






前言
还记得那些年我们一起追过的BERT吗?
LLM时代它们哪去了?
它们曾经是NLP领域的顶流明星,各种变体层出不穷,ELECTRA、DEBERTA、ROBERTA、XLM-ROBERTA…每一个名字都闪耀夺目。
可如今,LLM时代的浪潮席卷而来,这些小模型们似乎都销声匿迹了?
Leo Boytsov最近就发文:
亲爱的懒惰的推特用户们:我们是不是已经不再生产更好的预训练BERT或GPT模型来微调排序器/分类器了?之前我们有ELECTRA、DEBERTA、ROBERTA和XLM-ROBERTA。有什么更新/更好的吗?还是说大家都转向微调GEMMA、LLAMA和MISTRAL了?
这位老兄的感慨引发了不少讨论,Sebastian Raschka 也被勾起了兴趣,表示这是个值得深入探讨的话题。
确实,BERT们到底去哪了?
是真的江湖地位不保了,还是另有隐情呢?
BERT们还好用吗?
首先,让我们来看看BERT们的实力如何。
Sebastian分享了一个有趣的实验:他们用560百万参数的BLOOM模型在IMDB数据集上进行了微调,最终获得了87%的准确率。
看起来还不错?等等,来看看bert 的。
要知道,用358百万参数的RoBERTa模型,人家都能轻松拿下96%的准确率!
BERT 也并非廉颇老矣?
LLM时代的新宠儿
接下来才是重点。
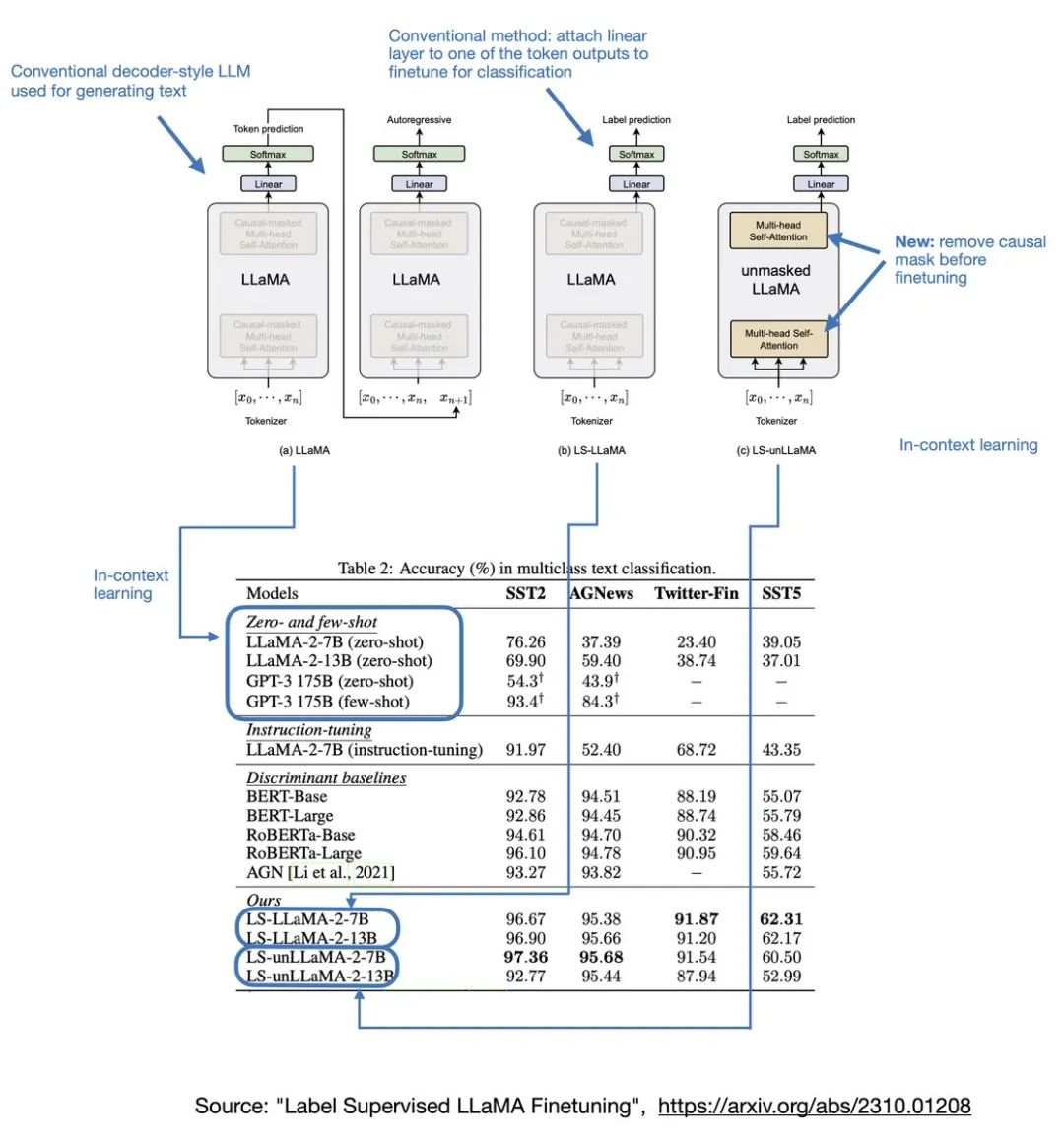
最近有篇论文《Label Supervised LLaMA Finetuning》可能会另有结论。研究发现,如果你用7B或13B的Llama 2模型来做分类任务,效果居然出奇的好!
更妙的是,如果你把因果注意力掩码(causal attention mask)去掉,效果会更好。
这下轮到BERT们尴尬了?
不过,别高兴太早,Sebastian提醒到:
需要注意的是,7B的Llama 2模型比BERT大70倍,运行成本也高得多。因此,这是一个需要权衡准确性和计算效率的决定。
小模型的未来在哪里?
是不是意味着BERT们真的要退出历史舞台了呢?
这不好下定论。
如Sebastian所说,这个话题值得写一篇综述好好梳理一下。
毕竟,在某些场景下,小模型依然有它的优势:
-
计算资源友好:不是每个团队都有能力部署动辄上百亿参数的大模型。
-
特定任务表现出色:在一些细分领域,精心设计的小模型可能比通用大模型更有效。
-
迭代更新快:小模型训练周期短,更容易针对新数据进行更新。
而且,谁说小模型就不能借鉴大模型的技术呢?
比如,我们完全可以尝试用大模型的训练方法来优化小模型,或者探索大小模型协同工作的方案。
结语
总的说来,BERT们可能是暂时沉寂了,但绝不意味着它们就此消失。
技术迭代总是快得让人目不暇接。今天的弄潮儿,明天可能就成了过气网红。但每一项技术都有它存在的价值和意义。
模型就像工具箱里的工具,大锤和螺丝刀各有所长。重要的是选择适合任务的那个。
那么,你们觉得BERT们还有翻身的机会吗?
最后的最后
感谢你们的阅读和喜欢,我收藏了很多技术干货,可以共享给喜欢我文章的朋友们,如果你肯花时间沉下心去学习,它们一定能帮到你。
因为这个行业不同于其他行业,知识体系实在是过于庞大,知识更新也非常快。作为一个普通人,无法全部学完,所以我们在提升技术的时候,首先需要明确一个目标,然后制定好完整的计划,同时找到好的学习方法,这样才能更快的提升自己。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









