




🔗 GitHub 持续更新仓库(含代码+课件):
👉 github.com/CalebCheng819/cs285
lecture9
part1
Policy gradient as softened policy iteration
我们可以换一种角度理解策略梯度:将其看作一种“软化版(softened)”的策略迭代(Policy Iteration)。
经典策略迭代结构(policy iteration):
- Alternating between:
- 估计当前策略的值函数 VπV^\piVπ 或 Advantage;
- 使用估计值更新策略(例如贪心选择最优动作)。
类比:
| 步骤 | 策略迭代 | 策略梯度 |
|---|---|---|
| 值估计 | 准确估计 Aπ(s,a)A^\pi(s, a)Aπ(s,a) | 使用样本/网络近似 Advantage |
| 策略更新 | argmax (完全采纳最优动作) | 轻微调整策略参数(通过梯度) |
策略梯度不会像策略迭代那样直接跳转到贪心策略,而是根据 Advantage 的大小轻微提高动作概率。
这在 Advantage 估计不准时很有用 —— 小步更新可以避免因估计误差而“走错方向”。
理论证明
要证明的结论(最终目标)是:
J(θ′)−J(θ)=Eπθ′[∑t=0∞γtAπθ(st,at)]
J(\theta') - J(\theta) = \mathbb{E}_{\pi_{\theta'}} \left[ \sum_{t=0}^{\infty} \gamma^t A^{\pi_\theta}(s_t, a_t) \right]
J(θ′)−J(θ)=Eπθ′[t=0∑∞γtAπθ(st,at)]
这一步的目的就是将策略改进的目标函数差值(LHS)转换为新策略分布下旧策略 Advantage 的期望(RHS)。
我们从标准的强化学习目标函数出发:
J(θ)=Eτ∼πθ[∑t=0∞γtr(st,at)]
J(\theta) = \mathbb{E}_{\tau \sim \pi_\theta} \left[ \sum_{t=0}^{\infty} \gamma^t r(s_t, a_t) \right]
J(θ)=Eτ∼πθ[t=0∑∞γtr(st,at)]
我们可以将其改写为:
J(θ)=Es0∼p(s0)[Vπθ(s0)]
J(\theta) = \mathbb{E}_{s_0 \sim p(s_0)} \left[ V^{\pi_\theta}(s_0) \right]
J(θ)=Es0∼p(s0)[Vπθ(s0)]
这是因为 Value Function 就是从某状态出发的期望累计奖励。
- 将 V(s₀) 用 telescoping sum 重写成:
Vπθ(s0)=∑t=0∞γtVπθ(st)−∑t=1∞γtVπθ(st) V^{\pi_\theta}(s_0) = \sum_{t=0}^{\infty} \gamma^t V^{\pi_\theta}(s_t) - \sum_{t=1}^{\infty} \gamma^t V^{\pi_\theta}(s_t) Vπθ(s0)=t=0∑∞γtVπθ(st)−t=1∑∞γtVπθ(st)
使用下面两个式子:
J(θ′)=Eπθ′[∑t=0∞γtr(st,at)]
J(\theta') = \mathbb{E}_{\pi_{\theta'}} \left[ \sum_{t=0}^{\infty} \gamma^t r(s_t, a_t) \right]
J(θ′)=Eπθ′[t=0∑∞γtr(st,at)]
注意:这两个期望都使用 π′ 的轨迹分布,这是合法的,因为初始状态分布不依赖 θ。
从 lecture 原文中我们看到他写了一个式子:
J(θ′)−J(θ)=Eπθ′[∑t=0∞γtr(st,at)+∑t=1∞γtVπθ(st)−∑t=0∞γtVπθ(st)]
J(\theta') - J(\theta) = \mathbb{E}_{\pi_{\theta'}} \left[ \sum_{t=0}^{\infty} \gamma^t r(s_t, a_t) + \sum_{t=1}^{\infty} \gamma^t V^{\pi_\theta}(s_t) - \sum_{t=0}^{\infty} \gamma^t V^{\pi_\theta}(s_t) \right]
J(θ′)−J(θ)=Eπθ′[t=0∑∞γtr(st,at)+t=1∑∞γtVπθ(st)−t=0∑∞γtVπθ(st)]
合并后:
=Eπθ′[∑t=0∞γt(r(st,at)+γVπθ(st+1)−Vπθ(st))]
= \mathbb{E}_{\pi_{\theta'}} \left[ \sum_{t=0}^{\infty} \gamma^t \left( r(s_t, a_t) + \gamma V^{\pi_\theta}(s_{t+1}) - V^{\pi_\theta}(s_t) \right) \right]
=Eπθ′[t=0∑∞γt(r(st,at)+γVπθ(st+1)−Vπθ(st))]
这个括号里的表达式,正是 Advantage Function 的定义:
Aπθ(st,at)=r(st,at)+γVπθ(st+1)−Vπθ(st)
A^{\pi_\theta}(s_t, a_t) = r(s_t, a_t) + \gamma V^{\pi_\theta}(s_{t+1}) - V^{\pi_\theta}(s_t)
Aπθ(st,at)=r(st,at)+γVπθ(st+1)−Vπθ(st)
所以最终就得到了:
J(θ′)−J(θ)=Eπθ′[∑t=0∞γtAπθ(st,at)]
J(\theta') - J(\theta) = \mathbb{E}_{\pi_{\theta'}} \left[ \sum_{t=0}^{\infty} \gamma^t A^{\pi_\theta}(s_t, a_t) \right]
J(θ′)−J(θ)=Eπθ′[t=0∑∞γtAπθ(st,at)]
我们希望:
- 用旧策略 π_θ 的数据采样(因为我们还没知道 π_θ’);
- 那么需要引入 importance sampling 修正权重;
Eτ∼pθ′(τ)[∑tγtAπθ(st,at)]=∑tEst∼pθ′(st)[Eat∼πθ′(at∣st)[γtAπθ(st,at)]]=∑tEst∼pθ′(st)[Eat∼πθ(at∣st)[πθ′(at∣st)πθ(at∣st)γtAπθ(st,at)]] \begin{aligned} E_{\tau \sim p_{\theta^{\prime}}(\tau)}\left[\sum_t \gamma^t A^{\pi_\theta}\left(\mathbf{s}_t, \mathbf{a}_t\right)\right] & =\sum_t E_{\mathbf{s}_t \sim p_{\theta^{\prime}}\left(\mathbf{s}_t\right)}\left[E_{\mathbf{a}_t \sim \pi_{\theta^{\prime}}\left(\mathbf{a}_t \mid \mathbf{s}_t\right)}\left[\gamma^t A^{\pi_\theta}\left(\mathbf{s}_t, \mathbf{a}_t\right)\right]\right] \\ & =\sum_t E_{\mathbf{s}_t \sim p_{\theta^{\prime}}\left(\mathbf{s}_t\right)}\left[E_{\mathbf{a}_t \sim \pi_\theta\left(\mathbf{a}_t \mid \mathbf{s}_t\right)}\left[\frac{\pi_{\theta^{\prime}}\left(\mathbf{a}_t \mid \mathbf{s}_t\right)}{\pi_\theta\left(\mathbf{a}_t \mid \mathbf{s}_t\right)} \gamma^t A^{\pi_\theta}\left(\mathbf{s}_t, \mathbf{a}_t\right)\right]\right] \end{aligned} Eτ∼pθ′(τ)[t∑γtAπθ(st,at)]=t∑Est∼pθ′(st)[Eat∼πθ′(at∣st)[γtAπθ(st,at)]]=t∑Est∼pθ′(st)[Eat∼πθ(at∣st)[πθ(at∣st)πθ′(at∣st)γtAπθ(st,at)]]
我们无法直接从 π_θ’ 采样
- 所以我们希望能近似地用 π_θ 的分布来替代;
- 如果 π_θ 和 π_θ’ 很接近,那么状态分布 d^{π_θ}(s) 和 d^{π_θ’}(s) 也近似;
- 这是 策略迭代的近似前提:改进不能跳太远。
∑tEst∼pθ′(st)[Eat∼πθ(at∣st)[πθ′(at∣st)πθ(at∣st)γtAπθ(st,at)]]≈∑tEst∼pθ(st)[Eat∼πθ(at∣st)[πθ′(at∣st)πθ(at∣st)γtAπθ(st,at)]] \sum_t E_{\mathbf{s}_t \sim p_{\theta^{\prime}}\left(\mathbf{s}_t\right)}\left[E_{\mathbf{a}_t \sim \pi_\theta\left(\mathbf{a}_t \mid \mathbf{s}_t\right)}\left[\frac{\pi_{\theta^{\prime}}\left(\mathbf{a}_t \mid \mathbf{s}_t\right)}{\pi_\theta\left(\mathbf{a}_t \mid \mathbf{s}_t\right)} \gamma^t A^{\pi_\theta}\left(\mathbf{s}_t, \mathbf{a}_t\right)\right]\right] \approx \sum_t E_{\mathbf{s}_t \sim p_\theta\left(\mathbf{s}_t\right)}\left[E_{\mathbf{a}_t \sim \pi_\theta\left(\mathbf{a}_t \mid \mathbf{s}_t\right)}\left[\frac{\pi_{\theta^{\prime}}\left(\mathbf{a}_t \mid \mathbf{s}_t\right)}{\pi_\theta\left(\mathbf{a}_t \mid \mathbf{s}_t\right)} \gamma^t A^{\pi_\theta}\left(\mathbf{s}_t, \mathbf{a}_t\right)\right]\right] t∑Est∼pθ′(st)[Eat∼πθ(at∣st)[πθ(at∣st)πθ′(at∣st)γtAπθ(st,at)]]≈t∑Est∼pθ(st)[Eat∼πθ(at∣st)[πθ(at∣st)πθ′(at∣st)γtAπθ(st,at)]]
part2
证明pθ(st)p_\theta\left(\mathbf{s}_t\right)pθ(st) is close to pθ′(st)p_{\theta^{\prime}}\left(\mathbf{s}_t\right)pθ′(st) when πθ\pi_\thetaπθ is close to πθ′\pi_{\theta^{\prime}}πθ′
假设旧策略 π_θ 是确定性的,即:
at=πθ(st)
a_t = \pi_\theta(s_t)
at=πθ(st)
若新策略 π_θ′ 在任意状态下以概率 ε 偏离旧策略(即选择不同的动作),则:
-
“没出错”的概率为 (1−ϵ)t(1 - \epsilon)^t(1−ϵ)t
这种情况下状态分布与旧策略完全一致:pθ′(st)=pθ(st)p_{\theta'}(s_t) = p_\theta(s_t)pθ′(st)=pθ(st)
-
剩下的情况则定义为错误分布 pmistake(st)p_{\text{mistake}}(s_t)pmistake(st),我们对它不做任何假设。
于是有如下表示:
pθ′(st)=(1−ϵ)tpθ(st)+[1−(1−ϵ)t]pmistake(st)
p_{\theta'}(s_t) = (1 - \epsilon)^t p_\theta(s_t) + \left[1 - (1 - \epsilon)^t\right] p_{\text{mistake}}(s_t)
pθ′(st)=(1−ϵ)tpθ(st)+[1−(1−ϵ)t]pmistake(st)
该表达式与我们在模仿学习(Behavior Cloning)分析中非常相似。
∣pθ′(st)−pθ(st)∣=(1−(1−ϵ)t)∣pmistake (st)−pθ(st)∣≤2(1−(1−ϵ)t)≤2ϵt useful identity: (1−ϵ)t≥1−ϵt for ϵ∈[0,1]
\begin{aligned}
& \left|p_{\theta^{\prime}}\left(\mathbf{s}_t\right)-p_\theta\left(\mathbf{s}_t\right)\right|=\left(1-(1-\epsilon)^t\right)\left|p_{\text {mistake }}\left(\mathbf{s}_t\right)-p_\theta\left(\mathbf{s}_t\right)\right| \leq 2\left(1-(1-\epsilon)^t\right)\quad \leq 2 \epsilon t \\
& \text { useful identity: }(1-\epsilon)^t \geq 1-\epsilon t \text { for } \epsilon \in[0,1]
\end{aligned}
∣pθ′(st)−pθ(st)∣=(1−(1−ϵ)t)∣pmistake (st)−pθ(st)∣≤2(1−(1−ϵ)t)≤2ϵt useful identity: (1−ϵ)t≥1−ϵt for ϵ∈[0,1]
这意味着:只要 ε 足够小,策略间的微小差异导致的状态分布偏移也会非常小。
接下来分析更加general的情况
引入引理(来自 Trust Region Policy Optimization 论文):
如果两个分布 π 和 π′ 的 total variation divergence 是 ε,那么存在一个联合分布 p(x,y)p(x, y)p(x,y),使得:
- p(x)=π(x),p(y)=π′(y)p(x) = \pi(x),\quad p(y) = \pi'(y)p(x)=π(x),p(y)=π′(y)
- P(x=y)=1−ϵP(x = y) = 1 - \epsilonP(x=y)=1−ϵ
πθ′\pi_{\theta^{\prime}}πθ′ is close to πθ\pi_\thetaπθ if ∣πθ′(at∣st)−πθ(at∣st)∣≤ϵ\left|\pi_{\theta^{\prime}}\left(\mathbf{a}_t \mid \mathbf{s}_t\right)-\pi_\theta\left(\mathbf{a}_t \mid \mathbf{s}_t\right)\right| \leq \epsilon∣πθ′(at∣st)−πθ(at∣st)∣≤ϵ for all st\mathbf{s}_tst
Useful lemma: if ∣pX(x)−pY(x)∣=ϵ\left|p_X(x)-p_Y(x)\right|=\epsilon∣pX(x)−pY(x)∣=ϵ, exists p(x,y)p(x, y)p(x,y) such that p(x)=pX(x)p(x)=p_X(x)p(x)=pX(x) and p(y)=pY(y)p(y)=p_Y(y)p(y)=pY(y) and p(x=y)=1−ϵp(x=y)=1-\epsilonp(x=y)=1−ϵ ⇒pX(x)\Rightarrow p_X(x)⇒pX(x) “agrees” with pY(y)p_Y(y)pY(y) with probability ϵ\epsilonϵ
⇒πθ′(at∣st)\Rightarrow \pi_{\theta^{\prime}}\left(\mathbf{a}_t \mid \mathbf{s}_t\right)⇒πθ′(at∣st) takes a different action than πθ(at∣st)\pi_\theta\left(\mathbf{a}_t \mid \mathbf{s}_t\right)πθ(at∣st) with probability at most ϵ\epsilonϵ
所以,我们仍然可以使用之前的分布表示:
pθ′(st)=(1−ϵ)tpθ(st)+[1−(1−ϵ)t]pmistake(st)
p_{\theta'}(s_t) = (1 - \epsilon)^t p_\theta(s_t) + \left[1 - (1 - \epsilon)^t \right] p_{\text{mistake}}(s_t)
pθ′(st)=(1−ϵ)tpθ(st)+[1−(1−ϵ)t]pmistake(st)
并同样推导出:
TV(pθ,pθ′)≤2ϵt
\text{TV}(p_\theta, p_{\theta'}) \leq 2 \epsilon t
TV(pθ,pθ′)≤2ϵt
bounding the object value
我们关心的是:
Epθ′[f(st)]−Epθ[f(st)]
\mathbb{E}_{p_{\theta'}}\left[ f(s_t) \right] - \mathbb{E}_{p_\theta}\left[ f(s_t) \right]
Epθ′[f(st)]−Epθ[f(st)]
可以用以下界限表示:
∣Epθ′[f(s)]−Epθ[f(s)]∣≤TV(pθ′,pθ)⋅maxs∣f(s)∣
\left| \mathbb{E}_{p_{\theta'}}[f(s)] - \mathbb{E}_{p_\theta}[f(s)] \right| \leq \text{TV}(p_{\theta'}, p_\theta) \cdot \max_s |f(s)|
Epθ′[f(s)]−Epθ[f(s)]≤TV(pθ′,pθ)⋅smax∣f(s)∣
这是一个泛用技巧,任何两个分布下的期望值差异,都可由最大函数值与全变差距离界定。
于是我们得到:
Error Term≤2⋅ϵ⋅t⋅C
\text{Error Term} \leq 2 \cdot \epsilon \cdot t \cdot C
Error Term≤2⋅ϵ⋅t⋅C
即
∑tEst∼pθ′(st)[Eat∼πθ(at∣st)[πθ′(at∣st)πθ(at∣st)γtAπθ(st,at)]]≥∑tEst∼pθ(st)[Eat∼πθ(at∣st)[πθ′(at∣st)πθ(at∣st)γtAπθ(st,at)]]−∑t2ϵtC
\begin{aligned}
& \sum_t E_{\mathbf{s}_t \sim p_{\theta^{\prime}}\left(\mathbf{s}_t\right)}\left[E_{\mathbf{a}_t \sim \pi_\theta\left(\mathbf{a}_t \mid \mathbf{s}_t\right)}\left[\frac{\pi_{\theta^{\prime}}\left(\mathbf{a}_t \mid \mathbf{s}_t\right)}{\pi_\theta\left(\mathbf{a}_t \mid \mathbf{s}_t\right)} \gamma^t A^{\pi_\theta}\left(\mathbf{s}_t, \mathbf{a}_t\right)\right]\right] \geq \\
& \sum_t E_{\mathbf{s}_t \sim p_\theta\left(\mathbf{s}_t\right)}\left[E_{\mathbf{a}_t \sim \pi_\theta\left(\mathbf{a}_t \mid \mathbf{s}_t\right)}\left[\frac{\pi_{\theta^{\prime}}\left(\mathbf{a}_t \mid \mathbf{s}_t\right)}{\pi_\theta\left(\mathbf{a}_t \mid \mathbf{s}_t\right)} \gamma^t A^{\pi_\theta}\left(\mathbf{s}_t, \mathbf{a}_t\right)\right]\right]-\sum_t 2 \epsilon t C
\end{aligned}
t∑Est∼pθ′(st)[Eat∼πθ(at∣st)[πθ(at∣st)πθ′(at∣st)γtAπθ(st,at)]]≥t∑Est∼pθ(st)[Eat∼πθ(at∣st)[πθ(at∣st)πθ′(at∣st)γtAπθ(st,at)]]−t∑2ϵtC
其中 C=T⋅RmaxC = T \cdot R_{\max}C=T⋅Rmax(或 Rmax1−γ\frac{R_{\max}}{1 - \gamma}1−γRmax 若为无限时序)
part3
我们希望:
pθ(st)≈pθ′(st)当πθ≈πθ′
p_\theta(s_t) \approx p_{\theta'}(s_t) \quad \text{当} \quad \pi_\theta \approx \pi_{\theta'}
pθ(st)≈pθ′(st)当πθ≈πθ′
其中“接近”原先是用 Total Variation Distance (TV distance) 来衡量的。
实践问题:TV Divergence 不易处理
困难点:
- TV 距离涉及绝对值,不易求导;
- 很多连续动作策略无法轻易计算 TV。
解决方案:改用 KL Divergence (相对熵)
∣πθ′(at∣st)−πθ(at∣st)∣≤12DKL(πθ′(at∣st)∥πθ(at∣st))⇒DKL(πθ′(at∣st)∥πθ(at∣st)) bounds state marginal difference DKL(p1(x)∥p2(x))=Ex∼p1(x)[logp1(x)p2(x)]
\begin{aligned}
& \left|\pi_{\theta^{\prime}}\left(\mathbf{a}_t \mid \mathbf{s}_t\right)-\pi_\theta\left(\mathbf{a}_t \mid \mathbf{s}_t\right)\right| \leq \sqrt{\frac{1}{2} D_{\mathrm{KL}}\left(\pi_{\theta^{\prime}}\left(\mathbf{a}_t \mid \mathbf{s}_t\right) \| \pi_\theta\left(\mathbf{a}_t \mid \mathbf{s}_t\right)\right)} \\
& \quad \Rightarrow D_{\mathrm{KL}}\left(\pi_{\theta^{\prime}}\left(\mathbf{a}_t \mid \mathbf{s}_t\right) \| \pi_\theta\left(\mathbf{a}_t \mid \mathbf{s}_t\right)\right) \text { bounds state marginal difference } \\
& \quad D_{\mathrm{KL}}\left(p_1(x) \| p_2(x)\right)=E_{x \sim p_1(x)}\left[\log \frac{p_1(x)}{p_2(x)}\right]
\end{aligned}
∣πθ′(at∣st)−πθ(at∣st)∣≤21DKL(πθ′(at∣st)∥πθ(at∣st))⇒DKL(πθ′(at∣st)∥πθ(at∣st)) bounds state marginal difference DKL(p1(x)∥p2(x))=Ex∼p1(x)[logp2(x)p1(x)]
实现方式一:拉格朗日乘子法(Lagrangian)
我们将约束问题变为无约束优化:
L(θ′,λ)=∑tEst∼pθ(st)[Eat∼πθ(at∣st)[πθ′(at∣st)πθ(at∣st)γtAπθ(st,at)]]−λ(DKL(πθ′(at∣st)∥πθ(at∣st))−ϵ)
\mathcal{L}\left(\theta^{\prime}, \lambda\right)=\sum_t E_{\mathbf{s}_t \sim p_\theta\left(\mathbf{s}_t\right)}\left[E_{\mathbf{a}_t \sim \pi_\theta\left(\mathbf{a}_t \mid \mathbf{s}_t\right)}\left[\frac{\pi_{\theta^{\prime}}\left(\mathbf{a}_t \mid \mathbf{s}_t\right)}{\pi_\theta\left(\mathbf{a}_t \mid \mathbf{s}_t\right)} \gamma^t A^{\pi_\theta}\left(\mathbf{s}_t, \mathbf{a}_t\right)\right]\right]-\lambda\left(D_{\mathrm{KL}}\left(\pi_{\theta^{\prime}}\left(\mathbf{a}_t \mid \mathbf{s}_t\right) \| \pi_\theta\left(\mathbf{a}_t \mid \mathbf{s}_t\right)\right)-\epsilon\right)
L(θ′,λ)=t∑Est∼pθ(st)[Eat∼πθ(at∣st)[πθ(at∣st)πθ′(at∣st)γtAπθ(st,at)]]−λ(DKL(πθ′(at∣st)∥πθ(at∣st))−ϵ)
- 当 KL > ε,λ ↑ 来加强惩罚;
- 当 KL < ε,λ ↓ 放松惩罚。
算法步骤:Dual Gradient Descent
- 固定 λ,优化 θ′(梯度上升);
- 固定 θ′,更新 λ(梯度下降):
λ←λ+η(KL−ϵ) \lambda \leftarrow \lambda + \eta (\text{KL} - \epsilon) λ←λ+η(KL−ϵ)
这种方式能收敛到满足约束的最优策略参数 θ′
实现方式二:正则化处理(Regularization)
一种更简单但经验有效的做法:
maxθ′Es,a[A^(s,a)]−λ⋅KL(πθ′∣∣πθ)
\max_{\theta'} \mathbb{E}_{s, a} [\hat{A}(s, a)] - \lambda \cdot \text{KL}(\pi_{\theta'} || \pi_\theta)
θ′maxEs,a[A^(s,a)]−λ⋅KL(πθ′∣∣πθ)
- 不设置严格约束;
- 将 KL 作为一个 soft penalty;
- λ 可以人为设定(调参)或动态调整。
在 PPO(Proximal Policy Optimization)和 Guided Policy Search 中就采用了这种方式。
part4——Natural Policy Gradient(自然策略梯度)
目标:
maxθ′Es∼pθ(s)[∑aπθ′(a∣s)Aπθ(s,a)]s.t.KL(πθ′∣∣πθ)≤ϵ
\max_{\theta'} \quad \mathbb{E}_{s \sim p_\theta(s)} \left[ \sum_a \pi_{\theta'}(a|s) A^{\pi_\theta}(s,a) \right]
\quad \text{s.t.} \quad \text{KL}(\pi_{\theta'} || \pi_\theta) \leq \epsilon
θ′maxEs∼pθ(s)[a∑πθ′(a∣s)Aπθ(s,a)]s.t.KL(πθ′∣∣πθ)≤ϵ
上一节中,我们通过拉格朗日方法或正则项实现了此约束。

使用一阶泰勒展开(First-Order Taylor Expansion)
我们将目标函数 J(θ′)J(\theta')J(θ′) 在 θ 附近做线性化(taylor approximation):
J(θ′)≈J(θ)+∇θJ(θ)T(θ′−θ)
J(\theta') \approx J(\theta) + \nabla_\theta J(\theta)^T (\theta' - \theta)
J(θ′)≈J(θ)+∇θJ(θ)T(θ′−θ)
即:我们只保留线性项,优化这个线性函数。
这时必须引入“信赖域”约束,避免优化发散(如往无穷大方向走)。
图示直觉(Trust Region)
- 蓝色曲线:真实目标函数
- 绿色线:一阶泰勒近似
- 红框区域:我们信赖的一小块“近似还算准确”的空间(trust region)
我们在红框中优化绿色线(近似函数),来替代优化真实目标。
回想到一般的梯度上升做法类似于此,相当于解下面的约束优化问题:
θ′←argmaxθ′∇θJ(θ)T(θ′−θ)s.t.∥θ′−θ∥2≤ϵ
\theta' \leftarrow \arg\max_{\theta'} \nabla_\theta J(\theta)^T (\theta' - \theta)
\quad \text{s.t.} \quad \|\theta' - \theta\|^2 \leq \epsilon
θ′←argθ′max∇θJ(θ)T(θ′−θ)s.t.∥θ′−θ∥2≤ϵ
这是在参数空间中以欧几里得距离为约束的最优化 —— 实质就是:
普通梯度上升是在「参数空间」的圆形信赖域里找最优点。
有封闭解(公式给出):
θ′=θ+ϵ∥∇θJ(θ)∥2∇θJ(θ)
\theta' = \theta + \sqrt{\frac{\epsilon}{\|\nabla_\theta J(\theta)\|^2}} \nabla_\theta J(\theta)
θ′=θ+∥∇θJ(θ)∥2ϵ∇θJ(θ)
- 方向是梯度方向;
- 步长大小由 epsilon 和梯度范数共同决定。
问题在于:这个圆在参数空间中是对称的,但我们真正关心的是策略分布(而不是参数本身)有没有大改动,所以这个圆有可能约束错了方向。
于是我们对 KL divergence 做二阶近似:
KL(πθ′∣∣πθ)≈12(θ′−θ)TF(θ′−θ)
\text{KL}(\pi_{\theta'} || \pi_\theta) \approx \frac{1}{2} (\theta' - \theta)^T F (\theta' - \theta)
KL(πθ′∣∣πθ)≈21(θ′−θ)TF(θ′−θ)
其中 F 是 Fisher Information Matrix(Fisher 信息矩阵):
F=Es∼pθ,a∼πθ[∇θlogπθ(a∣s)∇θlogπθ(a∣s)T]
F = \mathbb{E}_{s \sim p_\theta, a \sim \pi_\theta} \left[ \nabla_\theta \log \pi_\theta(a|s) \nabla_\theta \log \pi_\theta(a|s)^T \right]
F=Es∼pθ,a∼πθ[∇θlogπθ(a∣s)∇θlogπθ(a∣s)T]
它描述了:改变 θ 时,对动作分布 π(a|s) 有多大影响。
求解这个二次约束的线性优化问题,结果为:
θ′=θ+αF−1∇θJ(θ)
\theta' = \theta + \alpha F^{-1} \nabla_\theta J(\theta)
θ′=θ+αF−1∇θJ(θ)
α=2ϵ∇θJ(θ)TF∇θJ(θ) \alpha=\sqrt{\frac{2 \epsilon}{\nabla_\theta J(\theta)^T \mathbf{F} \nabla_\theta J(\theta)}} α=∇θJ(θ)TF∇θJ(θ)2ϵ
这就是 Natural Policy Gradient:
Natural Gradient = Fisher 信息矩阵的逆 × 普通梯度
它自动对不同参数的“灵敏度”做了调整,解决了普通梯度更新中 step size 不一致、方向不合理的问题。
| 方法 | 约束空间 | 对灵敏度的处理 |
|---|---|---|
| 普通 Policy Gradient | 参数空间中的欧氏球体 | 忽略各参数对概率的影响差异 |
| Natural Policy Gradient | 分布空间中的 KL 椭球体 | 用 F 处理非均匀灵敏度 |
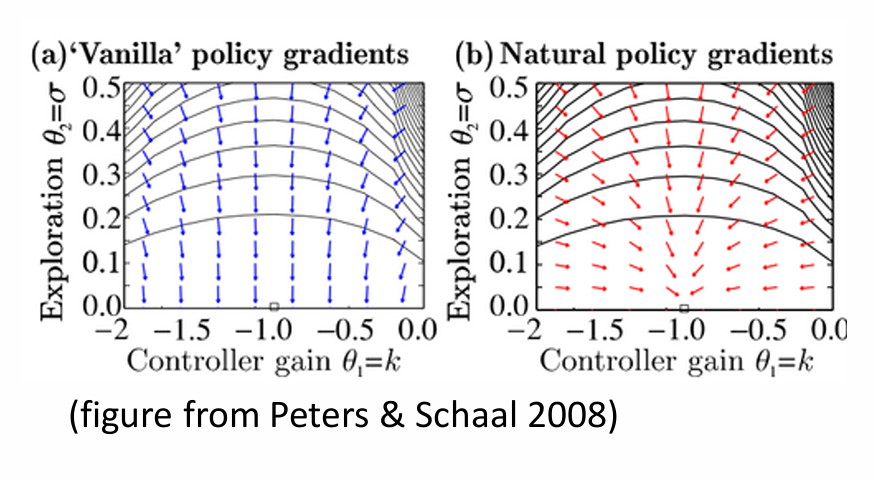
难点在于 F−1∇J\mathbf{F}^{-1} \nabla JF−1∇J 的计算,不能直接求 FFF 的逆,因为它是一个大矩阵;
-------------------- | ---------------------- | -------------------------- |
| 普通 Policy Gradient | 参数空间中的欧氏球体 | 忽略各参数对概率的影响差异 |
| Natural Policy Gradient | 分布空间中的 KL 椭球体 | 用 F 处理非均匀灵敏度 |
[外链图片转存中…(img-faYLDJqj-1753520265927)]
难点在于 F−1∇J\mathbf{F}^{-1} \nabla JF−1∇J 的计算,不能直接求 FFF 的逆,因为它是一个大矩阵;
实际中使用 Fisher-vector product + 共轭梯度法(Conjugate Gradient) 来逼近。


















 1249
1249

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









