载器,它扮演的角色类似于快递员,任务是根据 URL 管理器提供的 “地址”,去对应的网页把内容 “取回来”。不过在这个过程中,它还得耍点 “小聪明”,进行一些伪装,让自己看起来像是普通的浏览器在访问,不然很容易被网站察觉是爬虫在 “搞小动作”,进而被拒之门外。
再就是网页解析器,这位 “拆解大师” 登场了,它把网页下载器带回来的网页内容当作复杂的机械装置,按照我们设定的规则,将里面有价值的信息,比如文本、图片链接、数据表格等精准拆解出来,为后续的数据处理做好准备。
最后是数据存储器,它无疑是可靠的 “仓库管理员”,把网页解析器提取出的珍贵数据收纳好,根据需求存储到本地文件、数据库等不同的地方,方便后续随时取用。这四个部分紧密协作,就像一条高效的流水线,让爬虫得以顺畅地运转起来。
(二)工作流程
了解完结构,咱们再来深入探究下爬虫的工作流程,大致可以分为四个关键步骤。第一步是 Request 发起请求,爬虫程序模拟浏览器发送请求,这个请求里包含了目标网址、请求头(就像我们去拜访别人时递上的名片,告知对方自己的一些基本信息,比如使用的浏览器类型等)等信息,向目标服务器礼貌地 “敲门”,询问是否可以获取网页内容。
当服务器收到请求后,如果一切正常,就会给予回应,这就是 Reponse 获取响应阶段。爬虫会接收到服务器返回的网页数据,这里的数据类型多种多样,可能是 HTML 格式的网页文本,也可能是 JSON 格式的数据,甚至是图片、视频等二进制文件,就好比收到了来自服务器的 “包裹”,里面装着各种 “宝贝”。
接下来就是解析内容的关键环节,如同打开包裹后仔细甄别里面的物品。如果收到的是 HTML 网页,爬虫就会动用正则表达式、BeautifulSoup 等工具,按照预先设定的规则,把网页里的标题、正文、链接等有用信息筛选出来;要是收到的是 JSON 数据,那就用相应的 JSON 解析方法,精准提取所需数据。
最后一步便是保存数据,经过前面的重重工序,终于到了收获的时候。解析出来的目标数据会被爬虫根据我们提前设定好的存储方式,妥善保存到本地,可能是以文本文件的形式记录,方便后续直接查看;也可能存入数据库,方便日后进行复杂的查询、分析操作,至此,一次完整的爬虫工作流程就大功告成啦。
四、爬虫的 “家族成员”
(一)通用爬虫
通用爬虫可是爬虫家族里的 “老大哥”,像谷歌、百度这类搜索引擎背后,就离不开它的身影。它的 “野心” 很大,目标是遍历整个互联网,把海量的网页信息一股脑儿抓取回来。它就像一个不知疲倦的 “信息拾荒者”,从一个起始网页链接出发,沿着网页里的超链接不断拓展 “版图”,日夜兼程地穿梭在各个网站之间,将抓取到的网页内容存储起来,经过一系列复杂的索引、排序处理后,当你在搜索引擎输入关键词,就能迅速给你呈现出相关的网页列表,让你轻松畅游信息海洋。但通用爬虫也有它的 “小烦恼”,由于要抓取的网页实在太多,存储和处理这些海量数据就成了个大难题,而且有时候它抓取回来的信息可能并不都是你想要的,会夹杂着不少 “杂质”。
(二)聚焦爬虫
聚焦爬虫则像是一位 “专业猎手”,目标明确,专注于特定的主题领域。比如说你想研究人工智能领域的最新论文,聚焦爬虫就能按照你设定的关键词、网址范围等条件,精准地深入相关学术网站、论坛,把那些和人工智能紧密相关的论文标题、作者、摘要等信息一一抓取回来,摒弃掉无关的娱乐、体育等信息。它的优势就在于能高效满足特定人群对特定领域数据的迫切需求,节省大量的时间和资源,让你无需在茫茫信息中 “大海捞针”。
(三)增量爬虫
增量爬虫好似一位 “精明管家”,时刻关注着数据的变化。在如今信息瞬息万变的时代,网站内容随时都在更新,要是每次都全盘重新抓取,那可太耗费精力了。增量爬虫就采用巧妙的策略,通过对比网页的更新时间、数据指纹(类似给数据打上独特的 “标签”)等方式,快速识别出新增或有变动的网页,然后针对性地抓取这些变化的部分,既保证了数据的时效性,又大大减少了不必要的重复劳动,让数据更新变得高效又智能。
(四)深层爬虫
深层爬虫更像是一位 “神秘探险家”,专门挑战那些隐藏在网络深处的 “宝藏”。在互联网世界里,有大量的数据隐藏在需要用户输入关键词、填写表单才能访问的深层页面背后,普通爬虫对此束手无策,深层爬虫却能巧妙应对。它可以模拟用户登录、填写表单等操作,像突破一道道关卡一样,深入到这些深层网页,把那些珍贵的数据挖掘出来。比如一些专业数据库网站,只有登录后才能查看特定的学术资料、行业报告,深层爬虫就能帮你突破限制,获取到这些宝贵信息,为专业研究、商业分析等提供有力支持。
五、爬虫的 “超能力与隐患”
(一)强大本领
爬虫的本领在当今数字化浪潮中那可是展现得淋漓尽致。在搜索引擎领域,它就像是勤劳的 “小蜜蜂”,不停地穿梭于网页之间,将抓取到的海量信息带回来,经过复杂的索引、排序等处理,让我们在搜索框输入关键词后,瞬间就能获取精准且丰富的结果,畅游知识的海洋。在数据挖掘方面,它能深入各个行业网站,把珍贵的数据挖掘出来,助力企业分析市场趋势、消费者喜好,为产品研发、营销策略制定提供有力依据。像电商企业利用爬虫抓取竞品价格、销量数据,及时调整自身价格策略,抢占市场先机;科研人员通过爬虫收集学术资料,推动科研进展。对于新闻媒体而言,爬虫可以实时汇总各大新闻源的资讯,让我们无需在多个网站切换,就能第一时间知晓天下事,无论是突发新闻还是热点追踪,都不在话下。甚至在竞争情报领域,企业凭借爬虫监控对手官网、社交媒体动态,洞察对手新品发布、市场活动等情报,做到知己知彼。
(二)潜在风险
不过,爬虫这股 “神奇力量” 一旦被滥用,可就会引发诸多问题。一方面,许多网站都有自己的运营规则,明确规定了哪些内容可以被抓取、抓取的频率等,要是爬虫无视这些规则,肆意妄为,就会对网站的正常运行造成冲击,比如导致服务器负载过大,网站响应变慢甚至瘫痪。另一方面,爬虫在抓取数据时,很可能会不小心触碰到用户隐私的 “红线”,把一些包含个人敏感信息的数据收集起来,若这些数据被不当使用,后果不堪设想。更重要的是,从法律层面来看,我国的《网络安全法》等相关法律法规对网络数据的采集、使用有着严格规定,未经授权大规模抓取数据属于违法行为,一旦触犯,必将受到法律的制裁。
六、合法合规 “驾驭” 爬虫

既然爬虫存在风险,那如何才能合法合规地使用它呢?首先要设置合理的访问限制,不能一股脑儿地高频次向目标网站发起请求,要模拟正常用户的访问频率,比如每隔几秒访问一次页面,给网站服务器留出喘息的时间,避免造成过大压力。其次,抓取的数据范围务必遵循网站的 Robots 协议,这可是网站与爬虫之间的 “君子协定”,协议里明确规定了哪些页面、哪些数据允许抓取,哪些禁止触碰,严格遵守它,就能避免很多不必要的纠纷。再者,存储数据时要格外小心,确保数据来源合法,并且对数据做好安全防护,防止泄露。要是抓取的数据涉及个人信息,那更得慎之又慎,必须获得当事人明确授权,切不可私自挪用,只有在法律和道德的框架内 “驾驭” 爬虫,才能让它真正成为助力我们探索互联网世界、挖掘知识宝藏的得力工具,而非引发混乱的 “脱缰野马”。
七、结语:与爬虫共舞
爬虫技术无疑是当今数字化时代极为重要的一把 “利器”,它为我们打开了海量信息的大门,让知识获取、数据洞察变得前所未有的便捷。对于咱们程序员来说,学好爬虫技术,就等于多了一双 “有力的翅膀”,能在数据的天空中自由翱翔,挖掘出那些隐藏在网络深处的宝藏,无论是助力个人成长、攻克科研难题,还是为企业创造价值、推动行业发展,都有着不可估量的潜力。但请务必牢记,在享受爬虫带来的便利时,要始终将合法合规放在首位,严格遵守法律法规、尊重网站规则、保护用户隐私,让这股技术力量在有序的轨道上奔腾向前。展望未来,随着人工智能、机器学习等前沿技术的不断发展,爬虫技术必将与之深度融合,开启更加智能化、高效化的新篇章,让我们一起满怀期待,驾驭着这匹 “技术骏马”,在互联网的广袤草原上纵情驰骋,探索无尽的可能!
本人毕业到现在做Python八年多,现在大厂任职,工资从3k发的现在稳定3w左右,坚持下来真的没有那么难。这期间用过的累计的python网课,文件,资料,恐怕没人比我多,有人要咩,不收米米,不要就清内存删了,看图片拿走!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









