







序章嘛咱多唠两句。花了大半个月才反反复复,断断续续读完了图灵奖得主Judea Pearl的The Book of WHY,感觉先读第四章的案例会更容易理解前三章相对抽象的内容。工作中对于归因问题迫切的需求,以及这两年深度学习在,都让我对因果推理在未来几年的爆发心怀希望。它最大的优势就是能回答’为什么’以及’假如这样做会怎样’等对实际业务有着根本意义的问题。对于这个领域我也是新人,所以只能抛出一些观点来供大家讨论。
Now!检验我带货能力的时候到了,如果你在和数据打交道的过程中也碰到过以下的问题,那我也向你推荐这本书。它不一定能解答你的问题,但至少能让你明白问题的根源:
- 如何解释数据分析中有违常理或者自相矛盾的结论?为什么把数据分组和整体计算会得到不同的结果? Eg. 药物实验结果表明对高血压患者药物无效,对低血压患者药物也无效,但合起来对全部患者药物有效?
- 已知特征X=x1的样本呈现的特点,或者Y=y1的样本有X=的特征,如何计算干预X对Y的影响 Eg. 看快手视频喜欢评论的用户活跃程度更高,那引导用户去发表评论能让他们更活跃么?
- 建模特征应该如何选择,以及特征通过那些途径最终影响Y 个人并不喜欢有啥放啥的建模方式,既增加模型不稳定性还会增加特征解释的难度。尤其在业务中我们更多想知道的是不同特征影响Y的方式
- 无法开展AB实验的时候,我们如何从观测数据中近似因果关系 Eg. 最常遇到这种问题的是社会学,医学实验,例如当兵经历对收入的影响。但这也提醒我们有些成本高的AB实验其实是有可能从已有数据中找到近似答案的。
这里简单列几个因果推理和统计学的差异,我们在之后的章节会逐一展开:
- 统计学解决的是P(Y|X),它更多是对观测的刻画。而因果推理旨在解决What-if问题,用Do-Caculus来表达就是P(Y|do(X)),既对X进行干预,对Y的影响。一个同事开玩笑说因果推理就像开启上帝之眼
- 统计学认为数据是一切,而因果推理坚持数据产生的过程是解释数据所必须的。想直观感受差异的可以看下这个 Toy Example
- 统计完全客观,而因果推理需要依赖基于经验等因素给出因果图(DAG)再进行分析计算。
作为序章最重要的是什么?吸引人眼球!所以本章通过5个数据分析中经典案例,看看当统计陷入两难,因果推理是如何变身奥特曼来打小怪兽的!
以下案例只为直观感受因果推理的现实意义,暂不考虑统计显著,小样本不置信等问题
Confounding Bias - Simpson Paradox
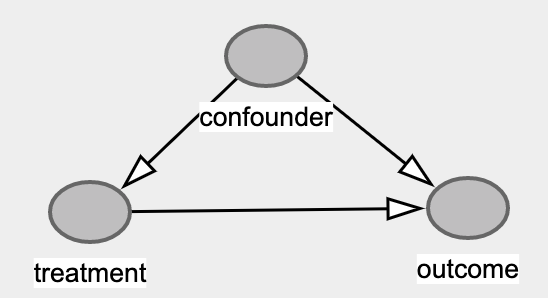
Confounding在数据分析中非常常见,既存在同时影响treatment和outcome的变量没有被控制,它是统计分析要控制变量的根本原因之一,是AB实验有效的背后逻辑,它也直接导致了
(P(Y|X)neqp(Y|do(x)))
**。**但往往Confounder的存在只有在分析结果严重不符合逻辑时才被人们想到。
离散Confounder - 案例1. 今天你吃药了么?
以下是一次观测性医学实验的结果,分别给出男性和女性在服/不服用药物后心脏病发作的概率。有趣的是这种药物既不能显著降低女性病发概率,也不能显著降低男性病发概率,但却能降低整体的病发概率,你是分析师请问这种药物有用么?
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









