







显而易见的,大模型有诸多优缺点,关于其如何通过神经网络生成文本的能力暂且不论。
本篇通过简单提问映射目前大模型对数据的定位和整合的能力的升级。首先是初代大模型的数据定位、整合和输出。如下图



可以看出,初代大模型,在对于问题信息和数据之间的定位关联问题上,有很大的偏差,并且数据单一,没有明显的判断思路。造成这一类结果的原因,很有可能是因为数据单一,或者算法运行的单一。我的问题中有明显的虚构对象,但是模型无法识别。
接下来看一看,经过多次升级的大模型的回复。
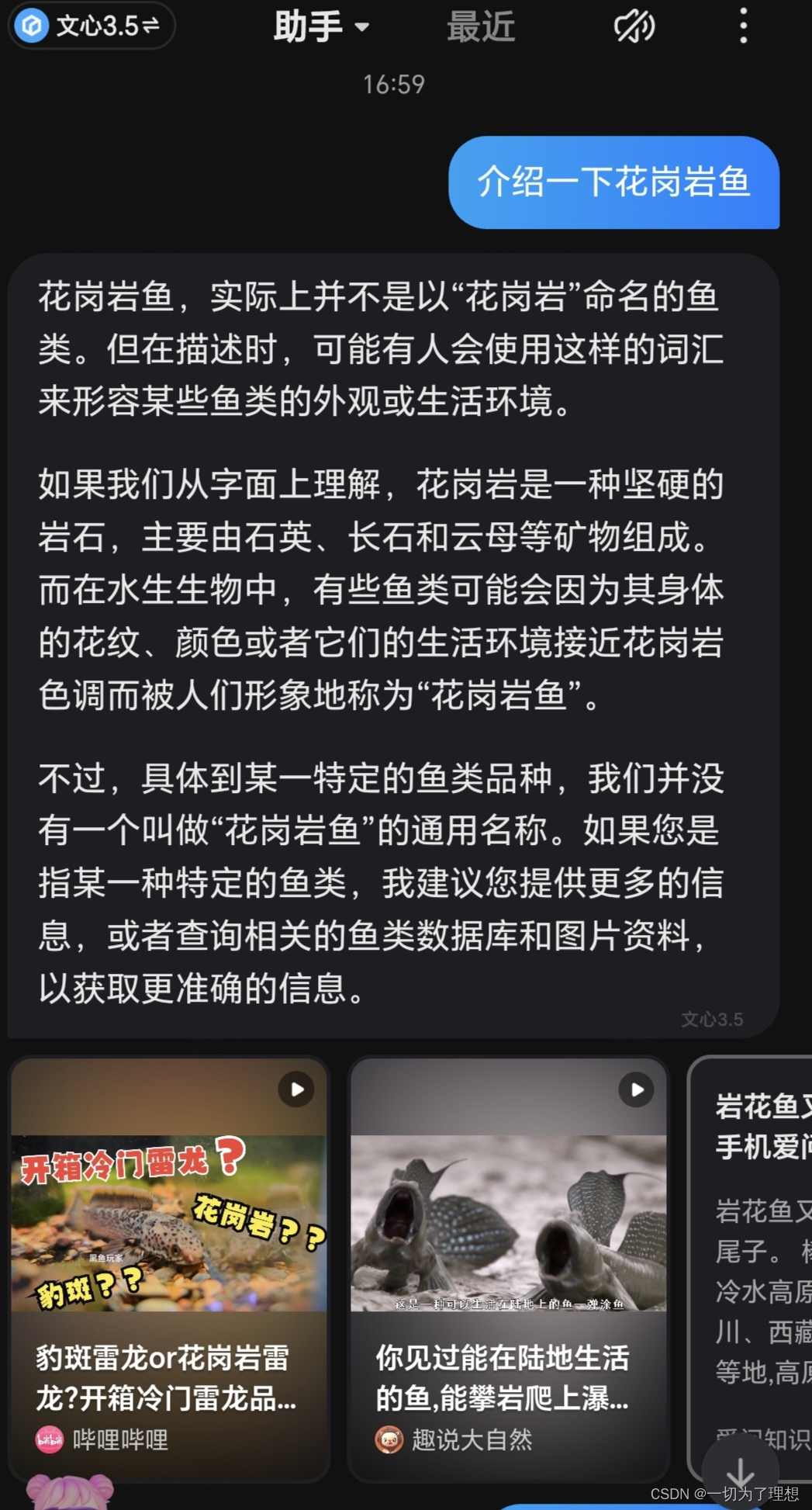
显而易见的,大模型有诸多优缺点,关于其如何通过神经网络生成文本的能力暂且不论。
本篇通过简单提问映射目前大模型对数据的定位和整合的能力的升级。首先是初代大模型的数据定位、整合和输出。如下图
可以看出,初代大模型,在对于问题信息和数据之间的定位关联问题上,有很大的偏差,并且数据单一,没有明显的判断思路。造成这一类结果的原因,很有可能是因为数据单一,或者算法运行的单一。我的问题中有明显的虚构对象,但是模型无法识别。
接下来看一看,经过多次升级的大模型的回复。

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言




 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章























