







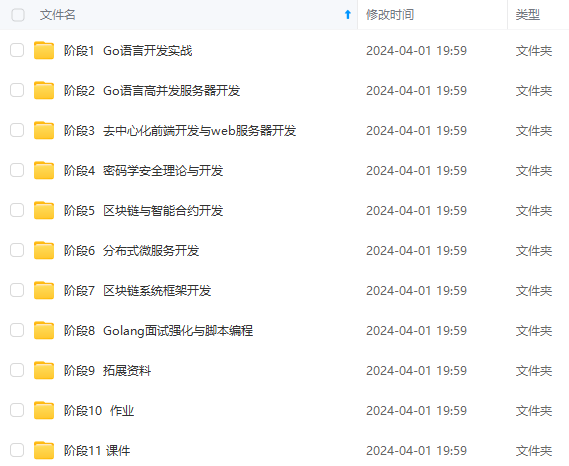
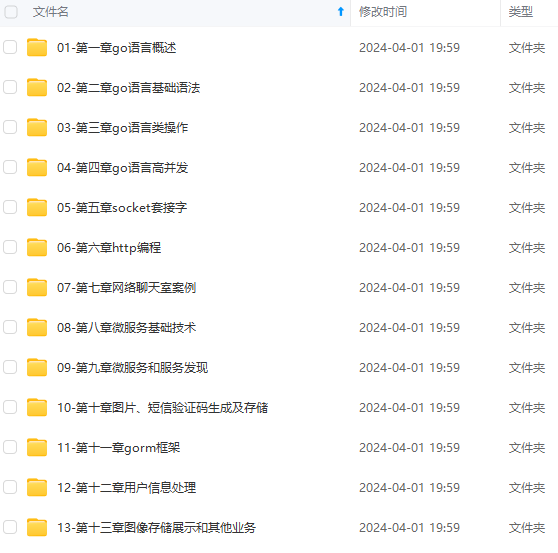
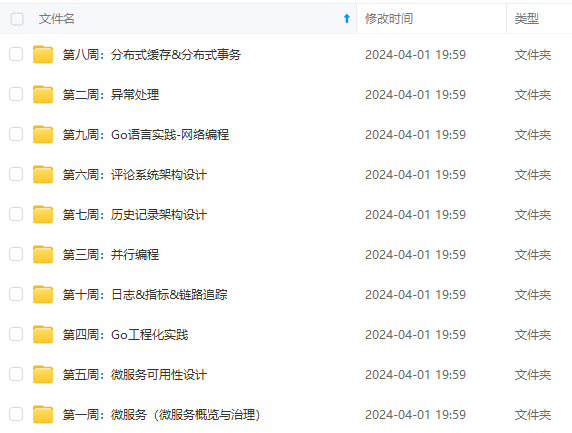
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上Go语言开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
一、snownlp简介
snownlp是什么?
SnowNLP是一个python写的类库,可以方便的处理中文文本内容,是受到了TextBlob的启发而写的,由于现在大部分的自然语言处理库基本都是针对英文的,于是写了一个方便处理中文的类库,并且和TextBlob不同的是,这里没有用NLTK,所有的算法都是自己实现的,并且自带了一些训练好的字典。注意本程序都是处理的unicode编码,所以使用时请自行decode成unicode。
以上是官方对snownlp的描述,简单地说,snownlp是一个中文的自然语言处理的Python库,支持的中文自然语言操作包括:
- 中文分词
- 词性标注
- 情感分析
- 文本分类
- 转换成拼音
- 繁体转简体
- 提取文本关键词
- 提取文本摘要
- tf,idf
- Tokenization
- 文本相似
在本文中,将重点介绍snownlp中的情感分析(Sentiment Analysis)。
二、snownlp情感分析模块的使用
2.1、snownlp库的安装
snownlp的安装方法如下:
pip install snownlp
2.2、使用snownlp情感分析
利用snownlp进行情感分析的代码如下所示:
#coding:UTF-8
import sys
from snownlp import SnowNLP
def read\_and\_analysis(input\_file, output\_file):
f = open(input_file)
fw = open(output_file, "w")
while True:
line = f.readline()
if not line:
break
lines = line.strip().split("\t")
if len(lines) < 2:
continue
s = SnowNLP(lines[1].decode('utf-8'))
# s.words 查询分词结果
seg_words = ""
for x in s.words:
seg_words += "\_"
seg_words += x
# s.sentiments 查询最终的情感分析的得分
fw.write(lines[0] + "\t" + lines[1] + "\t" + seg_words.encode('utf-8') + "\t" + str(s.sentiments) + "\n")
fw.close()
f.close()
if __name__ == "\_\_main\_\_":
input_file = sys.argv[1]
output_file = sys.argv[2]
read_and_analysis(input_file, output_file)
上述代码会从文件中读取每一行的文本,并对其进行情感分析并输出最终的结果。
注:库中已经训练好的模型是基于商品的评论数据,因此,在实际使用的过程中,需要根据自己的情况,重新训练模型。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









