







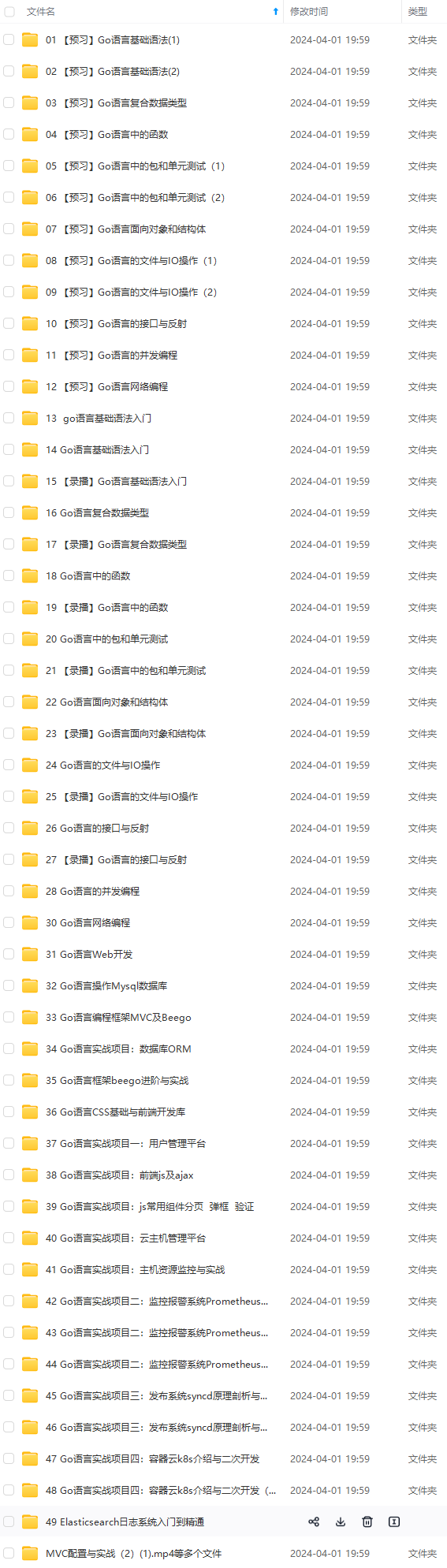
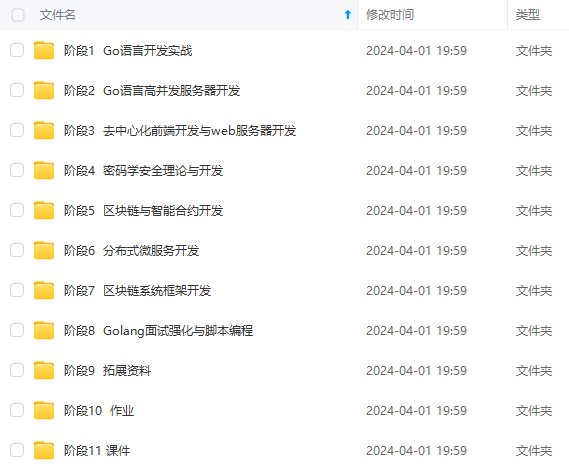
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
- 凸优化的概念:
 为一凸集,
为一凸集,  为一凸函数。凸优化就是要找出一点
为一凸函数。凸优化就是要找出一点 ,使得每一
,使得每一  满足
满足 。
。 - KKT条件的意义:它是一个非线性规划(Nonlinear Programming)问题能有最优化解法的必要和充分条件。
而KKT条件就是指上面最优化数学模型的标准形式中的最小点 x* 必须满足下面的条件:

经过论证,我们这里的问题是满足 KKT 条件的(首先已经满足Slater条件,再者f和gi也都是可微的,即L对w和b都可导),因此现在我们便转化为求解第二个问题。
也就是说,原始问题通过满足KKT条件,已经转化成了对偶问题。而求解这个对偶学习问题,分为3个步骤:首先要让L(w,b,a) 关于 w 和 b 最小化,然后求对 的极大,最后利用SMO算法求解对偶问题中的拉格朗日乘子。
的极大,最后利用SMO算法求解对偶问题中的拉格朗日乘子。
2.1.3、对偶问题求解的3个步骤
(1)、首先固定*,*要让 L 关于 w 和 b 最小化,我们分别对w,b求偏导数,即令 ∂L/∂w 和 ∂L/∂b 等于零(对w求导结果的解释请看本文评论下第45楼回复):

将以上结果代入之前的L:

得到:

提醒:有读者可能会问上述推导过程如何而来?说实话,其具体推导过程是比较复杂的,如下图所示:
最后,得到:
如 jerrylead所说:“倒数第4步”推导到“倒数第3步”使用了线性代数的转置运算,由于ai和yi都是实数,因此转置后与自身一样。“倒数第3步”推导到“倒数第2步”使用了(a+b+c+…)(a+b+c+…)=aa+ab+ac+ba+bb+bc+…的乘法运算法则。最后一步是上一步的顺序调整。
从上面的最后一个式子,我们可以看出,此时的拉格朗日函数只包含了一个变量,那就是 (求出了便能求出w,和b,由此可见,上文第1.2节提出来的核心问题:分类函数**
(求出了便能求出w,和b,由此可见,上文第1.2节提出来的核心问题:分类函数** **也就可以轻而易举的求出来了)。
**也就可以轻而易举的求出来了)。
(2)、求对*的极大,*即是关于对偶问题的最优化问题。经过上面第一个步骤的求w和b,得到的拉格朗日函数式子已经没有了变量w,b,只有。从上面的式子得到:

这样,求出了,根据 ,即可求出w,然后通过
,即可求出w,然后通过 ,即可求出b,最终得出分离超平面和分类决策函数。
,即可求出b,最终得出分离超平面和分类决策函数。
**(3)**在求得L(w, b, a) 关于 w 和 b 最小化,以及对的极大之后,最后一步则可以利用SMO算法求解对偶问题中的拉格朗日乘子。

上述式子要解决的是在参数 上求最大值W的问题,至于
上求最大值W的问题,至于 和
和 都是已知数。要了解这个SMO算法是如何推导的,请跳到下文第3.5节、SMO算法。
都是已知数。要了解这个SMO算法是如何推导的,请跳到下文第3.5节、SMO算法。
到目前为止,我们的 SVM 还比较弱,只能处理线性的情况,下面我们将引入核函数,进而推广到非线性分类问题。
2.1.4、线性不可分的情况
OK,为过渡到下节2.2节所介绍的核函数,让我们再来看看上述推导过程中得到的一些有趣的形式。首先就是关于我们的 hyper plane ,对于一个数据点 x 进行分类,实际上是通过把 x 带入到算出结果然后根据其正负号来进行类别划分的。而前面的推导中我们得到

因此分类函数为:

这里的形式的有趣之处在于,对于新点 x的预测,只需要计算它与训练数据点的内积即可( 表示向量内积),这一点至关重要,是之后使用 Kernel 进行非线性推广的基本前提。此外,所谓 Supporting Vector 也在这里显示出来——事实上,所有非Supporting Vector 所对应的系数
表示向量内积),这一点至关重要,是之后使用 Kernel 进行非线性推广的基本前提。此外,所谓 Supporting Vector 也在这里显示出来——事实上,所有非Supporting Vector 所对应的系数 都是等于零的,因此对于新点的内积计算实际上只要针对少量的“支持向量”而不是所有的训练数据即可。
都是等于零的,因此对于新点的内积计算实际上只要针对少量的“支持向量”而不是所有的训练数据即可。
为什么非支持向量对应的等于零呢?直观上来理解的话,就是这些“后方”的点——正如我们之前分析过的一样,对超平面是没有影响的,由于分类完全有超平面决定,所以这些无关的点并不会参与分类问题的计算,因而也就不会产生任何影响了。
回忆一下我们2.1.1节中通过 Lagrange multiplier得到的目标函数:

注意到如果 x**i 是支持向量的话,上式中红颜色的部分是等于 0 的(因为支持向量的 functional margin 等于 1 ),而对于非支持向量来说,functional margin 会大于 1 ,因此红颜色部分是大于零的,而 又是非负的,为了满足最大化,必须等于 0 。这也就是这些非Supporting Vector 的点的局限性。
又是非负的,为了满足最大化,必须等于 0 。这也就是这些非Supporting Vector 的点的局限性。
至此,我们便得到了一个maximum margin hyper plane classifier,这就是所谓的支持向量机(Support Vector Machine)。当然,到目前为止,我们的 SVM 还比较弱,只能处理线性的情况,不过,在得到了对偶dual 形式之后,通过Kernel 推广到非线性的情况就变成了一件非常容易的事情了(相信,你还记得本节开头所说的:“通过求解对偶问题得到最优解,这就是线性可分条件下支持向量机的对偶算法,这样做的优点在于:一者对偶问题往往更容易求解;二者可以自然的引入核函数,进而推广到非线性分类问题”)。
2.2、核函数Kernel
2.2.1、特征空间的隐式映射:核函数
事实上,大部分时候数据并不是线性可分的,这个时候满足这样条件的超平面就根本不存在。在上文中,我们已经了解到了SVM处理线性可分的情况,那对于非线性的数据SVM咋处理呢?对于非线性的情况,SVM 的处理方法是选择一个核函数 κ(⋅,⋅) ,通过将数据映射到高维空间,来解决在原始空间中线性不可分的问题。
具体来说,在线性不可分的情况下,支持向量机首先在低维空间中完成计算,然后通过核函数将输入空间映射到高维特征空间,最终在高维特征空间中构造出最优分离超平面,从而把平面上本身不好分的非线性数据分开。如图所示,一堆数据在二维空间无法划分,从而映射到三维空间里划分:

而在我们遇到核函数之前,如果用原始的方法,那么在用线性学习器学习一个非线性关系,需要选择一个非线性特征集,并且将数据写成新的表达形式,这等价于应用一个固定的非线性映射,将数据映射到特征空间,在特征空间中使用线性学习器,因此,考虑的假设集是这种类型的函数:

这里ϕ:X->F是从输入空间到某个特征空间的映射,这意味着建立非线性学习器分为两步:
- 首先使用一个非线性映射将数据变换到一个特征空间F,
- 然后在特征空间使用线性学习器分类。
而由于对偶形式就是线性学习器的一个重要性质,这意味着假设可以表达为训练点的线性组合,因此决策规则可以用测试点和训练点的内积来表示:

如果有一种方式可以在特征空间中直接计算内积〈φ(xi · φ(x)****〉,就像在原始输入点的函数中一样,就有可能将两个步骤融合到一起建立一个非线性的学习器,这样直接计算法的方法称为核函数方法:
核是一个函数K,对所有x,z(-X,满足 ,这里φ是从X到内积特征空间F的映射。
,这里φ是从X到内积特征空间F的映射。
2.2.2、核函数:如何处理非线性数据
来看个核函数的例子。如下图所示的两类数据,分别分布为两个圆圈的形状,这样的数据本身就是线性不可分的,此时咱们该如何把这两类数据分开呢(下文将会有一个相应的三维空间图)?

事实上,上图所述的这个数据集,是用两个半径不同的圆圈加上了少量的噪音生成得到的,所以,一个理想的分界应该是一个“圆圈”而不是一条线(超平面)。如果用 和
和 来表示这个二维平面的两个坐标的话,我们知道一条二次曲线(圆圈是二次曲线的一种特殊情况)的方程可以写作这样的形式:
来表示这个二维平面的两个坐标的话,我们知道一条二次曲线(圆圈是二次曲线的一种特殊情况)的方程可以写作这样的形式:

注意上面的形式,如果我们构造另外一个五维的空间,其中五个坐标的值分别为
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









