







搜索
ElasticSearch使用倒排索引,每个字段都被索引且可用于搜索,更是提供了丰富的搜索api,在海量数据下近实时实现近秒级的响应,基于Lucene的开源搜索引擎,为搜索引擎(全文检索,高亮,搜索推荐等)提供了检索的能力。 具体场景:
1. Stack Overflow(国外的程序异常讨论论坛),IT问题,程序的报错,提交上去,有人会跟你讨论和回答,全文检索,搜索相关问题和答案,程序报错了,就会将报错信息粘贴到里面去,搜索有没有对应的答案;
2. GitHub(开源代码管理),搜索上千亿行代码;
3. 电商网站,检索商品;
4. 日志数据分析,logstash采集日志,ElasticSearch进行复杂的数据分析(ELK技术,elasticsearch+logstash+kibana);
数据分析
ElasticSearch也提供了大量数据分析的api和丰富的聚合能力,支持在海量数据的基础上进行数据的分析和处理。具体场景:
爬虫爬取不同电商平台的某个商品的数据,通过ElasticSearch进行数据分析(各个平台的历史价格、购买力等等);
二、ElasticSearch架构
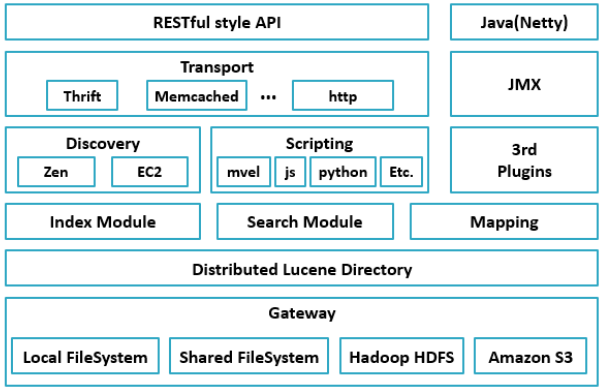
1. Gateway是ES用来存储索引的文件系统,支持多种类型。
2. Gateway的上层是一个分布式的lucene框架。
3. Lucene之上是ES的模块,包括:索引模块、搜索模块、映射解析模块等
4. ES模块之上是 Discovery、Scripting和第三方插件。Discovery是ES的节点发现模块,不同机器上的ES节点要组成集群需要进行消息通信,集群内部需要选举master节点,这些工作都是由Discovery模块完成。支持多种发现机制,如 Zen 、EC2、gce、Azure。Scripting用来支持在查询语句中插入javascript、python等脚本语言,scripting模块负责解析这些脚本,使用脚本语句性能稍低。ES也支持多种第三方插件。
5. 再上层是ES的传输模块和JMX.传输模块支持多种传输协议,如 Thrift、memecached、http,默认使用http。JMX是java的管理框架,用来管理ES应用。
6. 最上层是ES提供给用户的接口,可以通过RESTful接口和ES集群进行交互。
[[ 小提示:目前市场上开放源代码的最好全文检索引擎工具包就属于 Apache 的 Lucene了。但是 Lucene 只是一个工具包,它不是一个完整的全文检索引擎。Lucene 的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。目前以 Lucene 为基础建立的开源可用全文搜索引擎主要是 Solr 和 Elasticsearch。Solr 和 Elasticsearch 都是比较成熟的全文搜索引擎,能完成的功能和性能也基本一样。但是 ES 本身就具有分布式的特性和易安装使用的特点,而 Solr 的分布式需要借助第三方来实现,例如通过使用 ZooKeeper 来达到分布式协调管理。不管是 Solr 还是 Elasticsearch 底层都是依赖于 Lucene,而 Lucene 能实现全文搜索主要是因为它实现了倒排索引的查询结构。]]
三、ElasticSearch核心概念
Near Realtime (NRT)近实时:数据提交索引后,立马就可以搜索到。
Cluster集群:一个集群由一个唯一的名字标识,默认为“elasticsearch”。集群名称非常重要,具体相同集群名的节点才会组成一个集群。集群名称可以在配置文件中指定。集群中有多个节点,其中有一个为主节点,这个主节点是可以通过选举产生的,主从节点是对于集群内部来说的。ElasticSearch的一个概念就是去中心化,字面上理解就是无中心节点,这是对于集群外部来说的,因为从外部来看ElasticSearch集群,在逻辑上是个整体,你与任何一个节点的通信和与整个ElasticSearch集群通信是等价的。
Node 节点:存储集群的数据,参与集群的索引和搜索功能。像集群有名字,节点也有自己的名称,默认在启动时会以一个随机的UUID的前七个字符作为节点的名字,你可以为其指定任意的名字。通过集群名在网络中发现同伴组成集群。一个节点也可是集群。每一个运行实例称为一个节点,每一个运行实例既可以在同一机器上,也可以在不同的机器上。所谓运行实例,就是一个服务器进程,在测试环境中可以在一台服务器上运行多个服务器进程,在生产环境中建议每台服务器运行一个服务器进程。
Index 索引: 一个索引是一个文档的集合(等同于solr中的集合)。每个索引有唯一的名字,通过这个名字来操作它。一个集群中可以有任意多个索引。索引作动词时,指索引数据、或对数据进行索引。Type 类型:指在一个索引中,可以索引不同类型的文档,如用户数据、博客数据。从6.0.0 版本起已废弃,一个索引中只存放一类数据。Elasticsearch里的索引概念是名词而不是动词,在elasticsearch里它支持多个索引。 一个索引就是一个拥有相似特征的文档的集合。比如说,你可以有一个客户数据的索引,另一个产品目录的索引,还有一个订单数据的索引。一个索引由一个名字来 标识(必须全部是小写字母的),并且当我们要对这个索引中的文档进行索引、搜索、更新和删除的时候,都要使用到这个名字。在一个集群中,你能够创建任意多个索引。
Document 文档:被索引的一条数据,索引的基本信息单元,以JSON格式来表示。一个文档是一个可被索引的基础信息单元。比如,你可以拥有某一个客户的文档、某一个产品的一个文档、某个订单的一个文档。文档以JSON格式来表示,而JSON是一个到处存在的互联网数据交互格式。在一个index/type里面,你可以存储任意多的文档。注意,一个文档物理上存在于一个索引之中,但文档必须被索引/赋予一个索引的type。
Shard 分片:在创建一个索引时可以指定分成多少个分片来存储。每个分片本身也是一个功能完善且独立的“索引”,可以被放置在集群的任意节点上(分片数创建索引时指定,创建后不可改了。备份数可以随时改)。索引分片,ElasticSearch可以把一个完整的索引分成多个分片,这样的好处是可以把一个大的索引拆分成多个,分布到不同的节点上。构成分布式搜索。分片的数量只能在索引创建前指定,并且索引创建后不能更改。分片的好处:
**-**允许我们水平切分/扩展容量
**-**可在多个分片上进行分布式的、并行的操作,提高系统的性能和吞吐量。
Replication 备份: 一个分片可以有多个备份(副本)。备份的好处:
- 高可用扩展搜索的并发能力、吞吐量。
- 搜索可以在所有的副本上并行运行。
primary shard:主分片,每个文档都存储在一个分片中,当你存储一个文档的时候,系统会首先存储在主分片中,然后会复制到不同的副本中。默认情况下,一个索引有5个主分片。你可以在事先制定分片的数量,当分片一旦建立,分片的数量则不能修改。
replica shard:副本分片,每一个分片有零个或多个副本。副本主要是主分片的复制,其中有两个目的:
- 增加高可用性:当主分片失败的时候,可以从副本分片中选择一个作为主分片。
- 提高性能:当查询的时候可以到主分片或者副本分片中进行查询。默认情况下,一个主分配有一个副本,但副本的数量可以在后面动态的配置增加。副本必须部署在不同的节点上,不能部署在和主分片相同的节点上。
term索引词:在elasticsearch中索引词(term)是一个能够被索引的精确值。foo,Foo几个单词是不相同的索引词。索引词(term)是可以通过term查询进行准确搜索。
text文本:是一段普通的非结构化文字,通常,文本会被分析称一个个的索引词,存储在elasticsearch的索引库中,为了让文本能够进行搜索,文本字段需要事先进行分析;当对文本中的关键词进行查询的时候,搜索引擎应该根据搜索条件搜索出原文本。
analysis:分析是将文本转换为索引词的过程,分析的结果依赖于分词器,比如: FOO BAR, Foo-Bar, foo bar这几个单词有可能会被分析成相同的索引词foo和bar,这些索引词存储在elasticsearch的索引库中。当用 FoO:bAR进行全文搜索的时候,搜索引擎根据匹配计算也能在索引库中搜索出之前的内容。这就是elasticsearch的搜索分析。
routing路由:当存储一个文档的时候,他会存储在一个唯一的主分片中,具体哪个分片是通过散列值的进行选择。默认情况下,这个值是由文档的id生成。如果文档有一个指定的父文档,从父文档ID中生成,该值可以在存储文档的时候进行修改。
type类型:在一个索引中,你可以定义一种或多种类型。一个类型是你的索引的一个逻辑上的分类/分区,其语义完全由你来定。通常,会为具有一组相同字段的文档定义一个类型。比如说,我们假设你运营一个博客平台 并且将你所有的数据存储到一个索引中。在这个索引中,你可以为用户数据定义一个类型,为博客数据定义另一个类型,当然,也可以为评论数据定义另一个类型。
template:索引可使用预定义的模板进行创建,这个模板称作Index templatElasticSearch。模板设置包括settings和mappings。
mapping:映射像关系数据库中的表结构,每一个索引都有一个映射,它定义了索引中的每一个字段类型,以及一个索引范围内的设置。一个映射可以事先被定义,或者在第一次存储文档的时候自动识别。
field:一个文档中包含零个或者多个字段,字段可以是一个简单的值(例如字符串、整数、日期),也可以是一个数组或对象的嵌套结构。字段类似于关系数据库中的表中的列。每个字段都对应一个字段类型,例如整数、字符串、对象等。字段还可以指定如何分析该字段的值。
source field:默认情况下,你的原文档将被存储在_source这个字段中,当你查询的时候也是返回这个字段。这允许您可以从搜索结果中访问原始的对象,这个对象返回一个精确的json字符串,这个对象不显示索引分析后的其他任何数据。
id:一个文件的唯一标识,如果在存库的时候没有提供id,系统会自动生成一个id,文档的index/type/id必须是唯一的。
recovery:代表数据恢复或叫数据重新分布,ElasticSearch在有节点加入或退出时会根据机器的负载对索引分片进行重新分配,挂掉的节点重新启动时也会进行数据恢复。
River:代表ElasticSearch的一个数据源,也是其它存储方式(如:数据库)同步数据到ElasticSearch的一个方法。它是以插件方式存在的一个ElasticSearch服务,通过读取river中的数据并把它索引到ElasticSearch中,官方的river有couchDB的,RabbitMQ的,Twitter的,Wikipedia的,river这个功能将会在后面的文件中重点说到。
gateway:代表ElasticSearch索引的持久化存储方式,ElasticSearch默认是先把索引存放到内存中,当内存满了时再持久化到硬盘。当这个ElasticSearch集群关闭再重新启动时就会从gateway中读取索引数据。ElasticSearch支持多种类型的gateway,有本地文件系统(默认), 分布式文件系统,Hadoop的HDFS和amazon的s3云存储服务。
discovery.zen:代表ElasticSearch的自动发现节点机制,ElasticSearch是一个基于p2p的系统,它先通过广播寻找存在的节点,再通过多播协议来进行节点之间的通信,同时也支持点对点的交互。
Transport:代表ElasticSearch内部节点或集群与客户端的交互方式,默认内部是使用tcp协议进行交互,同时它支持http协议(json格式)、thrift、servlet、memcached、zeroMQ等的传输协议(通过插件方式集成)。
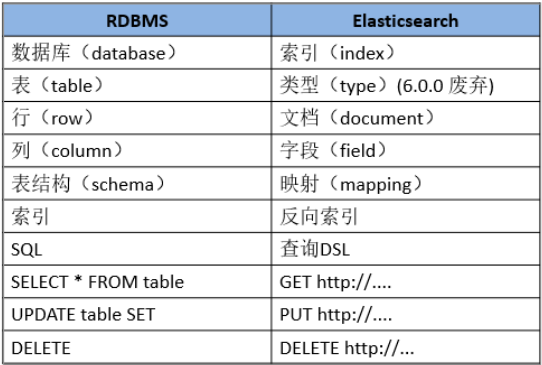
对比RDBMS (关系型数据库管理系统)
四、ElasticSearch配置
1. 数据目录和日志目录,生产环境下应与软件分离

2. 数据目录可以有多个

3. 所属的集群名,默认为 elasticsearch ,可自定义

4. 节点名,默认为 UUID前7个字符,可自定义

5. network.host IP绑定,默认绑定的是[“127.0.0.1”, “[::1]”]回环地址,集群下要服务间通信,需绑定一个ipv4或ipv6地址或0.0.0.0

6. http.port: 9200-9300
对外服务的http 端口, 默认 9200-9300 。可以为它指定一个值或一个区间,当为区间时会取用区间第一个可用的端口。
7. transport.tcp.port: 9300-9400
节点间交互的端口, 默认 9300-9400 。可以为它指定一个值或一个区间,当为区间时会取用区间第一个可用的端口。
8. Discovery Config 节点发现配置
ES中默认采用的节点发现方式是 zen(基于组播(多播)、单播)。在应用于生产前有两个重要参数需配置
9. discovery.zen.ping.unicast.hosts: [“host1”,“host2:port”,“host3[portX-portY]”]
单播模式下,设置具有master资格的节点列表,新加入的节点向这个列表中的节点发送请求来加入集群。
10. discovery.zen.minimum_master_nodes: 1
这个参数控制的是,一个节点需要看到具有master资格的节点的最小数量,然后才能在集群中做操作。官方的推荐值是(N/2)+1,其中N是具有master资格的节点的数量。
11. transport.tcp.compress: false
是否压缩tcp传输的数据,默认false
12. http.cors.enabled: true
是否使用http协议对外提供服务,默认true
13. http.max_content_length: 100mb
http传输内容的最大容量,默认100mb
14. node.master: true
指定该节点是否可以作为master节点,默认是true。ES集群默认是以第一个节点为master,如果该节点出故障就会重新选举master。
15. node.data: true
该节点是否存索引数据,默认true。
16. discover.zen.ping.timeout: 3s
设置集群中自动发现其他节点时ping连接超时时长,默认为3秒。在网络环境较差的情况下,增加这个值,会增加节点等待响应的时间,从一定程度上会减少误判。
17. discovery.zen.ping.multicast.enabled: false
是否启用多播来发现节点。
18. Jvm heap 大小设置
生产环境中一定要在jvm.options中调大它的jvm内存。
19. JVM heap dump path 设置
生产环境中指定当发生OOM异常时,heap的dump path,好分析问题。在jvm.options中配置:
-XX:HeapDumpPath=/var/lib/elasticsearch
五、ElasticSearch安装配置手册
1)环境要求
Elasticsearch 6.0版本至少需要JDK版本1.8。
可以使用java -version 命令查看JDK版本。
2)安装步骤
在ES 官网下载ES安装包,现以6.1.1版本为例。
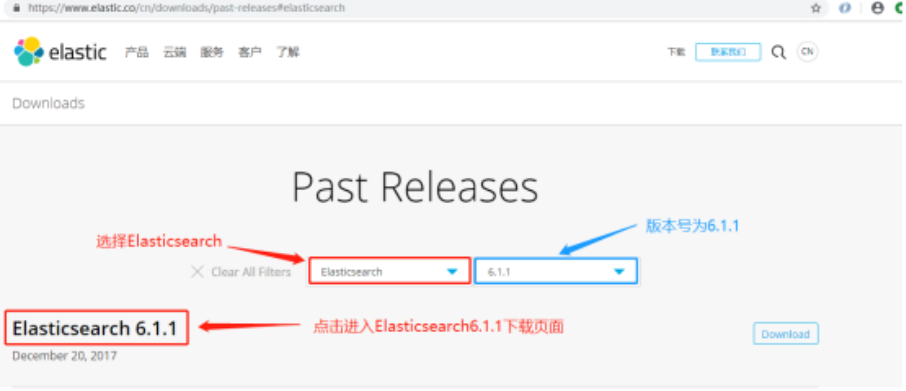
**1.**搜索历史版本,找到ES6.1.1版本下载连接。
https://www.elastic.co/cn/downloads/past-releases#elasticsearch
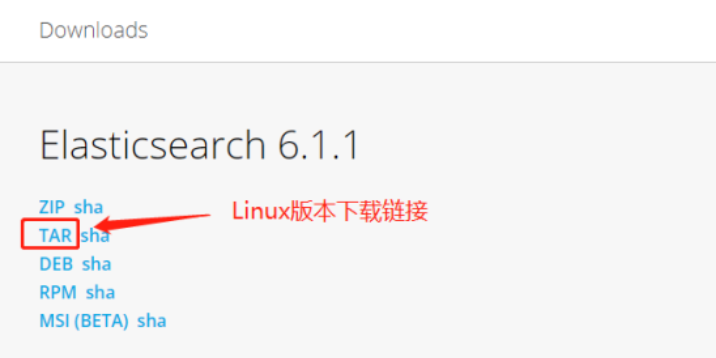
**2.**将下载好的安装包上传至需要安装的服务器目录下并解压。
cd /opt/gov
tar -zxvf elasticsearch-6.1.1.tar.gz
3. 解压完毕
文件夹elasticsearch-6.1.1 为elasticsearch-6.1.1所在目录。
3)配置Elasticsearch
1. 进入Elasticsearch-6.1.1所在目录结构,其中config文件夹为es配置文件所在位置,进入config文件夹。
2. 修改elasticsearch.yml文件中的集群名称和节点名称
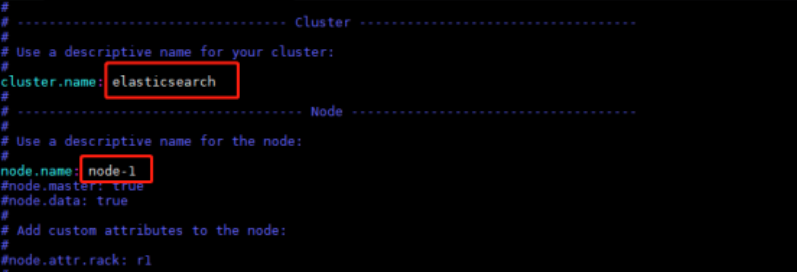
cluster.name(集群名称) 和node.name(节点名称) 可以自己配置简单易懂的值。node.name为节点名称,如果多个es实例,可加上数字1.2.3进行区分,方便查看日志和区分节点,简单易懂。如果该es集群用于落地skywalking的apm-collector数据,建议将cluster.name配置为cluster.name: CollectorDBCluster,即该名称需要和skywalking的collector配置文件一致。同一集群下多个es节点的cluster.name应该保持一致。
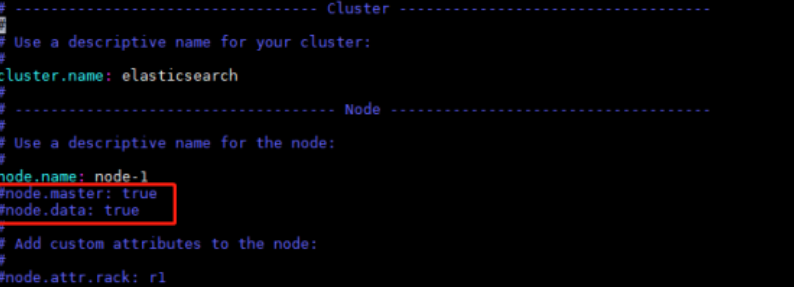
node.master指定该节点是否有资格被选举成为master,默认是true,elasticsearch默认集群中的第一台启动的机器为master,如果这台机挂了就会重新选举master。
node.data指定该节点是否存储索引数据,默认为true。如果节点配置node.master:false并且node.data: false,则该节点将起到负载均衡的作用。
3. 修改elasticsearch.yml文件中的数据和日志保存目录
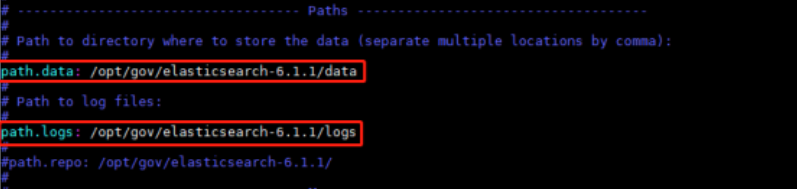
此处作为实例将data目录和logs目录建立在了elasticsearch-6.1.1下,这样是危险的。当es被卸载,数据和日志将完全丢失。可以根据具体环境将数据目录和日志目录保存到其他路径下以确保数据和日志完整、安全。
4. 修改elasticsearch.yml文件中的network信息
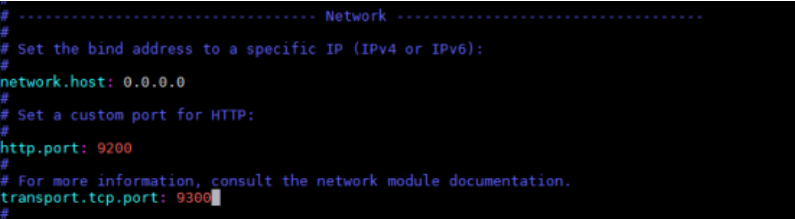
如果一台主机将要安装多个es实例,请自行更改端口,以免端口被占用。http.port默认端口为9200。transport.tcp.port 默认端口为9300。
5. 修改elasticsearch.yml文件中的discovery信息
discovery.zen.ping.unicast.hosts: [“192.168.0.8:9300”, “192.168.0.9:9300”,“192.168.0.10:9300”]
如果多个es实例组成集群,各节点ip+port信息用逗号分隔。其中port为各es实例中配置的transport.tcp.port。
discovery.zen.minimum_master_nodes: 1
设置这个参数来保证集群中的节点可以知道其它N个有master资格的节点。默认为1,对于大的集群来说,可以设置大一点的值(2-4)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









