






全文单词统计:
可分为以下几个步骤:
1.读取文件,得到很长的字符串

2.把字符串拆分成一个一个的单词
3.统计每个单词出现的次数
4.排序

5.把结果写入到一个文件中
完整代码如下:
import java.io.PrintWriter
import scala.io.Source
object 全文单词统计 {
def main(args: Array[String]){
//1.读入文件内容
val content = Source.fromFile("1.text").mkString
println(content)
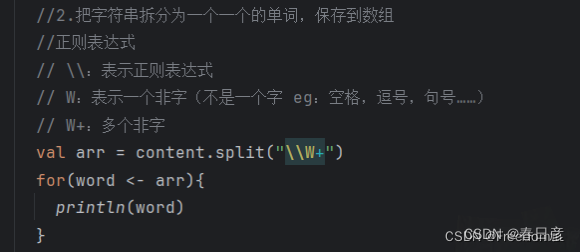
//2.把字符串拆分为一个一个的单词,保存到数组
//正则表达式
// \\:表示正则表达式
// W:表示一个非字(不是一个字 eg:空格,逗号,句号……)
// W+:多个非字
val arr = content.split("\\W+")
for(word <- arr){
println(word)
}
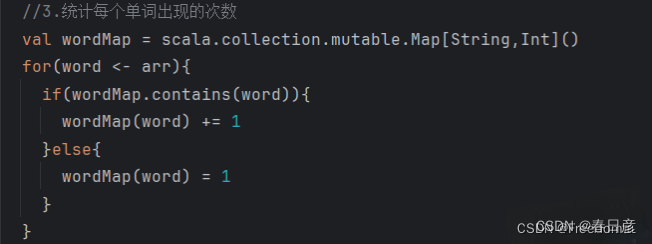
//3.统计每个单词出现的次数
val wordMap = scala.collection.mutable.Map[String,Int]()
for(word <- arr){
if(wordMap.contains(word)){
wordMap(word) += 1
}else{
wordMap(word) = 1
}
}
//4.排序。Map是无序,要对其进行排序,要先把数组转成序列。List,Array
println(wordMap.toList)
val orderWordList = wordMap.toList.sortWith((a,b)=> a._2 > b._2).filter(e=>e._1.length>2).slice(0,30)
for (e <- orderWordList){
println(e)
}
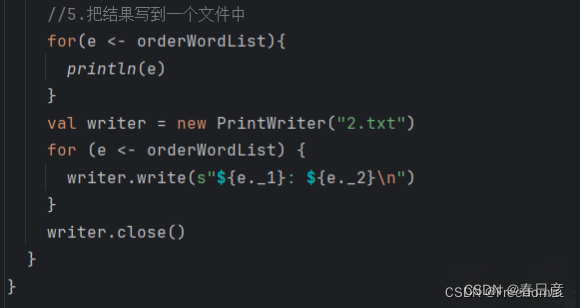
//5.把结果写到一个文件中
for(e <- orderWordList){
println(e)
}
val writer = new PrintWriter("2.txt")
for (e <- orderWordList) {
writer.write(s"${e._1}: ${e._2}\n")
}
writer.close()
}
}


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









