



解析:KMP算法所需的附加空间就是模式串的串长。
- KMP算法时间复杂度为O(m+n),空间复杂度为O(m)。 因为KMP算法涉及到next数组的存储,且next数组是基于模式串长度计算的
- BF算法(普通匹配算法):时间复杂度O(m*n);空间复杂度O(1)
- KMP算法:时间复杂度O(m+n);空间复杂度O(模式串长)
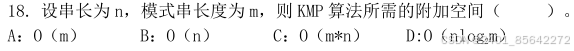
模式串匹配--KMP算法
字符串模式匹配
字符串的逻辑结构与线性表很类似,不同之处是字符串中的元素都是字符。对于字符串这一数据结构,寻找字符串中子串的位置是最重要的操作之一,查找字串位置的操作通常称为串的模式匹配。而KMP算法就是一种字符串模式匹配算法
朴素的模式匹配算法
假设我们的主串S=“goodgoogle”,子串T=“google”,我们需要在主串中找到子串的位置,比较朴素的想法是用两个指针(指针其实也就是下标i,j)分别指向主串和子串,如果两个指针指向的元素相同则指针后移,不相同则需要回退指针(主串指针回退到上次匹配首位的下一个位置,子串指针回退到开头位置),重复进行上述操作直到主串指针指向主串末尾,即如下所示:
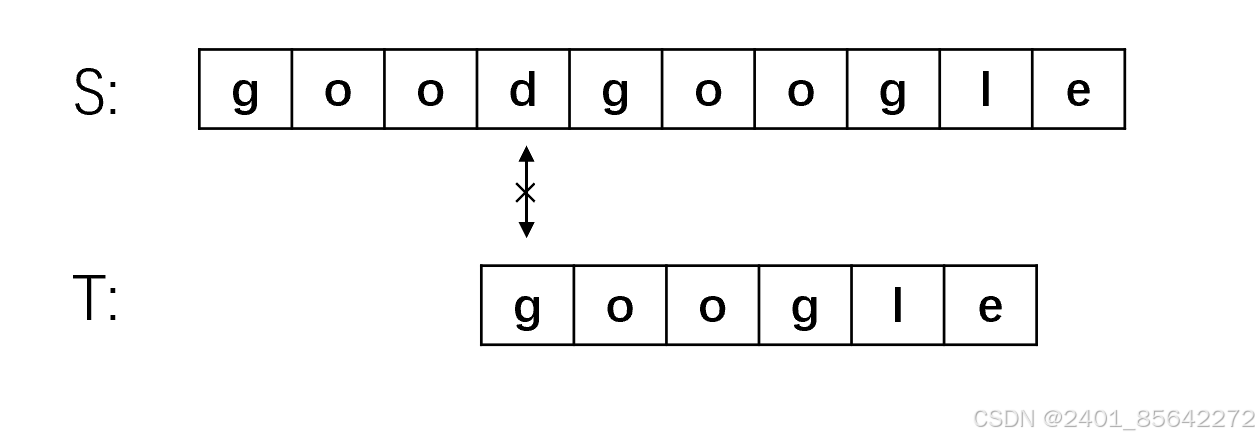
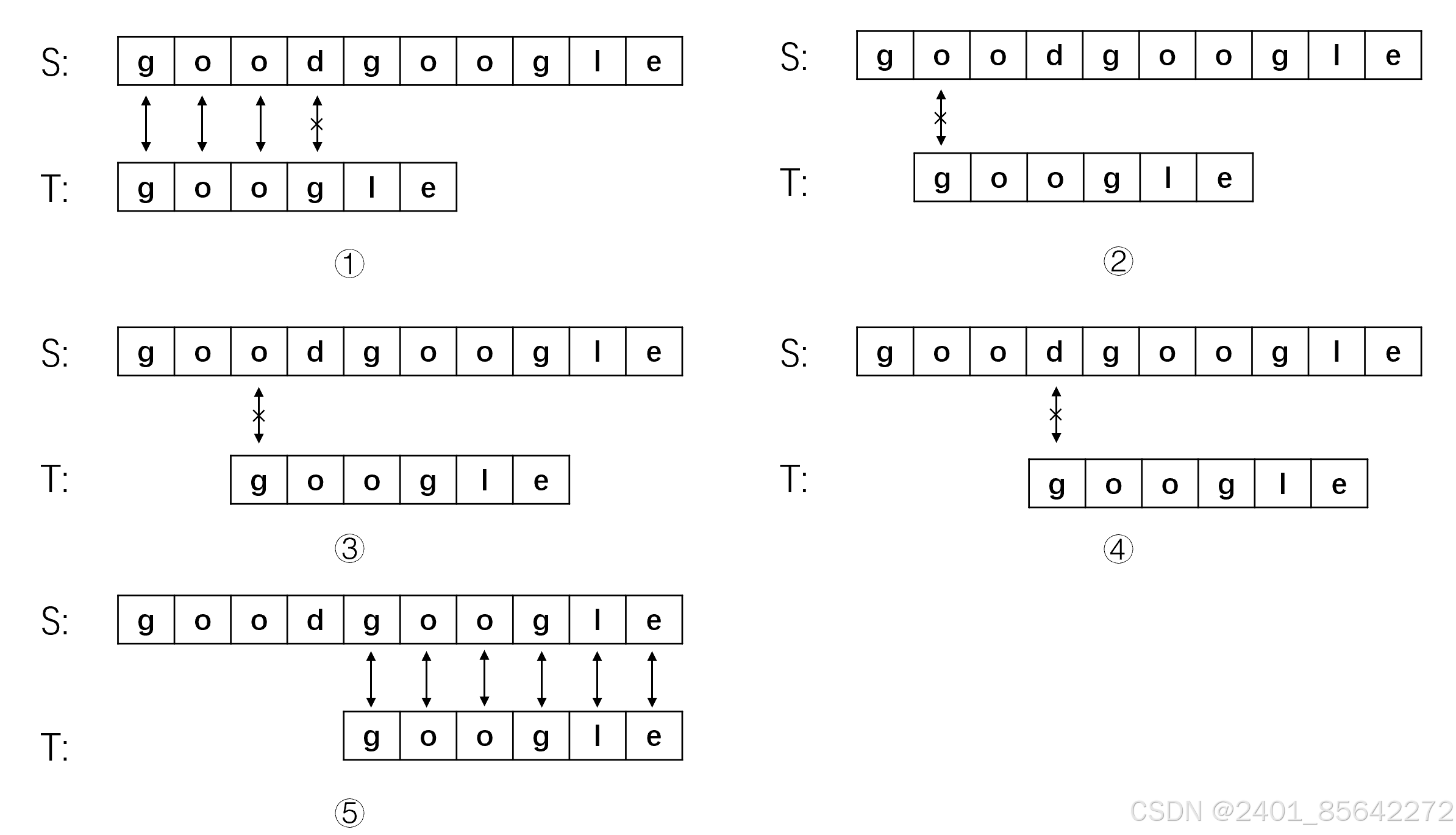
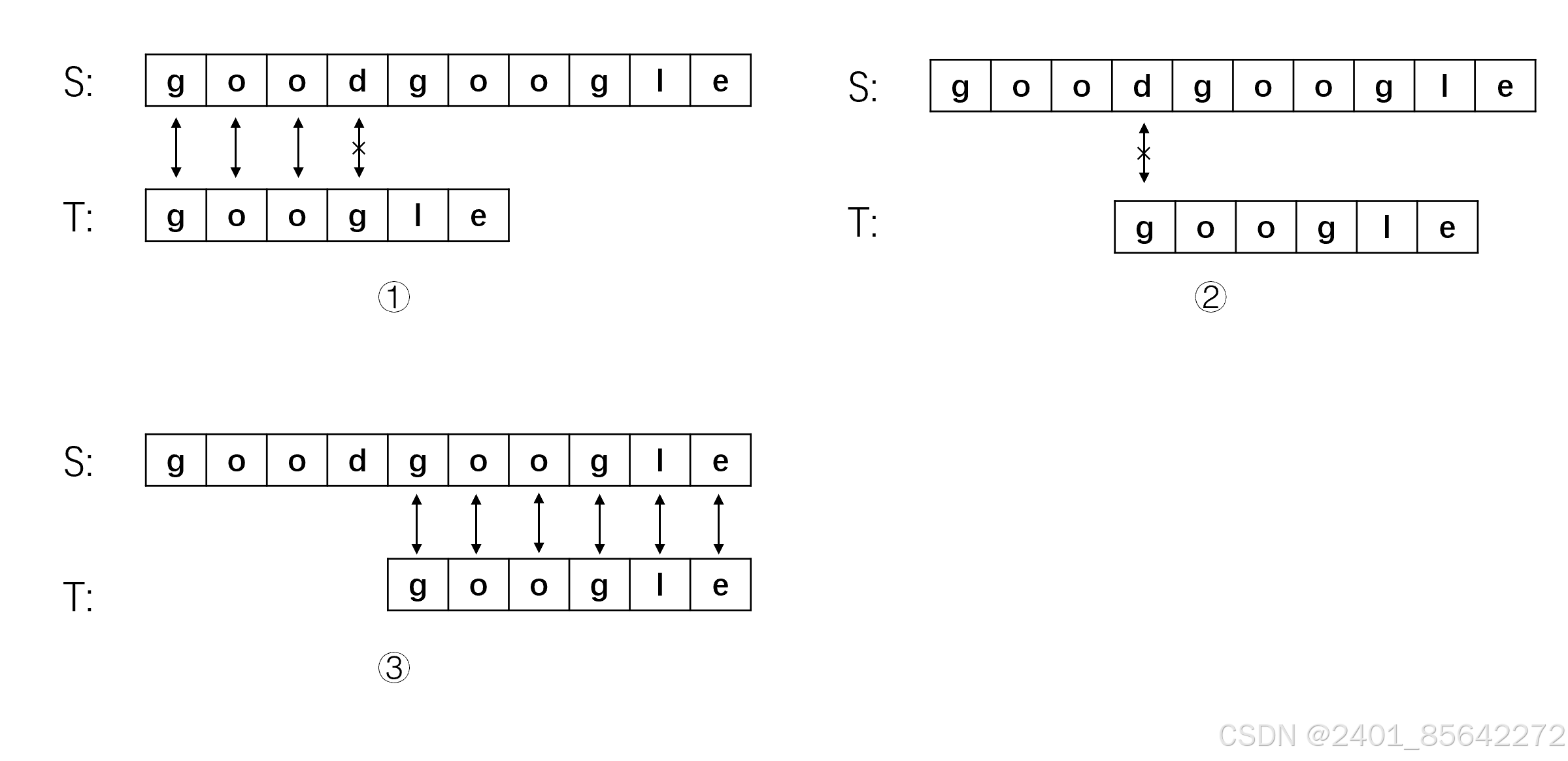
(1) 从主串S的第一位开始,S与T的前三位都匹配成功,第四位匹配失败,此时将主串的指针退回到第二位,子串的指针退回子串开始,即从S[1]开始重新匹配。
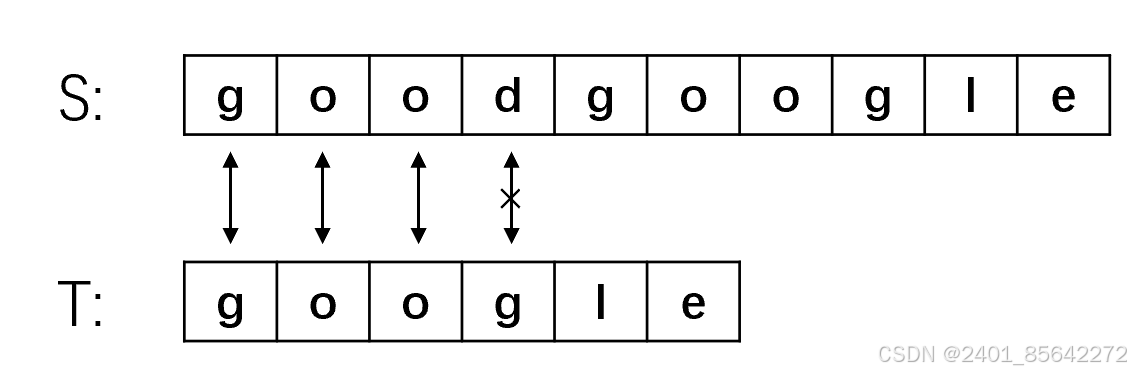
(2) 主串S从第二位开始于子串T匹配,第一步就匹配失败,将主串指针指向第三位S[2],子串指针指向开头,继续匹配。
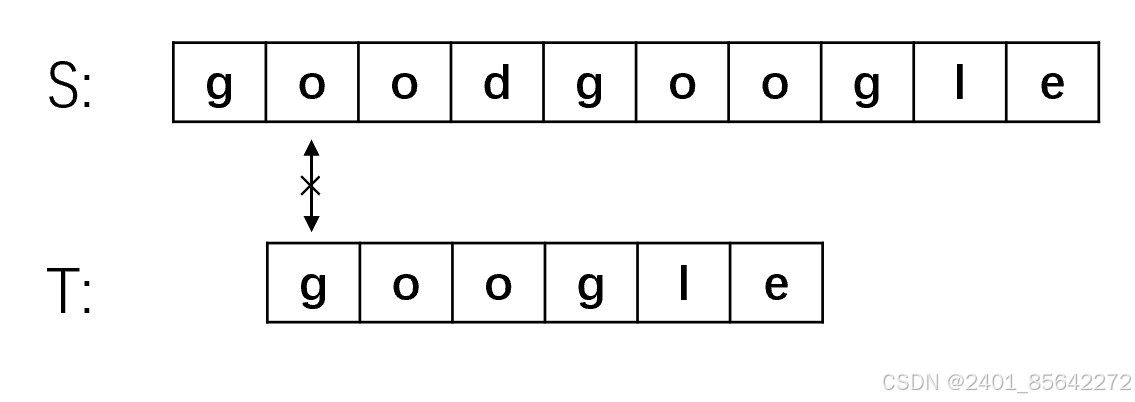
(3) 同步骤二,第一步就匹配失败,将主串指针移动到第四位S[3],子串指针指向开头,继续匹配。
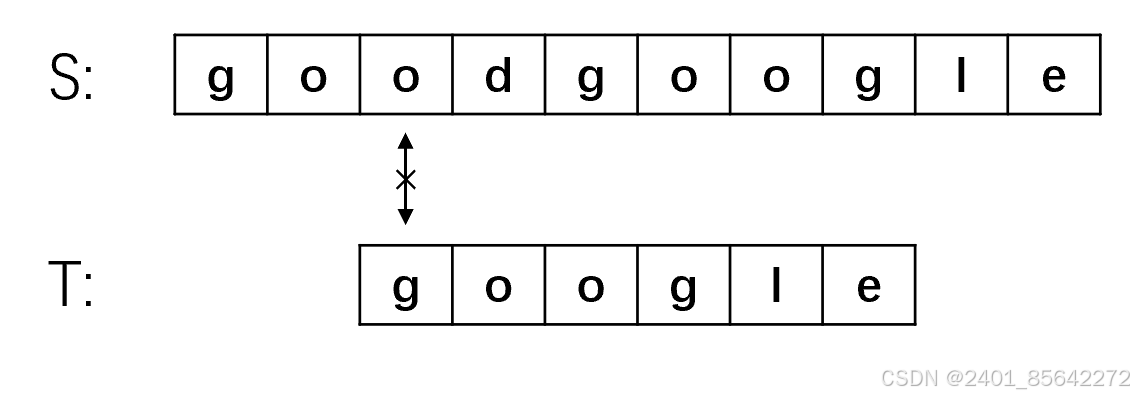
(4) 还是第一步就匹配失败,将主串指针移动到第五位S[4],子串指针指向开头,继续匹配。
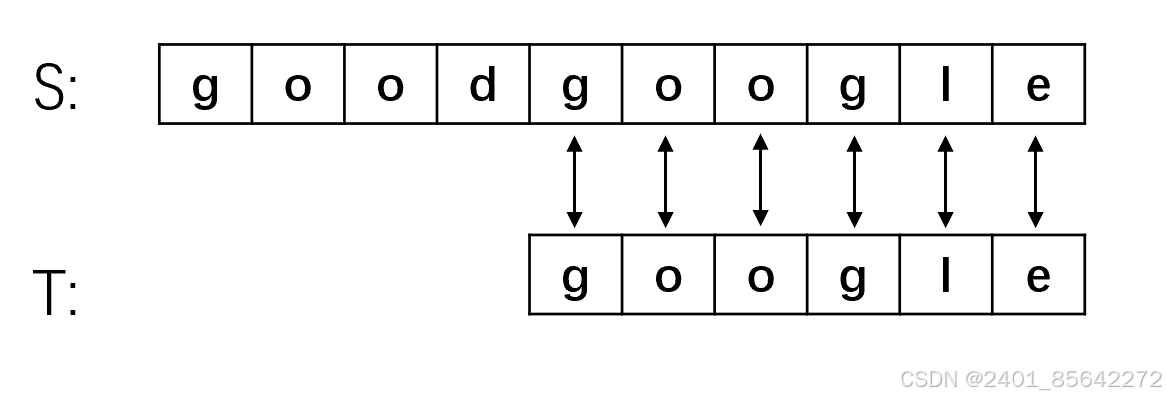
(5) 到步骤5终于第一步能够匹配上,从S[4]开始指针依次向后移动,六个字母全部匹配上,匹配成功!
int find_sub_string(string s, string t) { int i = 0, j = 0; //初始化两个指针 while(i<s.size() && j<t.size()){ if(s[i] == t[j]){ i++; //如果两个指针指向的字符相等 j++; //则将两个指针向后移动 } else{ i = i - j + 1; //匹配失败,i退回到上次匹配首位的下一位 j = 0; //j退回到子串首位 } } if(j>=t.size()){ //j走到子串末尾说明匹配成功 return i - j; //匹配成功返回主串中子串出现的第一位 } else return -1; //匹配失败,返回-1 }既然是朴素(暴力)解法,那必然存在时间复杂度的问题
最好的情况是一开始就匹配成功了,如主串为"googlegood",子串为"google",此时的时间复杂度为O(m)(m为子串长度)
最坏的情况就是每次不成功的匹配都发生在子串末尾,主串为S=“00000000000000000000000000000000000000000000000001”,子串为T=“0000000001”,推导一下可得此时的时间复杂度度为O((n-m+1)*m)(n为主串长度)。
而在计算机中对字符的存储采用的是ASCII码,字符串可以看成是许许多多个0和l组成,因此这种最坏的情况是很可能出现的,在计算机的运算当中,模式匹配操作可以说是随处可见。这样看来,这个如此频繁使用的算法,朴素做法显得太低效了。
KMP算法
为了避免朴素算法的低效,可以一定程度上避免重复遍历的问题,提出KMP算法。
从暴力匹配到KMP
要理解KMP算法的原理,我们首先需要批判一下朴素算法中有哪些做的不好的地方。
我们将之前的朴素算法的匹配过程合起来看如下面的图所示:
我们可以发现,在2、3、4步骤中,主串的首字符与子串的首字符均不等。我们仔细观察可以发现,对于子串"google"来说,首字母"g"与后面的两个字母是不相等的,而在步骤1中主串与子串的前三个字符相等,这就意味着子串的首字符"g"不可能与主串的二、三位相等,故上图中步骤2、3完全是多余的。
也就是说,如果我们知道子串的首字符"g"与后面两个字符不相等(此处需要进行一些预处理,这是后面的重点),我们就不需要再进行2、3步操作,只保留1、4、5步即可。
从上面这幅图我们可以惊喜地发现,在使用朴素算法进行匹配时,主串指针需要进行一些回退;而在知道了子串的一些性质后,主串指针不需要再进行回退,只需一直往前走就行,这样就节省了一些时间开销。
你或许还会有疑问,主串指针是不需要回退了,但为啥我的子串指针还要一直回退到开头呢,有没有办法避免这样呢?
当然是有的,我们再举一个例子,假设主串S=“abcababca”,子串T=“abcabx”,那我们采用朴素算法在进行模式匹配的步骤如下所示:
由之前一个例子的分析可知由于T串的首字母"a"与之后的字母"b"、"c"不等,故步骤2、3均是可以省略的。
又因为T的首位"a"与T第四位的"a"相等,第二位的"b"与第五位的"b"相等。而在步骤1中,第四位的"a"与第五位的"b"已经与主串s中的相应位置比较过了是相等的。因此可以断定, T的首字符“a”、第二位的字符“b”与S的第四位字符和第五位字符也不需要比较了,肯定也是相等的。所以步骤4、5这两个比较得出字符相等的步骤也可以省略。
所以在这个例子中我们模式匹配的流程为:
在这个例子中我们发现,在得知了子串中有相等的前后缀之后,匹配失败时子串指针不需要回退到开头处,而是回退到相等前缀的后一个位置。
前缀指的是不包含尾字符的所有子串;后缀指的是不包含首字符的所有子串
这两种方法的相同点为都是依靠两个指针的移动对比来实现字符串模式匹配,不同之处在于在改进做法中主串的指针i不需要进行回溯,子串的指针j会根据子串中的最长相等前后缀来进行回溯,这样就省去了一些不需要的回溯步骤,从而降低了时间复杂度。
KMP算法原理
在学习KMP算法的原理之前,我们需要先学习前缀表这个概念。顾名思义,前缀表是一张表(或者直接理解为一个数组),表中记录的是字符串中的每个子串的最大相等前后缀的长度,这个概念有点长也有点抽象,我们举一个例子来具体说明一下。
设字符串T=“aabaaf”,我们求一下T的前缀表(用一个数组名为next的数组表示)。
- 第一个子串是t0=“a”,易知该子串没有前缀也没有后缀,故next[0]=0
- 第二个子串是t1=“aa”,该子串的前缀为"a",后缀也为"a",故next[1]=1
- 第三个子串是t2=“aab”,该子串的后缀中一定会有"b",前缀中一定不含有"b",则其没有相等的前后缀,故next[2]=0
- 第四个子串是t3=“aaba”,该子串的最大相等前后缀为"a",长度为1,故next[3]=1
- 第五个子串是t4=“aabaa”,该子串的最大相等前后缀为"aa",长度为2,故next[4]=2
- 第六个子串是t5=“aabaaf”,该子串的后缀中一定会有"f",前缀中一定不含有"f",则其没有相等的前后缀,故next[5]=0
所以我们能得到字符串T的前缀表为:
j 0 1 2 3 4 5 T a a b a a f next 0 1 0 1 2 0 那既然我们得到了前缀表,前缀表在KMP算法中的作用是什么呢?其实前缀表决定了子串指针j在匹配失败时回溯到的位置。
结论:前缀表是用来回退的,它记录了模式串与主串(文本串)不匹配的时候,模式串应该从哪里开始重新匹配
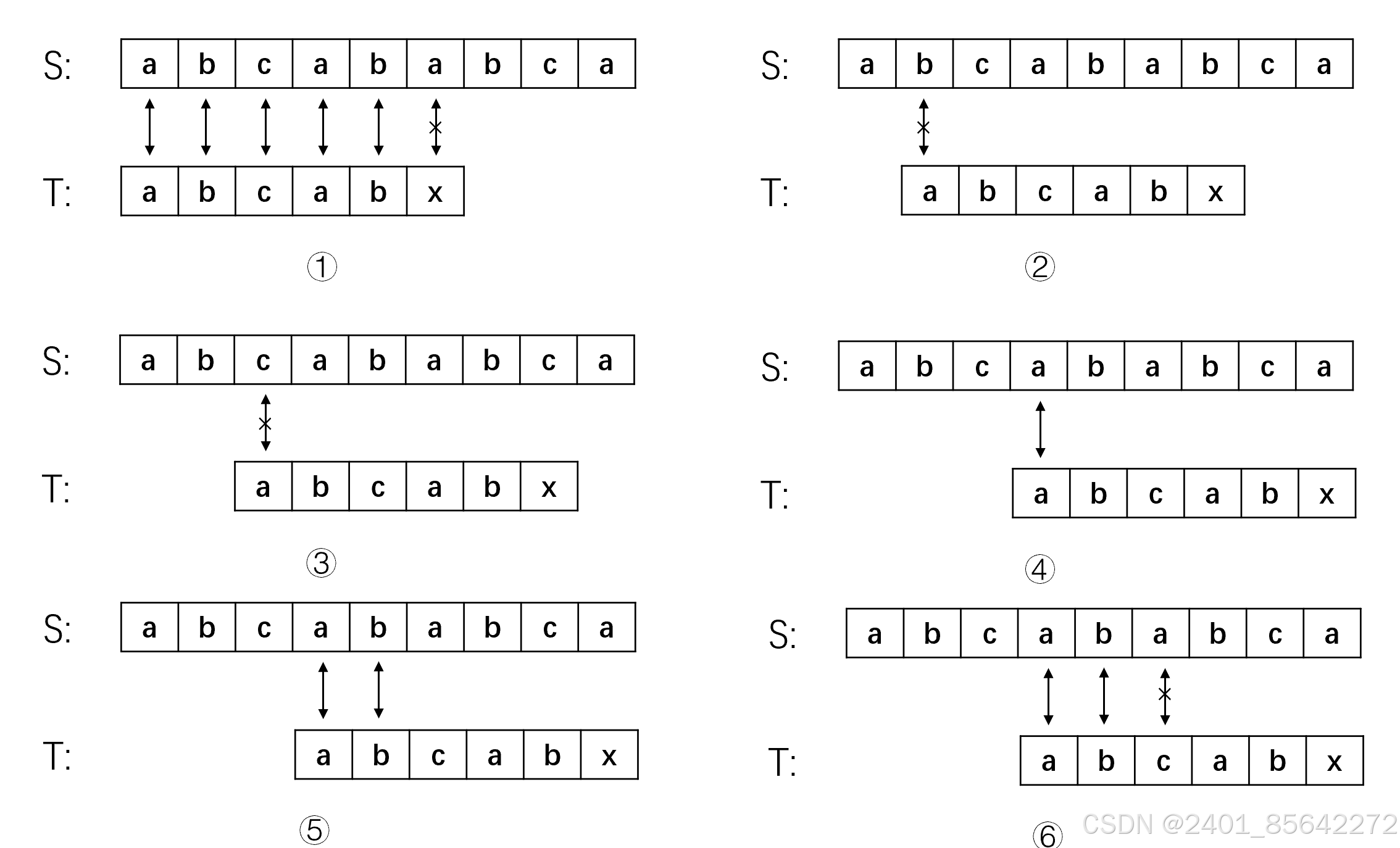
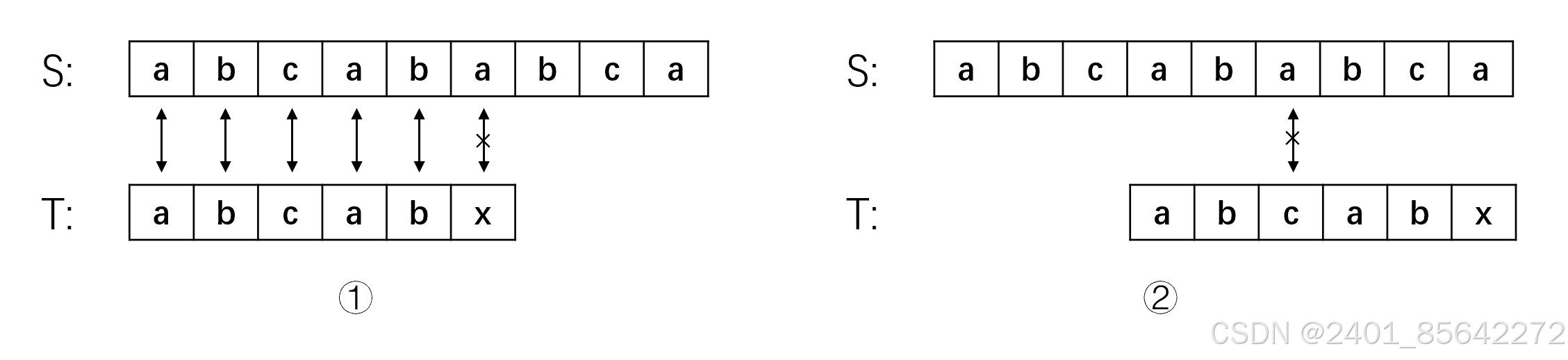
举个例子来说明这个结论,假设主串S=“aabaabaaf”,子串T=“aabaaf”,我们已经求出了子串T的前缀表,采用KMP算法匹配的流程如下:
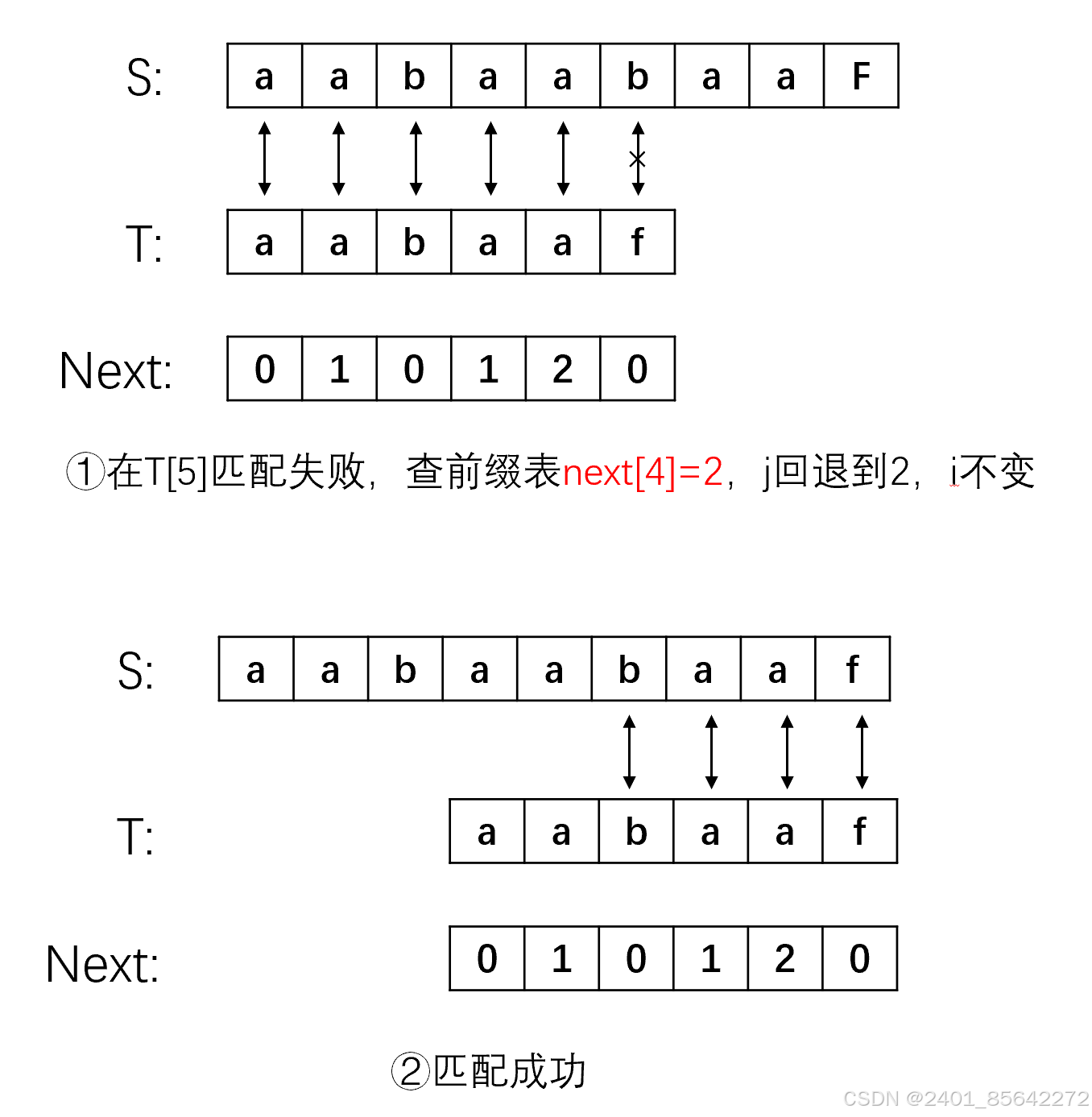
从上面的流程可以看到,在子串的某一个字符t[j]处匹配失败时,我们需要查找该字符前面的那个子串的最大相等前后缀的长度,即next[j-1],然后使j指针退回到next[j-1],i指针不变,继续匹配,不断重复这个操作知道匹配成功或者j指针大于等于子串长度。在这里j指针之所以退回到next[j-1]的位置我们可以根据例子思考一下,字符"f"前面的子串为"aabaa",该子串的最大相等前后缀为"aa",而该子串的后缀"aa"已经与s[3]s[4]比较过是相等的,那么子串的前缀就一定是与s[3]s[4]相等的,不需要比较,因此我们的j可以从前缀的后面第一个字符开始匹配,而前缀的长度为next[j-1],所以j应该回退到next[j-1]。
在理解了前缀表及其作用之后,KMP算法就可以整体上分为两步:
一、计算前缀表。
二、根据前缀表移动两个指针进行匹配。
下面我们给出KMP算法的代码实现如下:
void get_Next(string s, int next[]) //这个函数对字符串s进行预处理得到next数组
{
int j = 0;
next[0] = 0; //初始化
for(int i = 1; i<s.size(); i++){ //i指针指向的是后缀末尾,j指针指向的是前缀末尾
while(j>0&&s[i]!=s[j]) j = next[j-1]; //前后缀不相同,去找j前一位的最长相等前后缀
if(s[i]==s[j]) j++; //前后缀相同,j指针后移
next[i] = j; //更新next数组
}
}
上面是计算模式串的前缀表next的代码,其流程见注释。
得到了next数组后,我们进入匹配查找的阶段。
int strSTR(string s, string t) //这个函数是从s中找到t,如果存在返回t出现的位置,如果不存在返回-1
{
if(t.size()==0) return 0;
get_Next(t, next);
int j = 0;
for(int i = 0; i < s.size(); i++){
while(j>0&&s[i]!= t[j]) j = next[j-1];
if(s[i]==t[j]) j++;
if(j==t.size()) return i - t.size() + 1;
}
return -1;
}

小结:
KMP算法主要应用于字符串模式匹配,其核心思想在于使用前缀表从而实现在不匹配时利用之前已经匹配过的信息来减少回溯的过程。理解KMP算法的关键在于理解前缀表的生成


















 3589
3589

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









