



第一次用Python爬虫的时候把自己都惊到了 - 不到30秒,一整本《斗破大陆》就乖乖躺在了我的电脑里!

谁能想到,学Python没多久的我,现在也能写出这么牛的爬虫程序!从此告别熬夜追更,告别网站广告,想看就看,太爽了!
今天就教你用Python写个小爬虫,20行代码实现自动下载小说,学会后你就是下一个爬虫工程师!
Python爬虫的两把称手小刀
记住,写爬虫最重要的就是这两个Python库,它们就像是你的左右手:
import requests # 负责发请求,就像你打开浏览器 from bs4 import BeautifulSoup # 负责解析网页,就像你用眼睛看内容 # 安装命令 # pip install requests # pip install beautifulsoup4
温馨提示:每个Python爬虫工程师都得装这俩库,要是安装报错,试试在命令前加个 python -m,这个小技巧能解决80%的安装问题。
发送请求,爬虫第一步
写爬虫最关键的是伪装成普通用户,不然分分钟被网站拦截:
# 这样写是会被网站拒绝的!❌ response = requests.get(url) # Python爬虫正确姿势 ✅ headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36', 'Referer': 'http://www.example.com' # 假装是从正常网页来的 } response = requests.get(url, headers=headers, timeout=5) # 超时5秒就放弃 response.encoding = 'utf-8' # 中文显示才不会乱码 # 调试技巧 print(f'状态码: {response.status_code}') # 200就是成功 print(f'页面内容: {response.text[:100]}') # 偷偷看看内容对不对
温馨提示:每个成功的Python爬虫都得带headers,不然分分钟被当成机器人轰出门!我第一次就是光着头就上,结果被网站拉黑了…
解析网页,爬虫的核心技能
网页内容到手了,接下来就是要用Python爬虫的第二个神器BeautifulSoup来提取内容:
# 创建解析器 soup = BeautifulSoup(response.text, 'html.parser') # 找到章节列表 chapter_links = soup.select('.chapter-list a') # CSS选择器,准确定位目标 # 存储章节信息 chapters = [] for link in chapter_links: title = link.text.strip() # strip()去掉多余空格 href = 'http://www.example.com' + link['href'] chapters.append((title, href))
温馨提示:写爬虫最烦人的就是定位元素,按F12打开网页源代码,找准目标元素的特征,就像找宝藏一样!
自动下载,爬虫的最终目标
有了章节链接,就可以开始愉快地下载了:
with open('我的小说.txt', 'w', encoding='utf-8') as f: # 显示总进度 for index, (title, link) in enumerate(chapters, 1): try: print(f'正在下载 [{index}/{len(chapters)}] {title}') # 获取章节内容 chapter = requests.get(link, headers=headers) chapter.encoding = 'utf-8' # 解析章节正文 chapter_soup = BeautifulSoup(chapter.text, 'html.parser') content = chapter_soup.select_one('.chapter-content').text.strip() # 写入文件 f.write(f'\n{title}\n\n{content}\n') # 防止爬虫速度太快 time.sleep(1) # 每章暂停1秒 except Exception as e: print(f'这章出问题了:{title},错误信息:{e}')
温馨提示:写爬虫要讲武德,time.sleep()是必须的!我之前太激动,爬太快被封了IP,老老实实每章等1秒就没事了。
Python爬虫完整版

不得不说,第一次用Python写爬虫的时候,那叫一个激动!看着一章章的内容乖乖往下载文件里钻,简直比看小说还过瘾。

由领取此份Python代码****👉 点击链接免费领取【保证100%免费】

掌握了这个技巧,你就能:批量下载小说收藏,把喜欢的网页内容保存下来,改改代码,爬取其他类型的内容~
**这份代码已打包好,需要的同学们,可以:** 点击链接免费领取【保证100%免费】**
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后给大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
包括:Python激活码+安装包、Python web开发,Python爬虫,Python数据分析,人工智能、机器学习、自动化测试带你从零基础系统性的学好Python!
Python学习大礼包

Python学习路线汇总
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。(全套教程文末领取哈)

Python必备开发工具

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
Python实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。


Python书籍和视频合集
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。
Python面试刷题

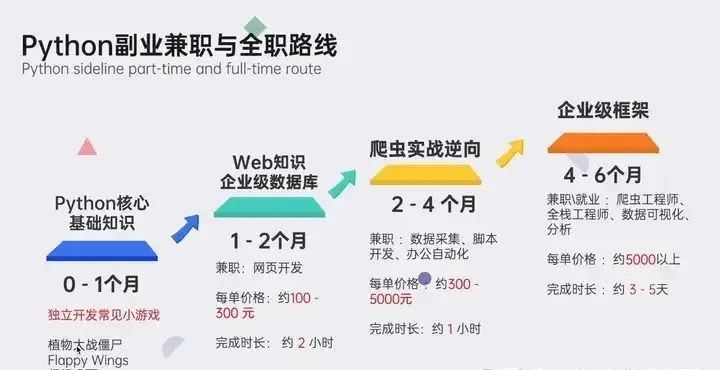
Python副业兼职路线,由领取2024年最新Python零基础学习资料****👉 点击链接免费领取【保证100%免费】
由领取2024年最新Python零基础学习资料****👉 点击链接免费领取【保证100%免费】
如果这篇文章对你有所帮助,还请花费2秒的时间**点个赞+在看+分享****,**让更多的人看到这篇文章,帮助他们走出误区。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









