






前言
前几天有个网友偷偷给我发私信,那叫一个信心满满地冲向阿里面试大模型岗位,结果悲催了,铩羽而归。到底是哪里出了岔子呢?
这篇文章,我们就从面试官的视角,来拆解这个 Transformer 的面试连环炮。如果是你在面试现场被这些问题 “轰炸”,到底该咋回答呢?嘿嘿,一起看看吧!
1、为什么Transformer推理要做KV缓存?
面试官心理分析
第一个问题一般都是先热热身,面试官问这个呢,其实是想看看,你知不知道 Transformer 的一个最基本的工作原理。
面试题解析
因为在 Transformer 中文本是逐个 token 生成的,每次新的预测,会基于之前生成的所有 token 的上下文信息。
这种对顺序数据的依赖会减慢生成过程,因为每次预测下一个 token,都需要重新处理序列中所有之前的 token。
举个例子,如果我们要预测第 100 个 token,那模型必须使用前面 99 个 token 的信息,这就需要对这些 token 进行矩阵运算,而这个矩阵运算是非常复杂和耗时的。
因此 KV 缓存就是为了减少这种耗时的矩阵运算,在 Transformer 推理过程中,会将这些键和值存储在缓存中,这样模型就可以在生成后续 token 的时候,直接访问缓存,而不需要重新计算。
2、KV 缓存的工作机制的什么样的?
OK,那既然你知道 KV 缓存是为了减少生成 token 时的矩阵运算,那它具体是怎么减小的?讲讲 KV 缓存的工作机制。
这个时候,你最好能结合画图讲出来,会很清晰。干讲很多东西讲不清楚,几张图就能说明白。
前面说了,由于解码器是因果的,也就是一个 token 的注意力只依赖于其前面的 token,在每个生成步骤中,我们希望只需要计算最新那个 token 的注意力,不需要重新计算相同的先前 token 注意力。
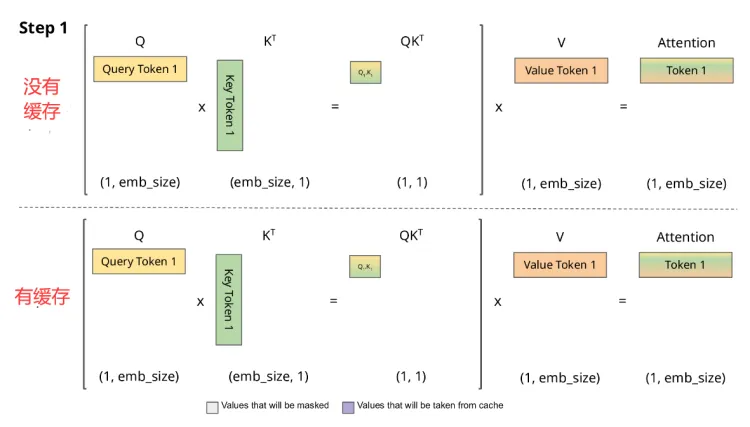
来看下面这两张图,分别是有缓存和没有缓存的情况。对于第一个新到的词,假设之前没有缓存过,每次 query 的 token 会和 K 做矩阵相乘,然后做 softmax 计算注意力得分,然后再和V相乘再输出。
我们对比一下上下两张图,其实有缓存和没有缓存的计算量是一样的,不过在下图中,我们会把这一步计算过的 K,V 缓存起来。
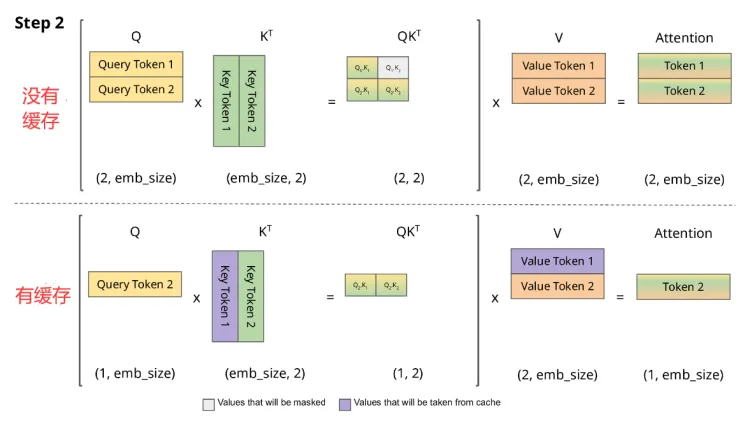
然后是第二个 token,这时候可以看出,紫色的是缓存的 K V,在没有缓存的时候需要重新计算一次 K V,而如果做了 K V 缓存,那么只需要把历史的 K, V 拿出来,同时只计算最新那个 token 的 K, V,并拼接成一个大矩阵就可以了。
对比一下,有缓存和没有缓存的计算量明显减少了一半。
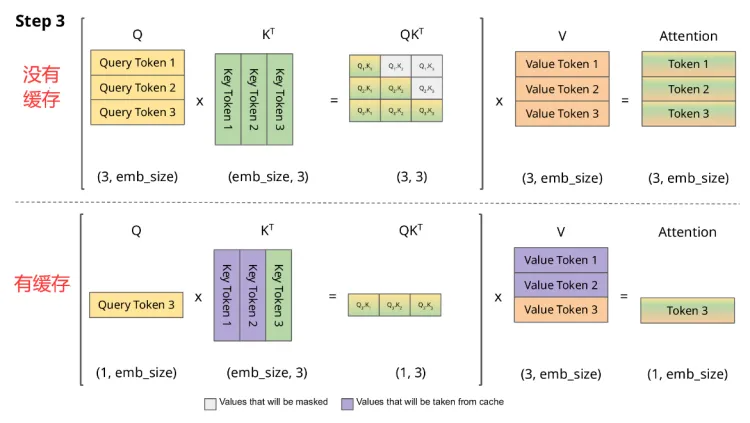
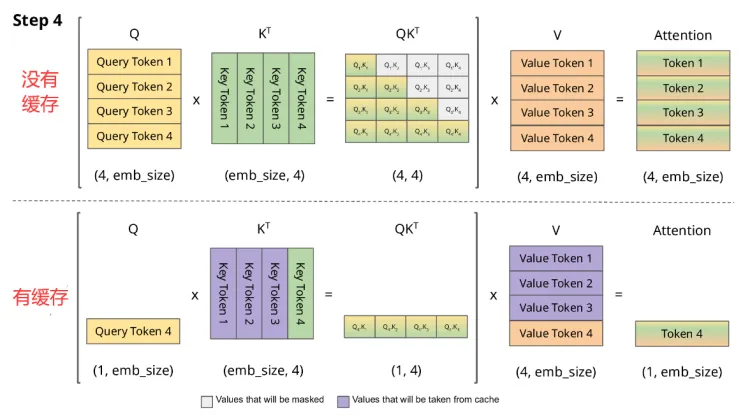
第三个第四个 token 也一样,每次历史计算过的 K V 就不用重新计算了,从而极大的减少了 self attention 的计算量,从序列长度的二次方变成了线性。
3、带有 KV 缓存优化的大模型推理过程包含几个阶段?
OK,那这个时候一些面试官会继续追问:那实际在解码的时候,一个典型的带有 KV 缓存优化的大模型推理过程包含几个阶段?
这个时候你首先要答出包含几个阶段实际在解码的时候,一个典型的带有 KV cache 优化的生成大模型的推理过程会包含两个阶段:prefill 和 decoding。
然后再回答每个阶段干的事情:
-
**prefill 阶段:**输入一个 prompt 序列,为每个 transformer 层生成 KV cache,同时输出第一个 token。
-
**decoding 阶段:**发生在计算第二个输出 token 至最后一个 token 过程中,这时 Cache 是有值的,每轮推理只需读取 Cache,同时将当前轮计算出的新的 Key、Value 追加写入至 Cache;FLOPs 降低,gemm 变为 gemv 操作,推理速度相对第一阶段变得更快。
4、如何估算KV缓存消耗的显存大小呢?
好,那下一个问题:如何估算 KV 缓存消耗的显存大小呢?
我们首先要知道,KV 缓存通常使用 float16 或者 bfloat16 数据类型,也就是以 16 位的精度存储张量。对于一个 token,KV 缓存会为每一层和每个注意力头存储一对 KV 张量。
KV 张量的总显存消耗,可以通过下面这个公式计算,这里我们以字节为单位。
层数 × KV注意力头的数量 × 注意力头的维度 × (位宽/8) × 2
解释一下这个公式,最后的 “2” 是因为有两组张量,也就是键和值。位宽通常为 16 位,由于 8 位 1 字节,因此将位宽除以 8,这样在 KV 缓存中,每 16 位参数占用 2 个字节。
5、KV 缓存为何在长文本和复杂模型结构下成瓶颈?
既然你知道怎么估算 KV 缓存,那面试官可能继续问你:为什么 KV 缓存在长文本和复杂模型结构场景下会成为瓶颈呢?
这个时候我们可以用实际的例子跟面试官说明,以 Llama 3 8B 为例,上面公式就变为:
32 × 8 × 128 × 2 × 2 = 131,072字节
这里注意,虽然 Llama 3 8B 有 32 个注意力头。不过由于 GQA 的存在,只有 8 个注意力头用于键和值,对于一个 token,KV 缓存占用 131,072 字节,差不多 0.1 MB。
这看起来好像不大,但对于许多不同类型的应用,大模型需要生成成千上万的 tokens。
举个例子,如果我们想利用 Llama 3 8B 的全部上下文大小是 8192,KV 缓存将为 8191 个 token 存储键值张量,差不多会占用 1.1 G 显存。
换句话说,对于一块 24 G 显存的消费级 GPU 来说,KV 缓存将占用其总显存的 4.5%。
对于更大的模型,KV 缓存增长得更快。比如对于 Llama 3 70B,它有 80 层,公式变为:
80 × 8 × 128 × 2 × 2 = 327,680 字节
对于 8191 个 token,Llama 3 70B 的 KV 缓存将占用 2.7 GB。注意这只是单个序列的显存消耗,如果我们进行批量解码,还需要将这个值乘以 batch size。
举个例子,使用 batch size 为 32 的 Llama 3 8B 模型将需要 35.2 GB 的 GPU 显存,一块消费级 GPU 就显然搞不定了。
所以 KV 缓存会随着文本长度增加和模型结构的复杂性增强大幅膨胀,对于需要处理超长上下文的应用可能会成为瓶颈。
6、KV 缓存缺陷的解决方案有哪些?
那下一个问题自然就来了:针对 KV 缓存这个缺陷,有什么解决方案?
答案是:量化 KV 缓存,量化可以降低参数精度,比如从 16 位降到 4 位。换句话说,一个 16 位张量可以缩减到原来的 1/4,而通过两位量化甚至可以缩减到 1/8。
所以上面的例子,理论上 4 bit 量化可以将 KV 缓存的大小从 35.2 G 缩减到 8.8 G,使用 2bit 量化甚至可以缩减到 4.4 GB。当然实际效果取决于所使用的算法及其超参数,需要结合具体情况分析。
那量化有没有什么缺点呢?
当然有,没有哪个方案是完美的。量化可能会减慢解码过程,并且可能显著影响 LLM 的准确性。
实际中需要通过调整量化超参,减轻这些影响,另外可以通过重写量化算子,对量化操作和反量化操作与其他算子做一些融合,来提高降低解码速度的影响。
7、是否了解有关 KV 缓存的最新技术?
那最后面试官可能还会问你一些开放性的问题,比如有没有了解过关于 KV 缓存的一些最新工作?
这个呢,就是看你的技术热情,有没有对业界最新的技术/paper,保持敏感度。
你可以这么来回答: 对于 KV 缓存这块,今年 KV-cache 复用从层内复用跨越到层间服用。微软最近新发了一篇论文,提出了 YOCO(You Only Cache Once),这是一个 KV Cache 层间共享的新思路。
同期 MIT-IBM Watson AI Lab 也发了一篇类似的论文,提出了 CLA( Cross-Layer Attention),即 KV Cache 跨层推理。这和 YOCO 不谋而合。
YOCO 的名称借鉴了单阶段目标检测始祖 YOLO 的风格。整篇论文提出的最核心的思想 KV Cache 共享方式,即层间共享。并且基于此,将上下文长度扩展到了 1 百万。
我们知道,目前最常见的 KV Cache 共享策略是 MQA/GQA。从 Layer 的视角来看,MQA/GQA 可以认为是层内 KV Cache 共享,而 YOCO 提出的想法,则可以认为是 Inter-Layer 层间 KV Cache 共享。
这个算法理论上的可以最多把 KV Cache 的 Memory 需求降低到 1/N(N 为 Transformer 层数)。
并且,这和层内 KV Cache 共享的技术,比如 MQA 和 GQA 是不冲突的,两者可以一起使用,从而极大地降低 KV Cache 的显存开销。
最后
为了助力朋友们跳槽面试、升职加薪、职业困境,提高自己的技术,本文给大家整了一套涵盖AI大模型所有技术栈的快速学习方法和笔记。目前已经收到了七八个网友的反馈,说是面试问到了很多这里面的知识点。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

面试题展示
1、请解释一下BERT模型的原理和应用场景。
答案:BERT(Bidirectional Encoder Representations from Transformers)是一种预训练的语言模型,通过双向Transformer编码器来学习文本的表示。它在自然语言处理任务中取得了很好的效果,如文本分类、命名实体识别等。
2、什么是序列到序列模型(Seq2Seq),并举例说明其在自然语言处理中的应用。
答案:Seq2Seq模型是一种将一个序列映射到另一个序列的模型,常用于机器翻译、对话生成等任务。例如,将英文句子翻译成法文句子。
3、请解释一下Transformer模型的原理和优势。
答案:Transformer是一种基于自注意力机制的模型,用于处理序列数据。它的优势在于能够并行计算,减少了训练时间,并且在很多自然语言处理任务中表现出色。
4、什么是注意力机制(Attention Mechanism),并举例说明其在深度学习中的应用。
答案:注意力机制是一种机制,用于给予模型对不同部分输入的不同权重。在深度学习中,注意力机制常用于提升模型在处理长序列数据时的性能,如机器翻译、文本摘要等任务。
5、请解释一下卷积神经网络(CNN)在计算机视觉中的应用,并说明其优势。
答案:CNN是一种专门用于处理图像数据的神经网络结构,通过卷积层和池化层提取图像特征。它在计算机视觉任务中广泛应用,如图像分类、目标检测等,并且具有参数共享和平移不变性等优势。
6、请解释一下生成对抗网络(GAN)的原理和应用。
答案:GAN是一种由生成器和判别器组成的对抗性网络结构,用于生成逼真的数据样本。它在图像生成、图像修复等任务中取得了很好的效果。
7、请解释一下强化学习(Reinforcement Learning)的原理和应用。
答案:强化学习是一种通过与环境交互学习最优策略的机器学习方法。它在游戏领域、机器人控制等领域有广泛的应用。
8、请解释一下自监督学习(Self-Supervised Learning)的原理和优势。
答案:自监督学习是一种无需人工标注标签的学习方法,通过模型自动生成标签进行训练。它在数据标注困难的情况下有很大的优势。
9、解释一下迁移学习(Transfer Learning)的原理和应用。
答案:迁移学习是一种将在一个任务上学到的知识迁移到另一个任务上的学习方法。它在数据稀缺或新任务数据量较小时有很好的效果。
10、请解释一下模型蒸馏(Model Distillation)的原理和应用。
答案:模型蒸馏是一种通过训练一个小模型来近似一个大模型的方法。它可以减少模型的计算和存储开销,并在移动端部署时有很大的优势。
11、请解释一下LSTM(Long Short-Term Memory)模型的原理和应用场景。
答案:LSTM是一种特殊的循环神经网络结构,用于处理序列数据。它通过门控单元来学习长期依赖关系,常用于语言建模、时间序列预测等任务。
12、请解释一下BERT模型的原理和应用场景。
答案:BERT(Bidirectional Encoder Representations from Transformers)是一种预训练的语言模型,通过双向Transformer编码器来学习文本的表示。它在自然语言处理任务中取得了很好的效果,如文本分类、命名实体识别等。
13、什么是注意力机制(Attention Mechanism),并举例说明其在深度学习中的应用。
答案:注意力机制是一种机制,用于给予模型对不同部分输入的不同权重。在深度学习中,注意力机制常用于提升模型在处理长序列数据时的性能,如机器翻译、文本摘要等任务。
14、请解释一下生成对抗网络(GAN)的原理和应用。
答案:GAN是一种由生成器和判别器组成的对抗性网络结构,用于生成逼真的数据样本。它在图像生成、图像修复等任务中取得了很好的效果。
15、请解释一下卷积神经网络(CNN)在计算机视觉中的应用,并说明其优势。
答案:CNN是一种专门用于处理图像数据的神经网络结构,通过卷积层和池化层提取图像特征。它在计算机视觉任务中广泛应用,如图像分类、目标检测等,并且具有参数共享和平移不变性等优势。
16、请解释一下强化学习(Reinforcement Learning)的原理和应用。
答案:强化学习是一种通过与环境交互学习最优策略的机器学习方法。它在游戏领域、机器人控制等领域有广泛的应用。
17、请解释一下自监督学习(Self-Supervised Learning)的原理和优势。
答案:自监督学习是一种无需人工标注标签的学习方法,通过模型自动生成标签进行训练。它在数据标注困难的情况下有很大的优势。
18、请解释一下迁移学习(Transfer Learning)的原理和应用。
答案:迁移学习是一种将在一个任务上学到的知识迁移到另一个任务上的学习方法。它在数据稀缺或新任务数据量较小时有很好的效果。
19、请解释一下模型蒸馏(Model Distillation)的原理和应用。
答案:模型蒸馏是一种通过训练一个小模型来近似一个大模型的方法。它可以减少模型的计算和存储开销,并在移动端部署时有很大的优势。
20、请解释一下BERT中的Masked Language Model(MLM)任务及其作用。
答案:MLM是BERT预训练任务之一,通过在输入文本中随机mask掉一部分词汇,让模型预测这些被mask掉的词汇。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









