






如A网页的数据之前在蜘蛛爬行后已经被保存在数据库中了,当蜘蛛第二次爬行A网页时,会将A网页此时的数据和数据库中的数据进行对比,如果蜘蛛发现A网页的内容更新了,就会认为这个网页更新频率多,蜘蛛抓取这个页面的频率也会更加频繁,如果页面和上次储存的数据完全一样,就说明页面是没更新,蜘蛛就会减少自己爬行该页面的频率。
3.高质量的外链
张三是班上公认的人品好为人公正的学霸,李四是班上惹人讨厌最爱撒谎的学生,张三给大家说王五这个人真的很聪明为人也很善良,其他同学都会认为王五肯定是这样,李四给其他同学说王五这个人很好,其他同学基本不会相信李四的鬼话。
同样一句话,从不同人的嘴里说出来,造成的结果、影响都不一样。
链接的引用也是这样,比如在一个蜘蛛认为的高质量页面中,页面在最后引用了一个链接,指向你的页面,那么这个高质量页面的引用,在蜘蛛判断你的网页是否是高质量网页时,也会产生一定的影响,被高质量网页引用的多了(超级多的大佬夸你人好),那么蜘蛛在判断你页面时产生的影响也就更大(同学也觉得你就是人好)。
4.与首页的距离
一般来说自己网站被其他网站引用最多的页面就是首页,所以它的权重相比来说是最高的,比如A页面是A网站的首页,可以得出的结论是,离A网页更进的页面,页面权重也容易更高,比如A页面上的超链接更容易被蜘蛛爬行,更容易获得蜘蛛的抓取,那些没被蜘蛛发现的网页,权重自然就是0。
还有一点比较重要的是,蜘蛛在爬行页面时会进行一定程度的复制检测,也就是当前被爬行的页面的内容,是否和已经保存的数据有重合(当页面内容为转载/不当抄袭行为时就会被蜘蛛检测出来),如果一个权重很低的网站上有大量转载/抄袭行为,蜘蛛很可能不会再继续爬行。
之所以要这么做也是为了用户的体验,如果没有这些去重步骤,当用户想要搜索一些内容时,发现返回的结果全都是一模一样的内容,会大大影响用户的体验,最后导致的结果就是这个搜索引擎绝对不会有人再用了,所以为了用户使用的便利,也是为了自己公司的正常发展。
地址库
互联网上的网页这么多,为了避免重复爬行和抓取网页,搜索引擎会建立地址库,一个是用来记录已经被发现但还没有抓取的页面,一个是已经被抓取过的页面。
待访问地址库(已经发现但没有抓取)中的地址来源于下面几种方式:
1.人工录入的地址
2.蜘蛛抓取页面后,从HTML代码中获取新的链接地址,和这两个地址库中的数据进行对比,如果没有,就把地址存入待访问地址库。
3.站长(网站负责人)提交上去的想让搜索引擎抓取的页面。(一般这种效果不大)
蜘蛛按照重要性从待访问地址库中提取URL,访问并抓取页面,然后把这个URL地址从待访问地址库中删除,放进已访问地址库中。
文件存储
蜘蛛会将抓取的数据存入原始页面数据库。
存入的数据和服务器返回给蜘蛛的HTML内容是一样的,每个页面存在数据库里时都有自己的一个独一无二的文件编号。
预处理
我们去商场买菜时,会看到蔬菜保险柜里的这些蔬菜被摆放的整整齐齐,这里举的例子是那些用保鲜膜包好有经过包装的蔬菜。

最后呈现在顾客面前的就是上面这张图那样,包装完好,按照不同的分类摆放有序,顾客一眼就能很清楚的看到每个区域分别是什么蔬菜。
在最终完成这个结果之前,整个流程大概也是三个步骤:
1.选出可以售卖的蔬菜
从一堆蔬菜中,选出可以拿去售卖的蔬菜。
2.预处理
此时你面前摆放的就是全部可以拿去售卖的蔬菜了,但是如果,今天就要把这些蔬菜放到蔬菜保险柜中的话,你今天才开始对这些蔬菜进行整理会浪费大量的时间(给蔬菜进行包装等),说不定顾客来了蔬菜还没整理好。
所以你的解决方法是,提前将这些可以拿去售卖的蔬菜提前包装好,存放在仓库里,等保险柜中的蔬菜缺少了需要补货时,花个几分钟时间跑去仓库把蔬菜拿出来再摆放再货架上就行了。(我猜的,具体商场里的流程是怎么样的我也不知道,为了方便后续的理解用生活上的例子进行说明效果会更好)
3.摆放上保险柜
也就是上面最后一段内容那样,当需要补货时,从仓库里拿出包装好的蔬菜,按照蔬菜的类别摆放到合适的位置就可以了,这个就是最后的排序步骤。
回到搜索引擎的工作流程中,这个预处理的步骤就和上面商场预处理步骤的作用一样。
当蜘蛛完成数据收集后,就会进入到这个步骤。
蜘蛛所完成的工作,就是在收集了数据后将数据(HTML)存入原始页面数据库。
而这些数据,不是用户在搜索后,直接用来进行排序并展示在搜索结果页的数据。
原始页面数据库中的页面数量都是在数万亿级别以上,如果在用户搜索后对原始页面数据库中的数据进行实时排序,让排名程序(每个步骤所使用的程序不一样,收集数据的程序叫蜘蛛,排名时所用的程序是排名程序)分析每个页面数据与用户想搜索的内容的相关性,计算量太大,会浪费太多时间,不可能在一两秒内返回排名结果。
因此,我们需要先将原始页面数据库中的数据进行预处理,为最后的排名做好准备。
提取文字
我们存入原始页面数据库中的,是HTML代码,而HTML代码中,不仅有用户在页面上直接可以看到的文字内容,还有其他例如js,AJAX等这类搜索引擎无法用于排名的内容。
首先要做的,就是从HTML文件中去除这些无法解析的内容,提取出可以进行排名处理步骤的文字内容
比如下面这段代码
<img alt=“Google” src=“/images/test.png”
可以看出整个HTML中,真正属于文字内容的信息只有两句
这是一个描述内容
软件工程师需要了解的搜索引擎知识
hi
搜索引擎最终提取出来的信息就是这四句,用于排名的文字也是这四句。
可以提取出来的文字内容大概就是,Meta标签中的文字、img标签alt属性中的文字、Flash文件的替代文字、链接锚文字等。
中文分词
分词是中文搜索引擎特有的步骤,搜索引擎存储/处理页面/用户搜索时都是以词为基础的。
I’m fine, and you?
中文和英文等语言单词不同,在使用英文时各个单词会有空格分隔,搜索引擎可以直接把每一个句子划分为多个英文单词的集合。而对中文来说,词汇和词汇之间是没有任何分隔符可以对各词汇进行分隔的。
比如这句话里的词就是连接在一起的
对于这种情况,搜索引擎首先需要分辨哪几个字组成一个词,如 我喜欢吃【水果】,或者哪些字本身就是一个词,如 这里有【水】,
再如下面这句话
你好,这是一篇关于搜索引擎的文章
搜索引擎会将这一段文字拆解成一个个词汇,大概如下
你好
这是
一篇
关于
搜索引擎
的
文章
搜索引擎将这段文字拆解成了7个词汇(我瞎猜的,具体多少个我也不知道,每个搜索引擎分词的方法都不一样)
中文分词的方法基本上有两种:
-
基于词典匹配
-
基于统计
1.基于词典匹配
将需要分析的一段汉字与一个时间创建好的词典中的词条进行匹配,如果在这段汉字中扫描到词典中已有的词条则匹配成功。
这种匹配方式最简单,但匹配的正确程序取决于这个词典的完整性和更新情况。
2.基于统计
一般是通过机器学习完成,通过对海量网页上的文字样本进行分析,计算出字与字相邻出现的统计概率,几个字相邻出现越多,就越可能形成一个词。
这种优势是对新出现的词反应更快速。
实际使用中的分词系统都是两种方法同时混合使用。
去停止词
不管是英文还是中文,页面中都会有一些出现频率很高的&对内容没有任何影响的词,如中文的【的】、【啊】、【哈】之类,这些词被称为停止词。
英文中常见的停止词有[the]/[a]/[an]等。
搜索引擎会去掉这些停止词,使数据主题更突出,减少无谓的计算量。
去掉噪声词
大部分页面里有这么一部分内容对页面主题没什么贡献,比如A页面的内容是一篇关于SEO优化的文章,关键词是SEO,但是除了讲解SEO这个内容的主体内容外,共同组成这个页面的还有例如页眉,页脚,广告等区域
在这些部分出现的词语可能和页面内容本身的关键词并不相关。
比如导航栏中如何出现【历史】这个词,导航栏上想要表达的实际是历史记录之类的意思,搜索引擎可能会把他误以为是XX国家历史,XX时代历史之类这种层面的【历史】,搜索引擎所理解的和页面本身内容想表达的完全不相关,所以这些区域都属于噪声,在搜索引擎分析一个页面的时候,它们只会对页面主题起到分散作用。
搜索引擎的排名程序在对数据进行排名时不能参考这些噪声内容,我们在预处理阶段就需要把这些噪声时别出来并消除他们。
消除噪声的方法是根据HTML的标签对页面进行分块,如页眉是header标签,页脚是footer标签等等,去除掉这些区域后,剩下的才是页面主体内容。
去重
也就是去掉重复的网页,同一篇文章经常会重复在不同网站/同一个网站的不同网址上。为了用户的体验,去重步骤是必须的,搜索引擎会对页面进行识别&删除重复内容,这个过程称为蛆虫和。
去重的方法是先从页面主体内容中选取最有代表性的一部分关键词(经常是出现频率最高的关键词,由于之前已经有了去停止词的步骤,因此在这时出现频率最高的关键词可能就真的是整个页面的关键词了),然后计算这些关键词的数字指纹。
通常我们在页面中选取10个关键词就可以达到比较高的计算准确性了。
典型的指纹计算方法如MD5算法(信息摘要算法第五版)。这类指纹算法的特点是,输入(也就是上面提取出来的关键词)只要有任何微小的变化,都会导致计算出的指纹有很大差距。
比如我们用两个数相乘,第一组和第二组的不同仅仅是第一个数字 0.001 的差别,最终生成的结果却千差万别。

了解了搜索引擎的去重算法后,就会发现那些在文章发布者眼里的原创内容实际对搜索引擎来说就是非原创,比如简单的增加/删除【的】【地】等这些去停止词、调换段落顺序、混合不同文章等操作,在搜索引擎进行去重算法后,都会被判断为非原创内容,因为这些操作并不会改变文章的关键词。
(比如我写的这篇笔记里的一些段落就是‘借鉴’了一下,我是从书里看的不是在网页上直接浏览的,如果搜索引擎在对我这篇文章进行文字提取、分词、消噪、去重后,发现剩下的关键词和已收录的某个网页数据的内容都匹配上了,就会认为我是伪原创甚至非原创,最终影响的就是我这篇文章在搜索引擎工作原理这个关键词上的排名)
正向索引
正向索引可以简称为索引。
经过上述各步骤(提取、分词、消噪、去重)后,搜索引擎最终得到的就是独特的、能反映页面主体内容的、以词为单位的内容。
接下来由搜索引擎的索引程序提取关键词,按照分词程序划分好的词,把页面转换为一个由关键词组成的集合,同时还需要记录每一个关键词在页面上的出现频率、出现次数、格式(如是出现在标题标签、黑体、h标签、还是锚文字等)、位置(如页面第一段文字等)。
搜索引擎的索引程序会将页面和关键词形成的词表结构存储进索引库。
简化的索引词表形式如图
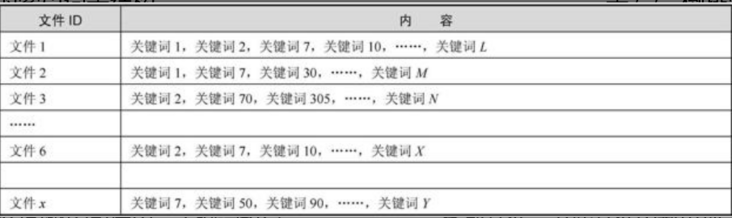
每个文件都对应一个文件ID,文件内容被表示成一串关键词的集合。
实际上在搜索引擎索引库中,关键词也已经转换为关键词ID,这样的数据结构被称为正向索引。
倒排索引
正向索引不能直接用于排名,假设用户搜索关键词【2】,如果只存在正向索引,排名程序需要扫描所有索引库中的文件,找出包含关键词【2】的文件,再进行相关性计算。
这样的计算量无法满足实时返回排名结果的要求。
我们可以提前对所有关键词进行分类,搜索引擎会将正向索引数据库重新构造为倒排索引,把文件对应到关键词的映射转换为关键词到文件的映射,如下图
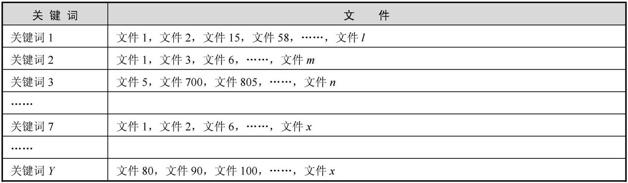
在倒排索引中关键词是主键,每个关键词都对应着一系列文件,比如上图第一排右侧显示出来的文件,都是包含了关键词1的文件。
这样当用户搜索某个关键词时,排序程序在倒排索引中定位到这个关键词,就可以马上找出所有包含这个关键词的文件。
给搜索结果进行排名
经过前面的蜘蛛抓取页面,对数据预处理&索引程序计算得到倒排索引后,搜索引擎就准备好可以随时处理用户搜索了。
用户在搜索框输入想要查询的内容后,排名程序调用索引库的数据,计算排名后将内容展示在搜索结果页中。
搜索词处理
搜索引擎接收到用户输入的搜索词后,需要对搜索词做一些处理,然后才进入排名过程。
搜索词处理过程包括如下几个方面:
1.中文分词
和之前预处理步骤中的分词流程一样,搜索词也必须进行中文分词,将查询字符串转换为以词为单位的关键词组合。分词原理和页面分词时相同。
2.去停止词
同上。
3.指令处理
上面两个步骤完成后,搜索引擎对剩下的内容的默认处理方式是在关键词之间使用【与】逻辑。
比如用户在搜索框中输入【减肥的方法】,经过分词和去停止词后,剩下的关键词为【减肥】、【方法】,搜索引擎排序时默认认为,用户想要查询的内容既包含【减肥】,也!注意这个也!!!也包含【方法】!
只包含【减肥】不包含【方法】,或者只包含【方法】不包含【减肥】的页面,都会被认为是不符合搜索条件的。
文件匹配
搜索词经过上面的处理后,搜索引擎得到的是以词为单位的关键词集合。
进入的下一个阶段-文件匹配阶段,就是找出含有所有关键词的文件。
在索引部分提到的倒排索引使得文件匹配能够快速完成,如下图
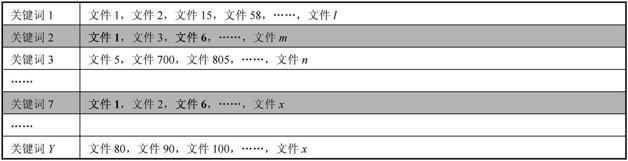
假设用户搜索【关键词2 关键词7】,排名程序只要在倒排索引中找到【关键词2】和【关键词7】这两个词,就能找到分别含有这两个词的所有页面文件。
经过简单计算就能找出既包含【关键词2】,也包含【关键词7】的所有页面:【文件1】和【文件6】。
初始子集的选择
找到包含所有关键词的匹配文件后,还不能对这些文件进行相关性计算,因为在实际情况中,找到的文件经常会有几十万几百万,甚至上千万个。要对这么多文件实时进行相关性计算,需要的时间还是挺长的。
实际上大部分用户只喜欢查看前面两页,也就是前20个结果,后面的真的是懒都懒得翻!
对于google搜索引擎来说,最多只会给用户返回1000个搜索结果,如下(100页,每页10条结果)
而百度搜索引擎,最多只会返回760条结果
所以搜索引擎只需要计算前1000/760个结果的相关性,就能满足要求。
由于所有匹配文件都已经具备了最基本的相关性(这些文件都包含所有查询关键词),搜索引擎会先筛选出1000个页面权重较高的一个文件,通过对权重的筛选初始化一个子集,再对这个子集中的页面进行相关性计算。
相关性计算
用权重选出初始子集之后,就是对子集中的页面计算关键词相关性的步骤了。
计算相关性是排名过程中最重要的一步。
影响相关性的主要因素包括如下几个方面:
1.关键词常用程度。
经过分词后的多个关键词,对整个搜索字符串的意义贡献并不相同。
越常用的词对搜索词的意义贡献越小,越不常用的词对搜索词的意义贡献越大。举个例子,假设用户输入的搜索词是“我们冥王星”。“我们”这个词常用程度非常高,在很多页面上会出现,它对“我们冥王星”这个搜索词的辨识程度和意义相关度贡献就很小。找出那些包含“我们”这个词的页面,对搜索排名相关性几乎没有什么影响,有太多页面包含“我们”这个词。
而“冥王星”这个词常用程度就比较低,对“我们冥王星”这个搜索词的意义贡献要大得多。那些包含“冥王星”这个词的页面,对“我们冥王星”这个搜索词会更为相关。
常用词的极致就是停止词,对页面意义完全没有影响。
所以搜索引擎对搜索词串中的关键词并不是一视同仁地处理,而是根据常用程度进行加权。不常用的词加权系数高,常用词加权系数低,排名算法对不常用的词给予更多关注。
我们假设A、B两个页面都各出现“我们”及“冥王星”两个词。但是“我们”这个词在A页面出现于普通文字中,“冥王星”这个词在A页面出现于标题标签中。B页面正相反,“我们”出现在标题标签中,而“冥王星”出现在普通文字中。那么针对“我们冥王星”这个搜索词,A页面将更相关。
2.词频及密度。一般认为在没有关键词堆积的情况下,搜索词在页面中出现的次数多,密度越高,说明页面与搜索词越相关。当然这只是一个大致规律,实际情况未必如此,所以相关性计算还有其他因素。出现频率及密度只是因素的一部分,而且重要程度越来越低。
3.关键词位置及形式。就像在索引部分中提到的,页面关键词出现的格式和位置都被记录在索引库中。关键词出现在比较重要的位置,如标题标签、黑体、H1等,说明页面与关键词越相关。这一部分就是页面SEO所要解决的。
4.关键词距离。切分后的关键词完整匹配地出现,说明与搜索词最相关。比如搜索“减肥方法”时,页面上连续完整出现“减肥方法”四个字是最相关的。如果“减肥”和“方法”两个词没有连续匹配出现,出现的距离近一些,也被搜索引擎认为相关性稍微大一些。
5.链接分析及页面权重。除了页面本身的因素,页面之间的链接和权重关系也影响关键词的相关性,其中最重要的是锚文字。页面有越多以搜索词为锚文字的导入链接,说明页面的相关性越强。
链接分析还包括了链接源页面本身的主题、锚文字周围的文字等。
The End
欢迎自荐投稿到《前端技术江湖》,如果你觉得这篇内容对你挺有启发,记得点个 **「在看」**哦
点个『在看』支持下 

















 1182
1182

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









