






既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上Go语言开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
for (int i = 0; i < 50000; i++) {
counter.add();
}
});
// 启动线程
t1.start();
t2.start();
// 等待两个线程结束
try {
t1.join();
t2.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
// 打印最终的 count 值
System.out.println("count = " + counter.count);
}
}
执行结果:
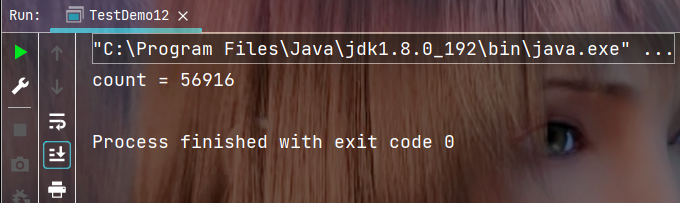
我们预期的结果应该时`10`万, 但得到得结果明显要比10万小很多, 你可以尝试将程序多运行几次你会发现程序每次运行的结果都不一样, 但绝大部分结果, 都会比预期值要小, 下面就来分析这种结出现的原因.
## 二. 线程不安全的原因和线程加锁
### 1. 案例分析
在上面, 我们使用多线程所写的程序将将一个初始值为0的变量自增`10`万次, 但得到的实际得到的结果要比预期的`10`万小, 万恶之源还是线程的抢占式执行, 线程调度的顺序是随机的, 就造成线程间自增的指令集交叉, 导致运行时出现两次或者多次自增但值只会自增一次的情况, 导致得到的结果会偏小.
一次的自增操作本质上可以分成三步:
1. 把内存中变量的值读取到CPU的寄存器中(`load`).
2. 在寄存器中执行自增操作(`add`)
3. 将寄存器的值保存至内存中(`save`)
如果是两个线程并发的执行`count++`, 此时就相当于两组 `load`, `add`, `save`进行执行, 此时不同的线程调度顺序就可能会产生一些结果上的差异.
下面的时间轴总结了一个变量由两个线程并发进行两次自增时, 常见几种常见的情况:
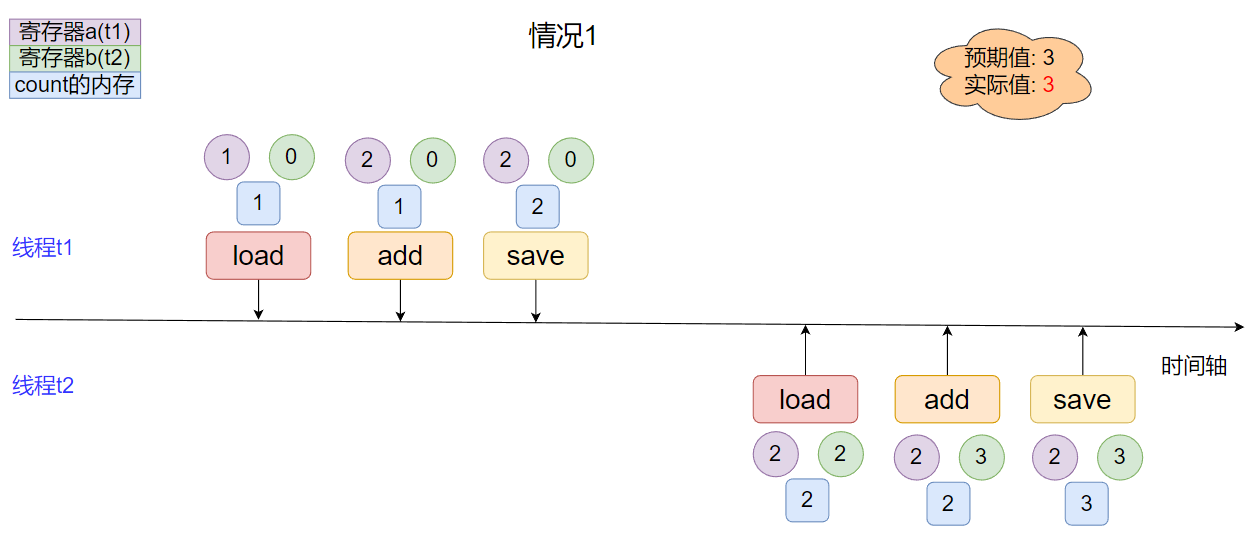
* **情况1**
线程间指令集无交叉, 实际结果和预期结果一致.
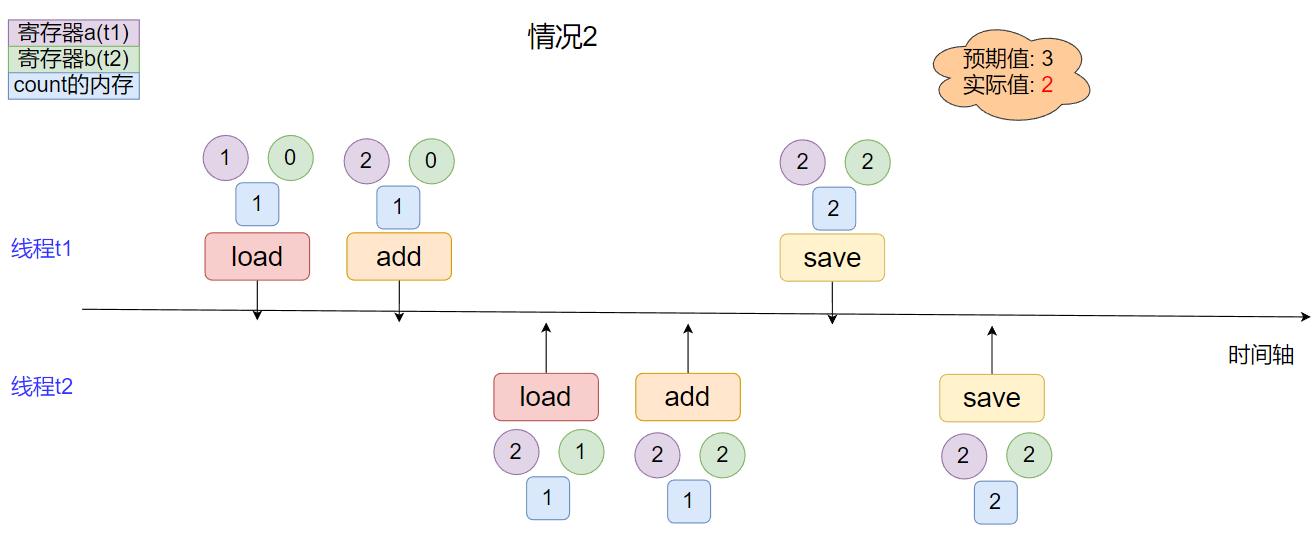
* **情况2**
线程间指令集存在交叉, 实际结果小于预期结果.
* 情况3
线程间指令集完全交叉, 实际结果小于预期结果.
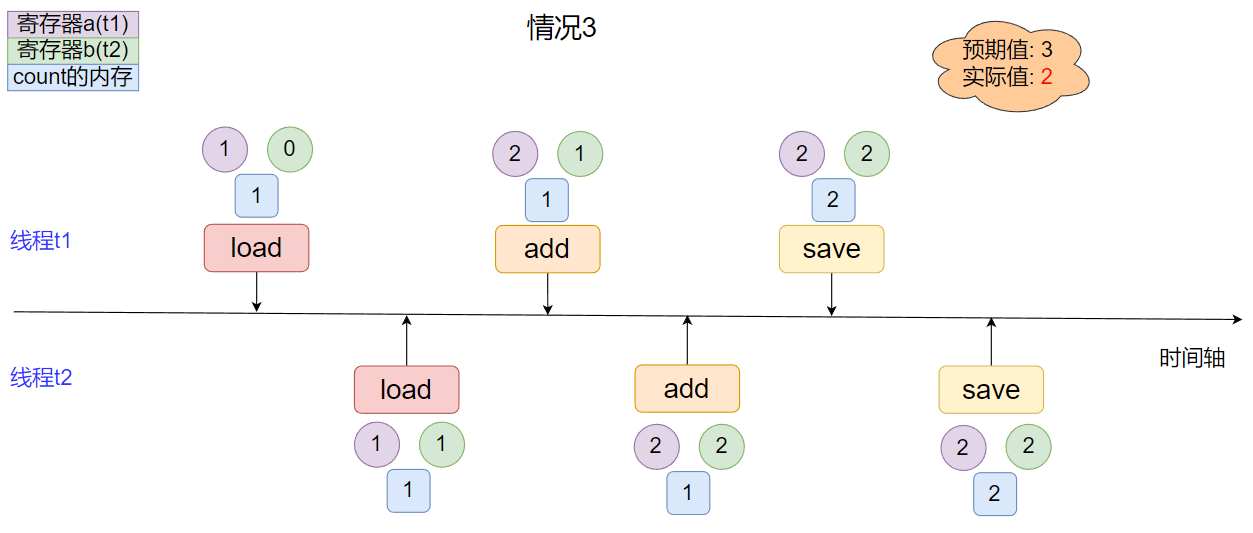
上面列举的三种情况并不是所有可能状况, 其他状况也类似, 可以自己尝试推导一下, 观察上面列出的情况情况, 我们不难发现出当多线程的指令集没有交叉情况出现的时侯, 程序就可以得到正确的结果; 而一旦指令集间有了交叉, 结果就可能会比预期的要小, 也就是说造成这里线程安全问题的原因在于这里的自增操作不是原子性的.
那么再观察上面有问题的结果, 思考结果一定是大于5万吗, 其实不一定, 只是这种可能性比较小, 当线程当t2自增两次或多次,t1只自增一次, 最后的效果是加1.
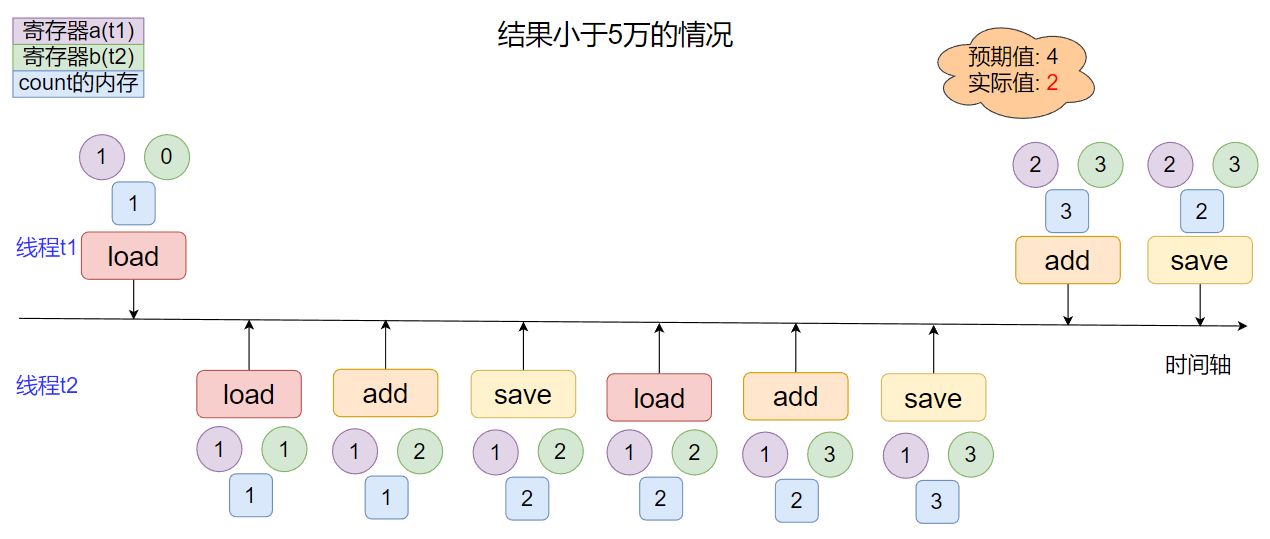
当然也有可能最后计算出来的结果是正确的, 不过再这种有问题的情况下可能就更小了, 但并不能说完全没有可能.
那么如何解决上面的线程安全问题呢, 我们只需要想办法让自增操作变成原子性的即可, 也就是让`load`, `add`, `save`三步编程一个整体, 也就是下面介绍的对对象加锁.
### 2. 线程加锁
#### 2.1 理解加锁
为了解决由于 “抢占式执行” 所导致的线程安全问题, 我们可以针对当前所操作的对象进行加锁, 当一个线程拿到该对象的锁后, 就会将该对象锁起来, 其他线程如果需要执行该对象所限制任务时, 需要等待该线程执行完该对象这里的任务后才可以.
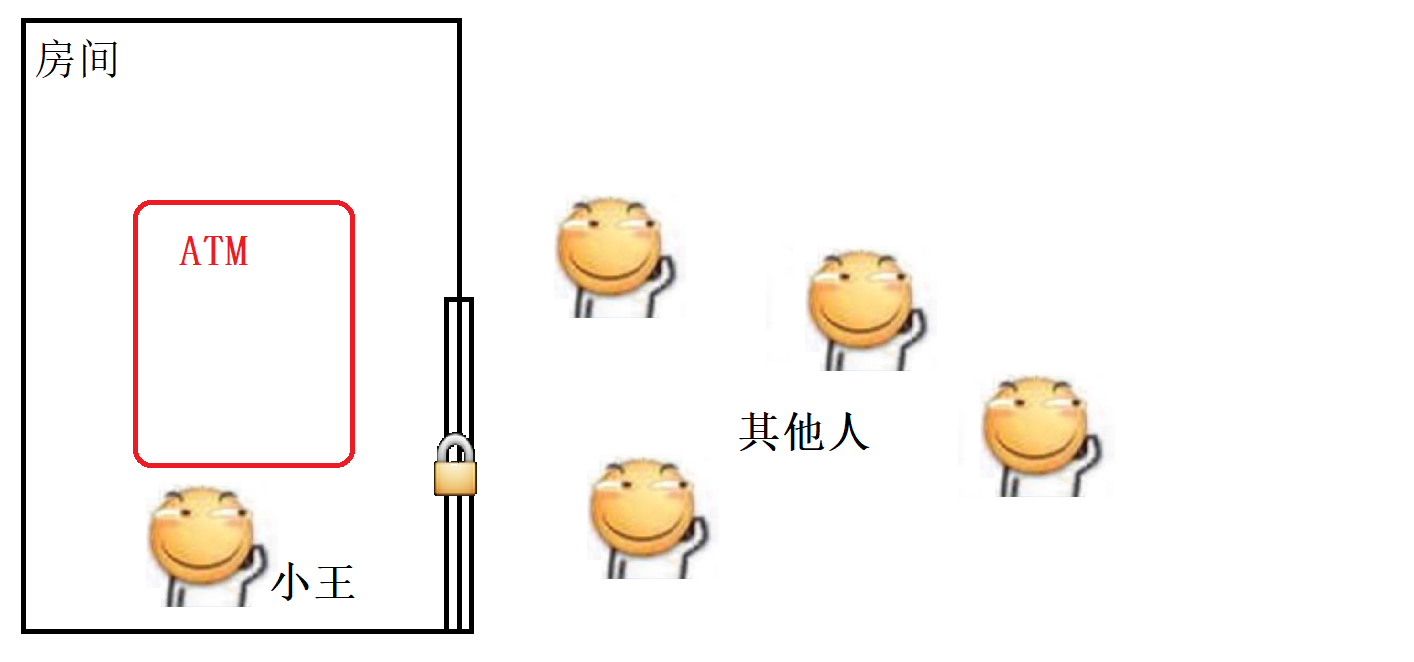
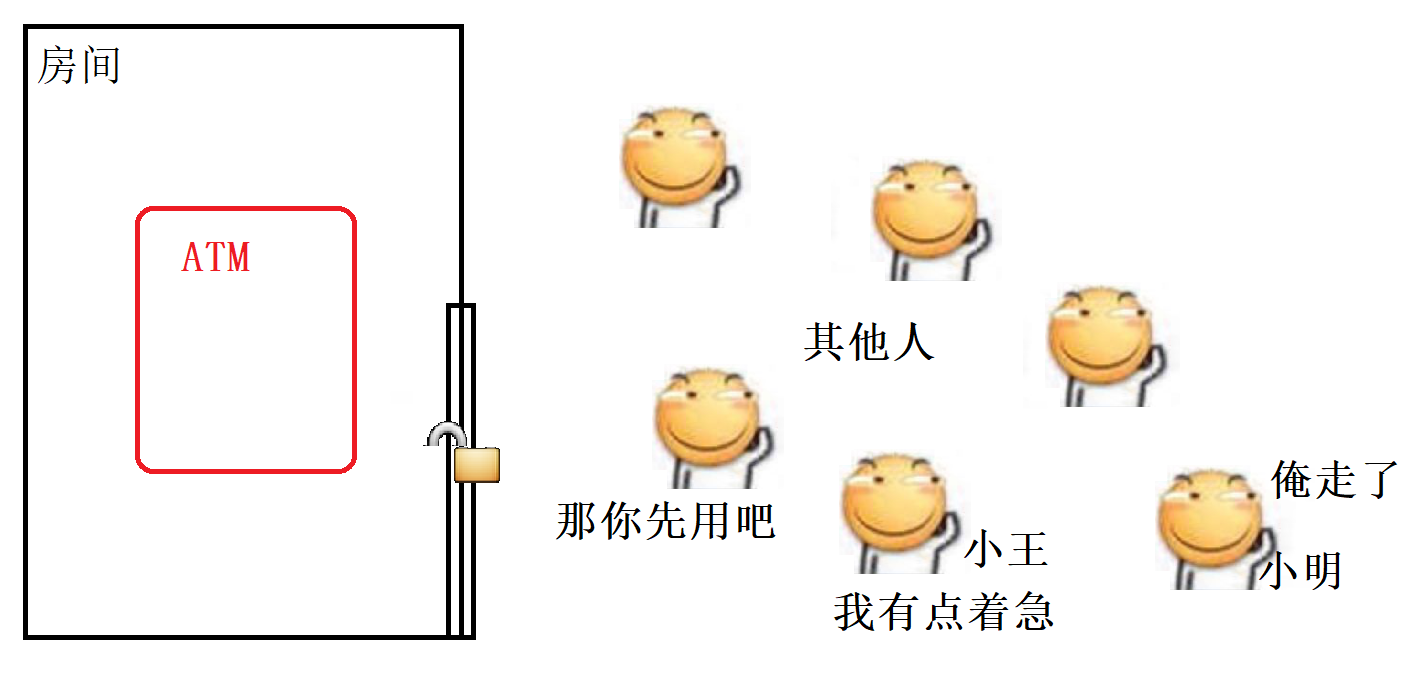
用现实生活中的例子来理解, 假设小明要去银行的ATM机子上办理业务, 我们知道为了安全, 每台ATM一般都在一个单独的小房间里面, 这个小房间由一扇门和一把锁, 当小明进入房间使用ATM时, 门就会自动锁上, 此时如果其他人想要使用这台ATM就得等小明使用完从房间里面出来才行, 那么这里的 “小明” 就相当于一个线程, ATM就相当于一个对象, 房间就相当于一把锁, 其他想使用这台ATM机子的人就相当于其他的线程.

在Java中最常用的加锁操作就是使用`synchronized`关键字进行加锁.
#### 2.2 synchronized的使用
`synchronized` 会起到互斥效果, 某个线程执行到某个对象的 `synchronized` 中时, 其他线程如果也执行到同一个对象 `synchronized` 就会阻塞等待.
线程进入 synchronized 修饰的代码块, 相当于`加锁`, 退出 synchronized 修饰的代码块, 相当于`解锁`.
* **使用方式1**
使用`synchronized`关键字修饰普通方法, 这样会给方法所对在的对象加上一把锁.
以上面的自增代码为例, 对`add()`方法和加锁, 实质上是个一个对象加锁, 在这里这个锁对象就是`this`.
class Counter {
public int count = 0;
synchronized public void add() {
count++;
}
}
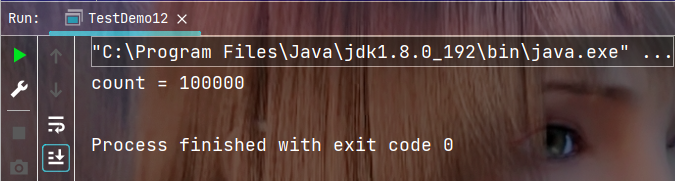
对代码做出如上修改后, 执行结果如下:
* **使用方式2**
使用`synchronized`关键字对代码段进行加锁, 需要显式指定加锁的对象.
还是基于最开始的代码进行修改, 如下:
class Counter {
public int count = 0;
public void add() {
synchronized (this) {
count++;
}
}
}
执行结果:

* **使用方式3**
使用`synchronized`关键字修饰静态方法, 相当于对当前类的类对象进行加锁.
class Counter {
public static int count = 0;
synchronized public static void add() {
count++;
}
}
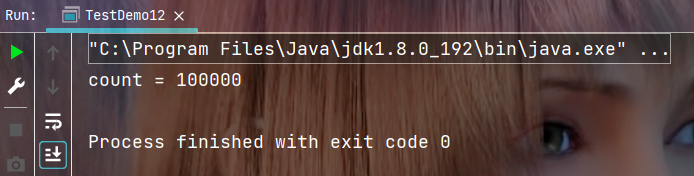
执行结果:
#### 2.3 再次分析案例
我们这里再来分析一下, 为什么上锁之后, 线程就安全了, 代码如下:
class Counter {
public int count = 0;
public void add() {
count++;
}
}
public class TestDemo12 {
public static void main(String[] args) {
Counter counter = new Counter();
// 搞两个线程, 两个线程分别针对 counter 来 调用 5w 次的 add 方法
Thread t1 = new Thread(() -> {
for (int i = 0; i < 50000; i++) {
counter.add();
}
});
Thread t2 = new Thread(() -> {
for (int i = 0; i < 50000; i++) {
counter.add();
}
});
// 启动线程
t1.start();
t2.start();
// 等待两个线程结束
try {
t1.join();
t2.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
// 打印最终的 count 值
System.out.println("count = " + counter.count);
}
}
加锁, 其实就是想要保证这里自增操作 load, add, save的原子性, 但这里上锁后并不是说让这三步一次完成, 也不是在执行这三步过程中其他线程不进行调度, 加锁后其实是让其他想操作的线程阻塞等待了.
比如我们考虑两个线程指令集交叉的情况下, 加锁操作是如何保证线程安全的, 不妨记加锁为`lock`,解锁为`unlock`, `t1和t2`两个线程的运行过程如下:
`t1`线程首先获取到目标对象的锁, 对对象进行了加锁, 处于`lock`状态, `t1`线程`load`操作之后, 此时`t2`线程来执行自增操作时会发生阻塞, 直到`t1`线程的自增操作执行完成后, 释放锁变为`unlock`状态, 线程才能成功获取到锁开始执行load操作… , 如果有两个以上的线程以此类推…

加锁本质上就是把并发变成了串行执行, 这样的话这里的自增操作其实和单线程是差不多的, 甚至上由于add方法, 要做的事情多了加锁和解锁的开销, 多线程完成自增可能比单线程的开销还要大, 那么多线程是不是就没用了呢? 其实不然, 对方法加锁后, 线程运行该方法才会加锁, 执行完该方法的操作后就会解锁, 此方法外的代码并没有受到限制, 这部分程序还是可以多线程并发执行的, 这样整体上多线程的执行效率还是要比单线程要高许多的.
注意:
* 加锁, 一定要明确是对哪个对象加的锁, 如果两个线程针对同一个对象加锁, 会产生阻塞等待(锁竞争/锁冲突); 而如果两个线程针对不同对象加锁, 不会产生锁冲突.
### 3. 线程不安全的原因
1. 最根本的原因: 抢占式执行, 随机调度, 这个原因我们无法解决.
2. 代码结构.
我们最初给出的代码之所以有线程安全的原因, 是因为我们设计的代码是让两个线程同时去修改一个相同的变量.
如果我们将代码设计成一个线程修改一个变量, 多个线程读取同一个变量, 多个线程修改多个不同的变量等, 这些情况下, 都是线程安全的; 所以我们可以通过调整代码结构来规避这个问题, 但代码结构是来源于需求的, 这种调整有时候不是一个普适性特别高的方案.
3. 原子性.
如果我们的多线程操作中修改操作是原子的, 那出问题的概率还比较小, 如果是非原子的, 出现问题的概率就非常高了, 就比如我们最开头写的程序以及上面的分析.
4. 指令重排序和内存可见性问题
主要是由于编译器优化造成的指令重排序和内存可见性无法保证, 就是当线程频繁地对同一个变量进行读取操作时, 一开始会读内存中的值, 到了后面可能就不会读取内存中的值了, 而是会直接从寄存器上读值, 这样如果内存中的值做出修改时, 线程就感知不到这个变量已经被修改, 就会导致线程安全问题, 归根结底这是编译器优化的结果, 编译器/jvm在多线程环境下产生了误判, 结合下面的代码进行理解:
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化的资料的朋友,可以添加戳这里获取](https://bbs.youkuaiyun.com/topics/618658159)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**
链图片转存中...(img-ZjlFa5mz-1715717142157)]
[外链图片转存中...(img-b0ZQA0YQ-1715717142158)]
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化的资料的朋友,可以添加戳这里获取](https://bbs.youkuaiyun.com/topics/618658159)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**

















 1938
1938

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









