




我们知道LLM(大语言模型)的底模是基于已经过期的公开数据训练出来的,对于新的知识或者私有化的数据LLM一般无法作答,此时LLM会出现“幻觉”。针对“幻觉”问题,一般的解决方案是采用RAG做检索增强。
但是我们不可能把所有数据都丢给LLM去学习,比如某个公司积累的某个行业的大量内部知识。此时就需要一个私有化的文档搜索工具了。
本文聊聊如何使用LangChain结合LLM快速做一个私有化的文档搜索工具。之前介绍过,LangChain几乎是LLM应用开发的第一选择,它的野心也比较大,它致力于将自己打造成LLM应用开发的最大社区。自然,它有这方面的成熟解决方案。
文末,还会向朋友们推荐一款非常好用的AI机器人和LLM API超市,价格实惠又稳定,还可以领一波福利。
1. RAG检索流程
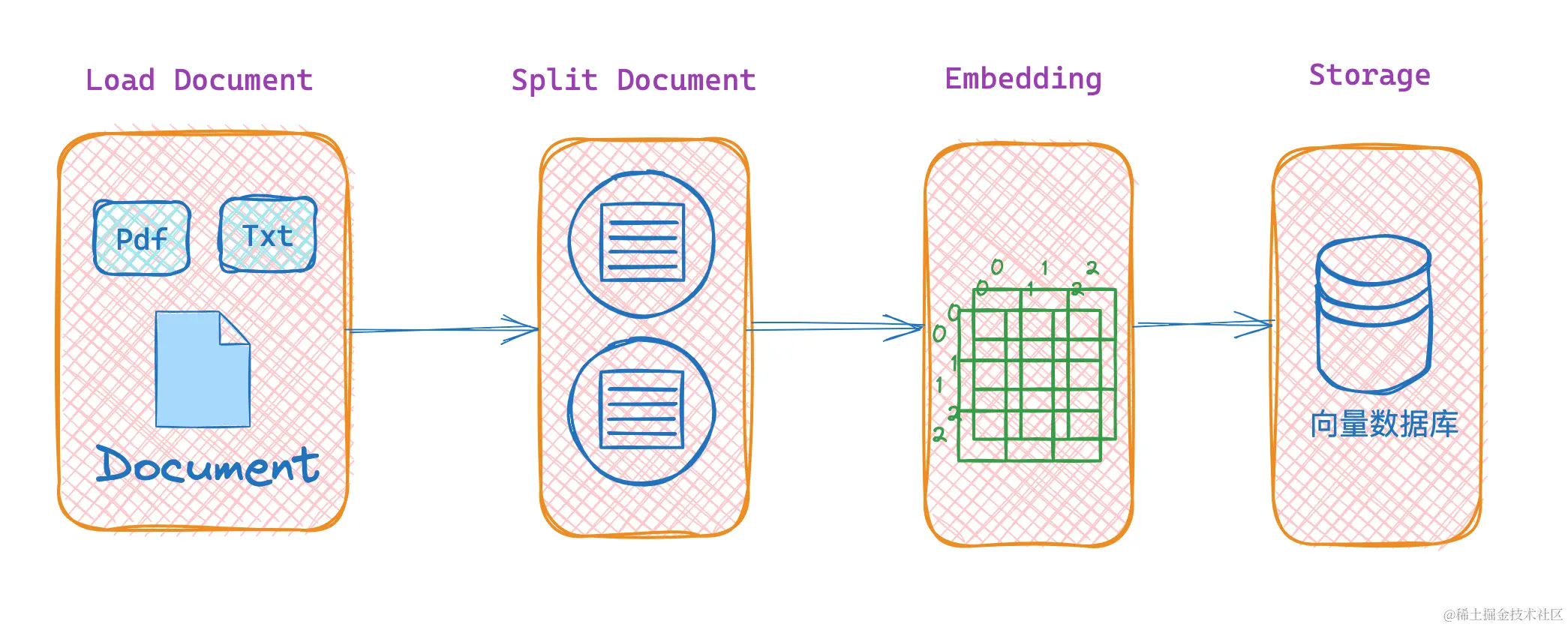
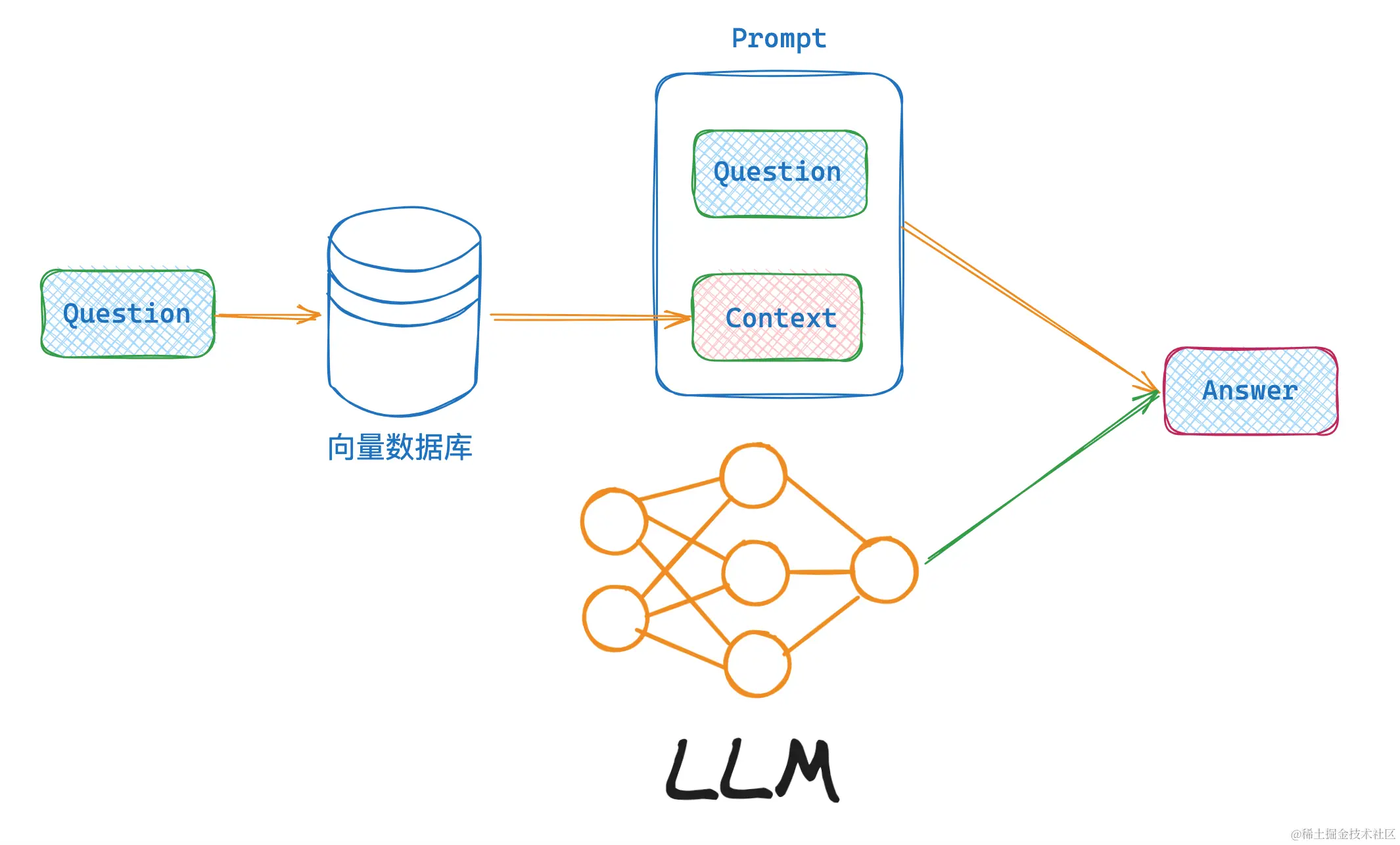
使用 LangChain 实现私有化文档搜索的主要流程,如下图所示:
复制代码文档加载 → 文档分割 → 文档嵌入 → 向量化存储 → 文档检索 → 生成回答
2. 代码实践细节
2.1. 文档加载
首先,我们需要加载文档数据。文档可以是各种格式,比如文本文件、PDF、Word 等。使用 LangChain,可以轻松地加载这些文档。下面以PDF为例:
ini复制代码from langchain_community.document_loaders import PyPDFLoader
loader = PyPDFLoader("./GV2.pdf")
docs = loader.load()
2.2. 文档分割
加载的文档通常会比较大,为了更高效地处理和检索,我们需要将文档分割成更小的段落或句子。LangChain 提供了便捷的文本分割工具,可以按句子、块长度等方式分割文档。
ini复制代码from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=50,
chunk_overlap=20,
separators=["\n", "。", "!", "?", ",", "、", ""],
add_start_index=True,
)
texts = text_splitter.split_documents(docs)
分割后的文档内容可以进一步用于生成向量。
2.3. 文档嵌入 Embeddings
文档分割后,我们需要将每一段文本转换成向量,这个过程称为文档嵌入。文档嵌入是将文本
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 848
848

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









