







既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上C C++开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
cv::imshow("input", src);
cv::waitKey(0);
return 0;
}
void load_plate_recog_model(InferenceEngine::InferRequest& plate_request, std::string& plate_input_name1, std::string& plate_input_name2, std::string& plate_output_name)
{
//1、初始化Core ie
InferenceEngine::Core ie;//IE的核心类 其实就是IE
//2、ie.ReadNetwork 读取CNN网络 需要模型里面的两个文件 resnet18.bin resnet18.xml
std::string xmlFilename = "D:/code/OpenVINO/license-plate-recognition-barrier-0001/FP32/license-plate-recognition-barrier-0001.xml";
std::string binFilename = "D:/code/OpenVINO/license-plate-recognition-barrier-0001/FP32/license-plate-recognition-barrier-0001.bin";
InferenceEngine::CNNNetwork network = ie.ReadNetwork(xmlFilename, binFilename);//读取到加载CNN网络就会自动解析网络结构然后就可以获取输入输出了
//3、获取输入与输出格式并设置精度
InferenceEngine::InputsDataMap inputs = network.getInputsInfo();//InputsDataMap本质是一个vector的数组,如果你有多个输入的话则对应每个
InferenceEngine::OutputsDataMap outputs = network.getOutputsInfo();
std::string input_name = "";
std::string output_name = "";
int cnt = 0;
for (auto item : inputs)//因为这个模型有两个输入 则会循环两次的
{
if (cnt == 0)
{
plate_input_name1 = item.first;
auto input_data = item.second;//是一个数据结构 暂采用C++11的auto自动推断 因为只有一个输入则暂时这样定义在里面设置它的精度
input_data->setPrecision(Precision::U8);//输入图片数据格式为unsigned char 就是8位的精度
//这个也是根据模型设置的输入数据模式
input_data->setLayout(Layout::NCHW);
//也是根据模型设置输入的ColorFormat
input_data->getPreProcess().setColorFormat(ColorFormat::BGR);//该模型规定输入图片为BGR
}
if (cnt == 1)
{
plate_input_name2 = item.first;
auto input_data = item.second;
input_data->setPrecision(Precision::FP32);
}
//input_name = item.first;
std::cout << "input name " << cnt+1 << " = " << item.first << std::endl;
cnt++;
}
for (auto item : outputs)
{
plate_output_name = item.first;
auto output_data = item.second;//是一个数据结构 暂采用C++11的auto自动推断 因为只有一个输入则暂时这样定义在里面设置它的精度
output_data->setPrecision(Precision::FP32);//输出还是浮点数输出的
std::cout << "output name = " << plate_output_name << std::endl;
}
//4、获取可执行网络并链接硬件
auto executable_network = ie.LoadNetwork(network, "CPU");//会加载网络到CPU这个硬件,也可以设置成GPU
//5、创建推理请求 创建之后就可以尝试进行推理了,但是实际在推理之前还有很多事情要做,如格式设置
plate_request = executable_network.CreateInferRequest();
}
void fetch_plate_text(InferenceEngine::InferRequest& plate_request, std::string& plate_input_name1, std::string& plate_input_name2, std::string& plate_output_name, cv::Mat& image, cv::Mat plateROI)
{
//设置输入
auto input1 = plate_request.GetBlob(plate_input_name1);
size_t num_channels = input1->getTensorDesc().getDims()[1];
size_t h = input1->getTensorDesc().getDims()[2];
size_t w = input1->getTensorDesc().getDims()[3];
size_t image_size = h * w;
cv::Mat blob_image;//转换为网络可以解析图片格式
cv::resize(plateROI, blob_image, cv::Size(w, h));//转换大小
unsigned char* data = static_cast<unsigned char*>(input1->buffer());//这就是直接将数据转换后填充到input那指定空间里面去了
//注意;opencv返回的mat图像的顺序是HWC 要将他转换为 NCHW 就是要将HWC类型的矩阵转换为NCHW类型 就是矩阵填充的问题
// HWC =》NCHW 转换
for (size_t row = 0; row < h; row++) {
for (size_t col = 0; col < w; col++) {
for (size_t ch = 0; ch < num_channels; ch++) {
//blob_image 是opencv过来的HWC格式 -》 转换为NCHW就是每一个通道变成一张图 按照通道顺序来的。第几个通道的就是第几张图的这种存放
data[image_size * ch + row * w + col] = blob_image.atcv::Vec3b(row, col)[ch];
}
}
}
auto input2 = plate_request.GetBlob(plate_input_name2);
int max_sequence = input2->getTensorDesc().getDims()[0];//第二个输入的第一维是序列的长度
float* blob2 = input2->buffer().as<float*>();
blob2[0] = 0.0f;
std::fill(blob2 + 1, blob2 + max_sequence, 1.0f);
//执行推理
plate_request.Infer();
//输出结果
auto output = plate_request.GetBlob(plate_output_name);
const float* plate_data = static_cast<PrecisionTrait<Precision::FP32>::value_type*>(output->buffer());//检测的输出结果
std::string result;
for (int i = 0; i < max_sequence; i++)
{
if (plate_data[i] == -1)
break;
result += items[std::size_t(plate_data[i])];
}
cv::putText(image, result.c_str(), cv::Point(50, 50), cv::FONT_HERSHEY_SIMPLEX, 1.0, cv::Scalar(0, 0, 255), 2, 8);
}
### 3、行人检测
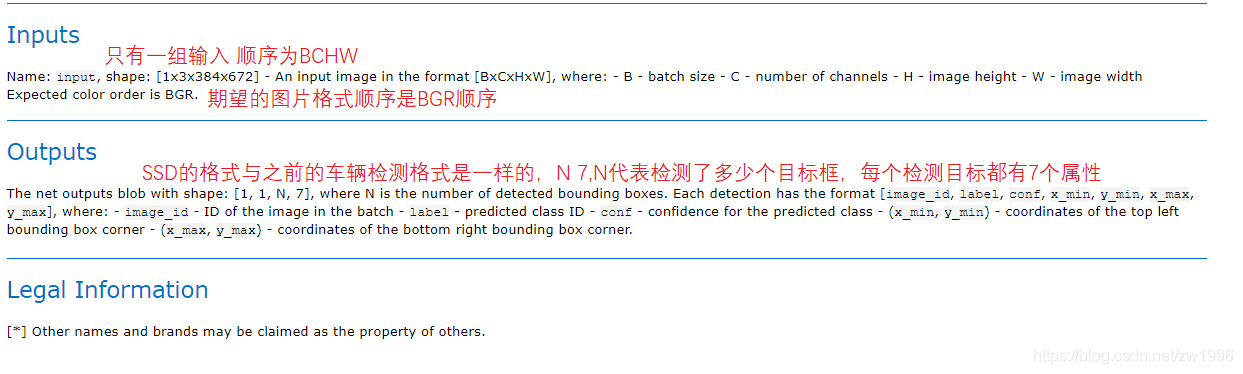
### 3.1、模型介绍


>
> 图 19 20 21
>
>
>
### 3.2、程序执行流程
因为都是SSD模型并且与车辆检测模型的输入输出格式一致都是BCHW的输入,1 1 N 7格式的输出,因此可以直接将车辆检测的整体代码直接拿过来用,只需要改一下模型路径即可。
### 3.3、程序演示部分
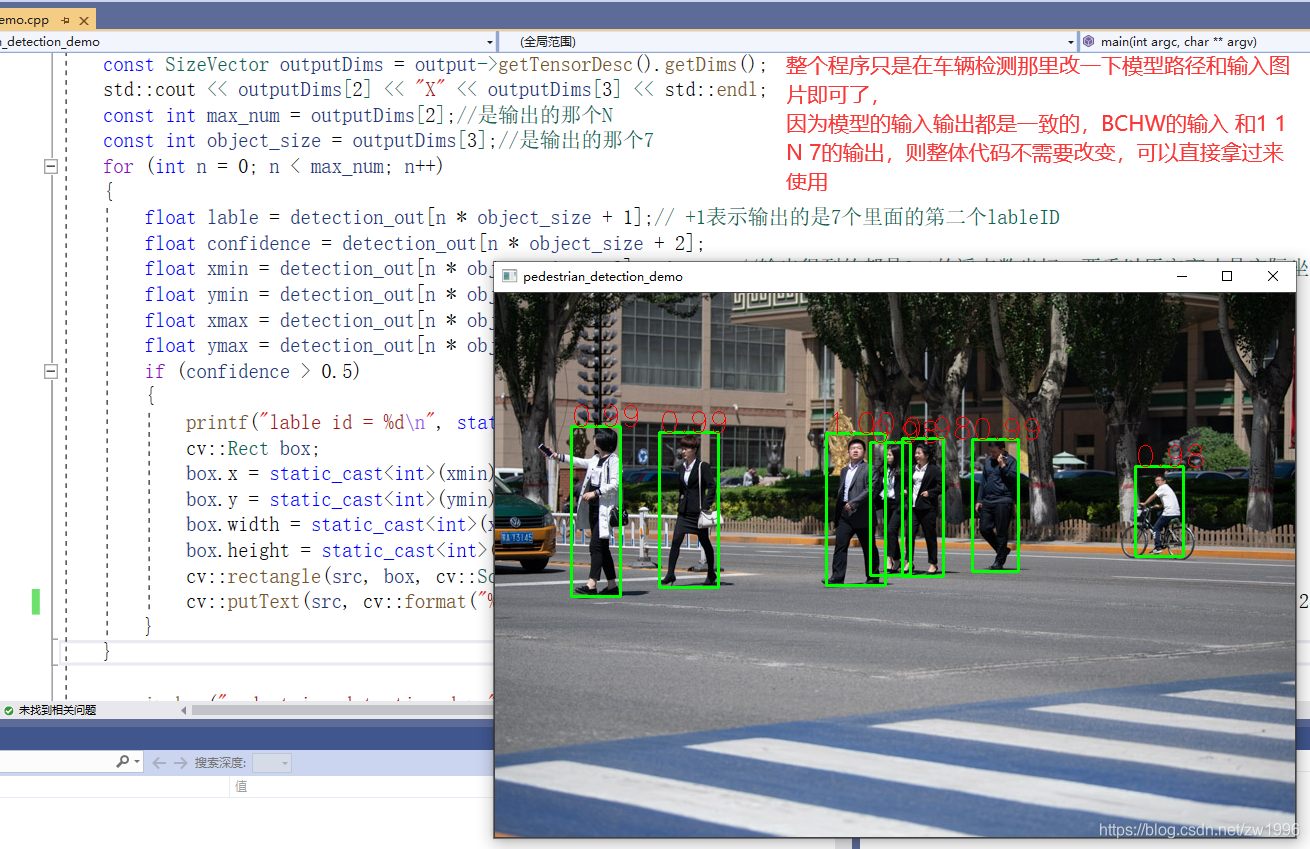
>
> 图22
>
>
>
### 3.4、视频当中的行人检测
代码流程差不多,只是将推理部分抽出成一个函数,通过传参的方式传入的,输入改为读取视频每帧都进行图像推理之后再显示。
可以看出对视频使用openVINO模型检测。对于速度方面是没有什么影响的,对于这个宽高不是很大的视频而言。openVINO模型对视频处理都是有每秒上百帧的效果的,也可以指定openVINO使用模型之后对模型也有很显著的加速效果的。
实践效果
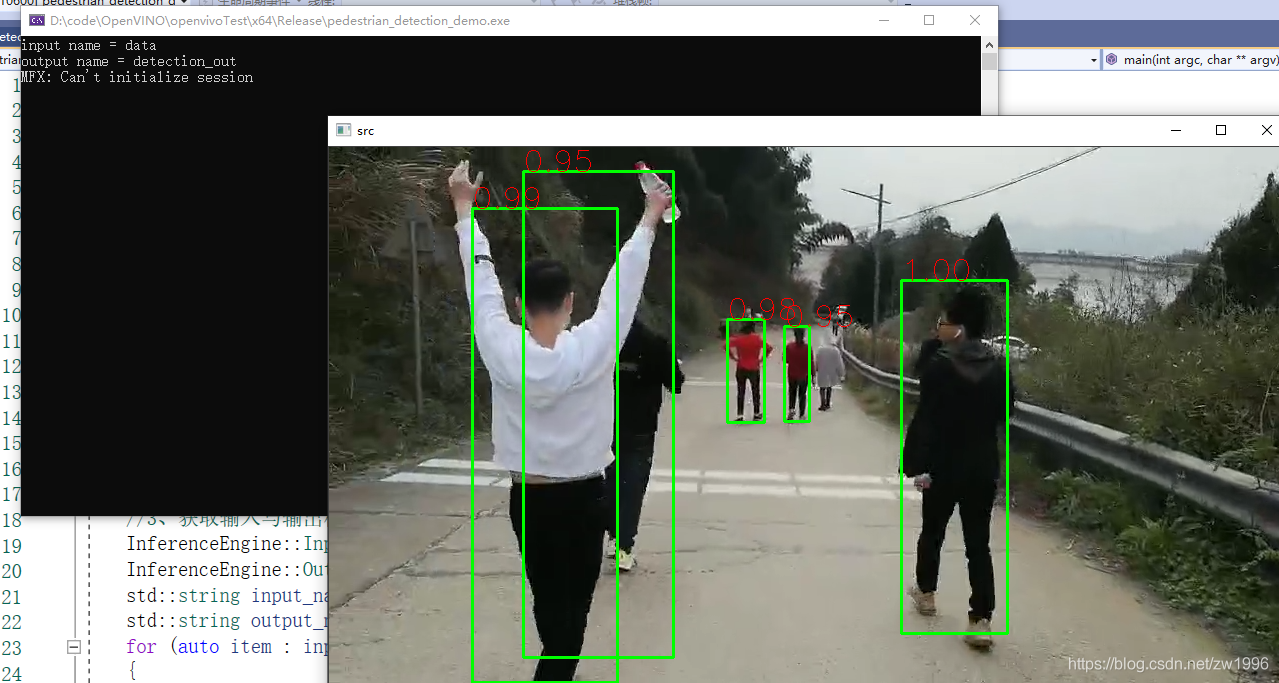
>
> 图23
>
>
>
代码实践
#include “inference_engine.hpp”
#include “opencv2/opencv.hpp”
#include
using namespace InferenceEngine;
void infer_process(cv::Mat &src, InferenceEngine::InferRequest & infer_request, std::string& input_name, std::string& output_name);
//图像行人检测
int main(int argc, char** argv)
{
//1、初始化Core ie
InferenceEngine::Core ie;//IE的核心类 其实就是IE
//2、ie.ReadNetwork 读取CNN网络 需要模型里面的两个文件 resnet18.bin resnet18.xml
std::string xmlFilename = "D:/code/OpenVINO/pedestrian-detection-adas-0002/FP32/pedestrian-detection-adas-0002.xml";
std::string binFilename = "D:/code/OpenVINO/pedestrian-detection-adas-0002/FP32/pedestrian-detection-adas-0002.bin";
InferenceEngine::CNNNetwork network = ie.ReadNetwork(xmlFilename, binFilename);//读取到加载CNN网络就会自动解析网络结构然后就可以获取输入输出了
//3、获取输入与输出格式并设置精度
InferenceEngine::InputsDataMap inputs = network.getInputsInfo();//InputsDataMap本质是一个vector的数组,如果你有多个输入的话则对应每个
InferenceEngine::OutputsDataMap outputs = network.getOutputsInfo();
std::string input_name = "";
std::string output_name = "";
for (auto item : inputs)
{
input_name = item.first;
auto input_data = item.second;//是一个数据结构 暂采用C++11的auto自动推断 因为只有一个输入则暂时这样定义在里面设置它的精度
input_data->setPrecision(Precision::U8);//输入图片数据格式为unsigned char 就是8位的精度
//这个也是根据模型设置的输入数据模式
input_data->setLayout(Layout::NCHW);
//也是根据模型设置输入的ColorFormat
input_data->getPreProcess().setColorFormat(ColorFormat::BGR);//该模型规定输入图片为BGR
std::cout << "input name = " << input_name << std::endl;
}
for (auto item : outputs)
{
output_name = item.first;
auto output_data = item.second;//是一个数据结构 暂采用C++11的auto自动推断 因为只有一个输入则暂时这样定义在里面设置它的精度
output_data->setPrecision(Precision::FP32);//输出还是浮点数输出的
std::cout << "output name = " << output_name << std::endl;
}
//4、获取可执行网络并链接硬件
auto executable_network = ie.LoadNetwork(network, "CPU");//会加载网络到CPU这个硬件,也可以设置成GPU
//5、创建推理请求 创建之后就可以尝试进行推理了,但是实际在推理之前还有很多事情要做,如格式设置
auto infer_request = executable_network.CreateInferRequest();
//6、创建视频流/加载视频文件
cv::VideoCapture capture("D:/padestrian_detection.mp4");
cv::Mat src;
while (true)
{
bool ret = capture.read(src);
if (ret == false)
break;
//7、循环执行推理
infer_process(src, infer_request, input_name, output_name);
cv::imshow("src", src);
char c = cv::waitKey(1);
if (c == 27)//按下esc
break;
}
//cv::imshow("pedestrian_detection_demo", src);
cv::waitKey(0);
return 0;
}
void infer_process(cv::Mat& src, InferenceEngine::InferRequest& infer_request, std::string& input_name, std::string& output_name)
{
//1、通过传入的推理引擎;获取输入的Blob 格式转换类对象
auto input = infer_request.GetBlob(input_name);//获取input的Blob(进行输入的格式设置的类对象)
size_t num_channels = input->getTensorDesc().getDims()[1];
size_t h = input->getTensorDesc().getDims()[2];
size_t w = input->getTensorDesc().getDims()[3];
size_t image_size = h * w;
//2、对输入图像转换
int im_h = src.rows;
int im_w = src.cols;
cv::Mat blob_image;//转换为网络可以解析图片格式
cv::resize(src, blob_image, cv::Size(w, h));//转换大小
//3、将设置好的数据设置到输入的Blob中 -> 实际上GetBlob()的时候就已经开辟好了存储输入图像数据内存空间
unsigned char* data = static_cast<unsigned char*>(input->buffer());//这就是直接将数据转换后填充到input那指定空间里面去了
//注意;opencv返回的mat图像的顺序是HWC 要将他转换为 NCHW 就是要将HWC类型的矩阵转换为NCHW类型 就是矩阵填充的问题
// HWC =》NCHW 转换
for (size_t row = 0; row < h; row++) {
for (size_t col = 0; col < w; col++) {
for (size_t ch = 0; ch < num_channels; ch++) {
//blob_image 是opencv过来的HWC格式 -》 转换为NCHW就是每一个通道变成一张图 按照通道顺序来的。第几个通道的就是第几张图的这种存放
data[image_size * ch + row * w + col] = blob_image.at<cv::Vec3b>(row, col)[ch];
}
}
}
//4、执行推理
infer_request.Infer();
//5、获取我们的output
auto output = infer_request.GetBlob(output_name);
const float* detection_out = static_cast<PrecisionTrait<Precision::FP32>::value_type*>(output->buffer());//检测的输出结果
//6、最后需要获取输出的维度信息 解析数据
const SizeVector outputDims = output->getTensorDesc().getDims();
//std::cout << outputDims[2] << "X" << outputDims[3] << std::endl;
const int max_num = outputDims[2];//是输出的那个N
const int object_size = outputDims[3];//是输出的那个7
for (int n = 0; n < max_num; n++)
{
float lable = detection_out[n * object_size + 1];// +1表示输出的是7个里面的第二个lableID
float confidence = detection_out[n * object_size + 2];
float xmin = detection_out[n * object_size + 3] * im_w; //输出得到的都是0-1的浮点数坐标 要乘以原宽高才是实际坐标
float ymin = detection_out[n * object_size + 4] * im_h;
float xmax = detection_out[n * object_size + 5] * im_w;
float ymax = detection_out[n * object_size + 6] * im_h;
if (confidence > 0.5)
{
//printf("lable id = %d\n", static_cast<int>(lable));
cv::Rect box;
box.x = static_cast<int>(xmin);
box.y = static_cast<int>(ymin);
box.width = static_cast<int>(xmax - xmin);
box.height = static_cast<int>(ymax - ymin);
cv::rectangle(src, box, cv::Scalar(0, 255, 0), 2, 8, 0);
cv::putText(src, cv::format("%.2f", confidence), box.tl(), cv::FONT_HERSHEY_SIMPLEX, 1.0, cv::Scalar(0, 0, 255), 1, 8);
}
}
}
### 4、实时人脸检测之异步推理
### 4.1、模型介绍
在OpenVINO当中自带了一系列的人脸检测的轻量级模型,多数都是可以达到100或更高的fps,所以说可以更适合部署在边缘端侧设备上的。

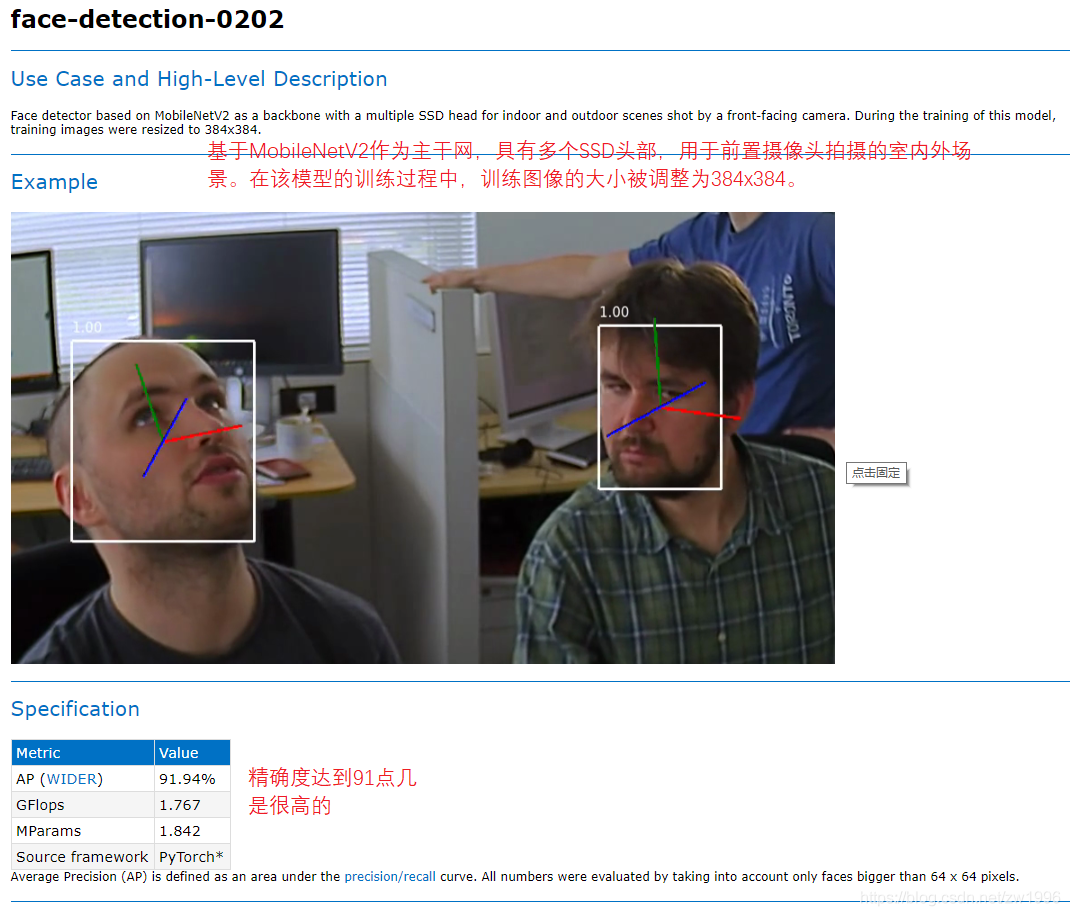

>
> 图24,25,26
>
>
>
可以与OpenCV做一个对比,opencv都是一个个算法都是传统模块,而OpenVINO了也是一个个算法所不同的是这里的一个个算法都是基于深度学习的模块,所提供的一个个模型,你根据这个模型去围绕开展就可以得到不同的算法表现
### 4.2、同步/异步执行
之前的模型实践都是使用的infer\_request.Infer()都是同步的模型,而异步的是有所差异的,
### 4.3、代码演示
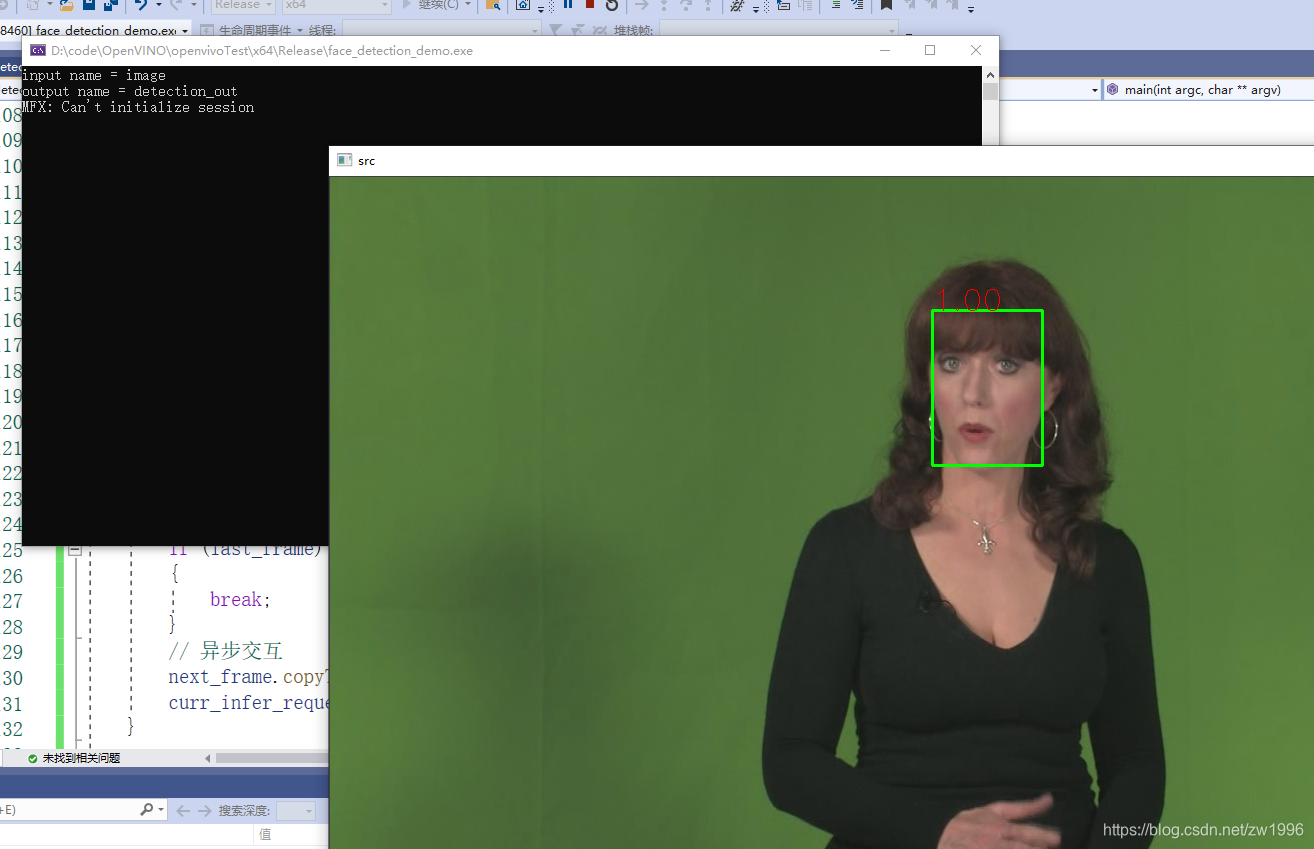
>
> 图30
>
>
>
同步实现
异步实现
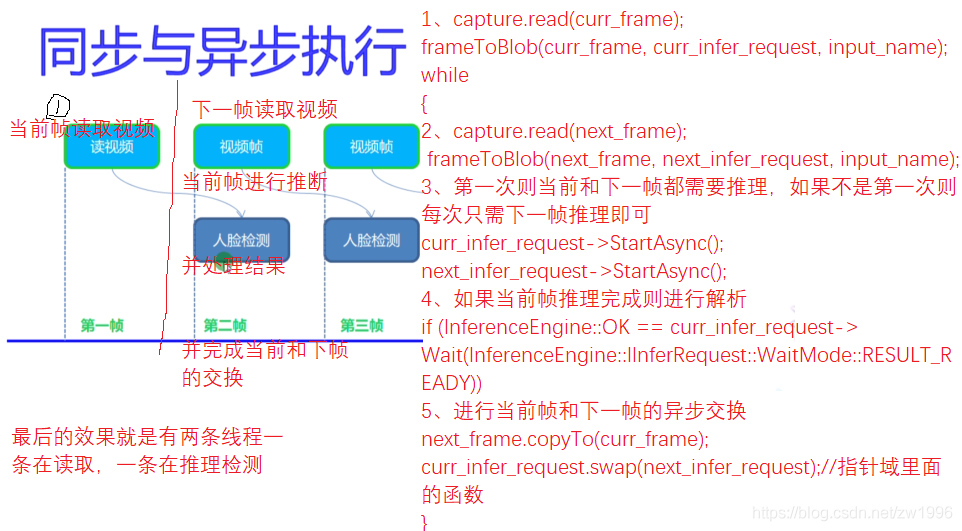
>
> 图27
>
>
>
代码实践
#include “inference_engine.hpp”
#include “opencv2/opencv.hpp”
#include
using namespace InferenceEngine;
//将mat过来的数据U8类型的 转为Blob,因为Blob是任意类型的因此也声明为模板、
template void matU8ToBlob(const cv::Mat& orig_image, InferenceEngine::Blob::Ptr& blob, int batchIndex = 0)
{
InferenceEngine::SizeVector blobSize = blob->getTensorDesc().getDims();
const size_t width = blobSize[3];
const size_t height = blobSize[2];
const size_t channels = blobSize[1];
InferenceEngine::MemoryBlob::Ptr mblob = InferenceEngine::asInferenceEngine::MemoryBlob(blob);
if (!mblob) {
THROW_IE_EXCEPTION << "We expect blob to be inherited from MemoryBlob in matU8ToBlob, "
<< “but by fact we were not able to cast inputBlob to MemoryBlob”;
}
// locked memory holder should be alive all time while access to its buffer happens
auto mblobHolder = mblob->wmap();
T* blob_data = mblobHolder.as<T*>();
cv::Mat resized_image(orig_image);
if (static_cast<int>(width) != orig_image.size().width ||
static_cast<int>(height) != orig_image.size().height) {
cv::resize(orig_image, resized_image, cv::Size(width, height));
}
int batchOffset = batchIndex * width * height * channels;
for (size_t c = 0; c < channels; c++) {
for (size_t h = 0; h < height; h++) {
for (size_t w = 0; w < width; w++) {
blob_data[batchOffset + c * width * height + h * width + w] =
resized_image.at<cv::Vec3b>(h, w)[c];
}
}
}
}
void infer_process(cv::Mat& src, std::shared_ptrInferenceEngine::InferRequest& infer_request, std::string& output_name);
void frameToBlob(cv::Mat& src, std::shared_ptrInferenceEngine::InferRequest& infer_request, std::string& input_name);
int main(int argc, char** argv)
{
//1、初始化Core ie
InferenceEngine::Core ie;//IE的核心类 其实就是IE
//2、ie.ReadNetwork 读取CNN网络 需要模型里面的两个文件 resnet18.bin resnet18.xml
std::string xmlFilename = "D:/code/OpenVINO/face-detection-0202/FP32/face-detection-0202.xml";
std::string binFilename = "D:/code/OpenVINO/face-detection-0202/FP32/face-detection-0202.bin";
InferenceEngine::CNNNetwork network = ie.ReadNetwork(xmlFilename, 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









