







既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上Go语言开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
// 申请device内存
float *d_x, *d_y, *d_z;
cudaMalloc((void**)&d_x, nBytes);
cudaMalloc((void**)&d_y, nBytes);
cudaMalloc((void**)&d_z, nBytes);
// 将host数据拷贝到device
cudaMemcpy((void*)d_x, (void*)x, nBytes, cudaMemcpyHostToDevice);
cudaMemcpy((void*)d_y, (void*)y, nBytes, cudaMemcpyHostToDevice);
// 定义kernel的执行配置
dim3 blockSize(256);
dim3 gridSize((N + blockSize.x - 1) / blockSize.x);
// 执行kernel
add << < gridSize, blockSize >> >(d_x, d_y, d_z, N);
// 将device得到的结果拷贝到host
cudaMemcpy((void*)z, (void*)d_z, nBytes, cudaMemcpyDeviceToHost);
// 检查执行结果
float maxError = 0.0;
for (int i = 0; i < N; i++)
maxError = fmax(maxError, fabs(z[i] - 30.0));
std::cout << "最大误差: " << maxError << std::endl;
// 释放device内存
cudaFree(d_x);
cudaFree(d_y);
cudaFree(d_z);
// 释放host内存
free(x);
free(y);
free(z);
return 0;
}
这里我们的向量大小为1<<20,而block大小为256,那么grid大小是4096,kernel的线程层级结构如下图所示:
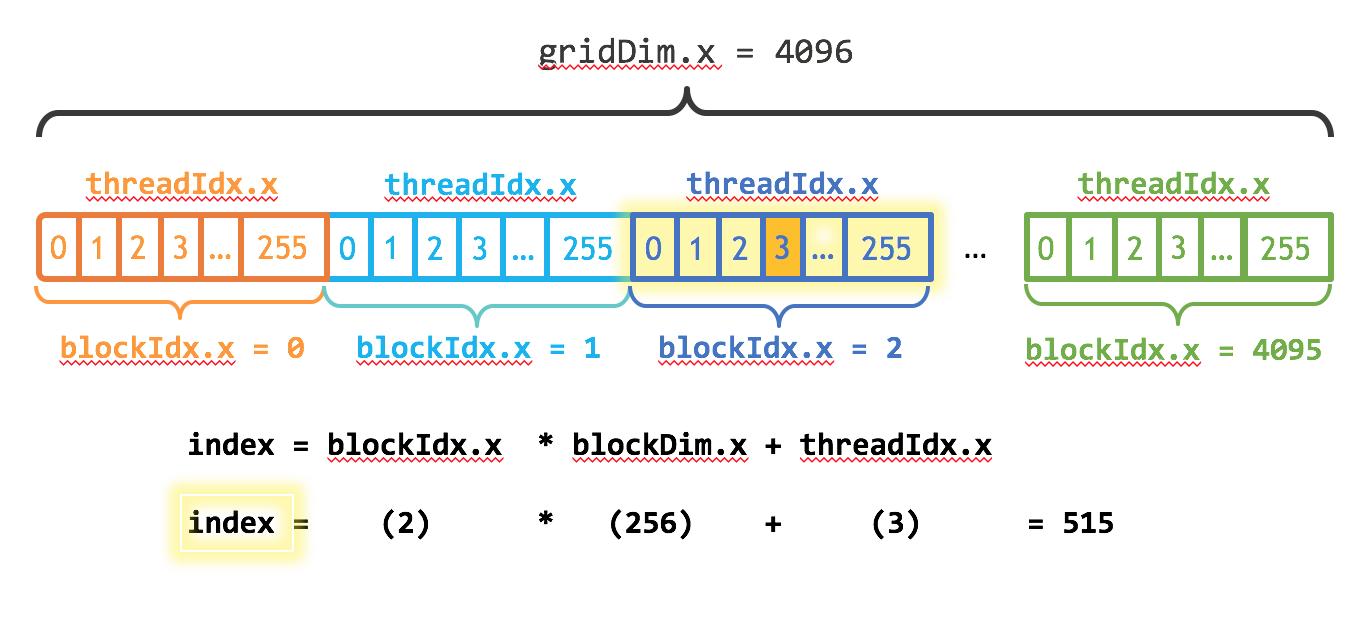
kernel的线程层次结构. 来源:https://devblogs.nvidia.com/even-easier-introduction-cuda/
使用nvprof工具可以分析kernel运行情况,结果如下所示,可以看到kernel函数费时约1.5ms。
nvprof cuda9.exe
7244 NVPROF is profiling process 7244, command: cuda9.exe
最大误差: 4.31602e+008
7244 Profiling application: cuda9.exe
7244 Profiling result:
Type Time(%) Time Calls Avg Min Max Name
GPU activities: 67.57% 3.2256ms 2 1.6128ms 1.6017ms 1.6239ms [CUDA memcpy HtoD]
32.43% 1.5478ms 1 1.5478ms 1.5478ms 1.5478ms add(float*, float*, float*, int)
你调整block的大小,对比不同配置下的kernel运行情况,我这里测试的是当block为128时,kernel费时约1.6ms,而block为512时kernel费时约1.7ms,当block为64时,kernel费时约2.3ms。看来不是block越大越好,而要适当选择。
在上面的实现中,我们需要单独在host和device上进行内存分配,并且要进行数据拷贝,这是很容易出错的。好在CUDA 6.0引入统一内存([Unified Memory]( ))来避免这种麻烦,简单来说就是统一内存使用一个托管内存来共同管理host和device中的内存,并且自动在host和device中进行数据传输。CUDA中使用cudaMallocManaged函数分配托管内存:
cudaError_t cudaMallocManaged(void **devPtr, size_t size, unsigned int flag=0);
利用统一内存,可以将上面的程序简化如下:
int main()
{
int N = 1 << 20;
int nBytes = N * sizeof(float);
// 申请托管内存
float *x, *y, *z;
cudaMallocManaged((void**)&x, nBytes);
cudaMallocManaged((void**)&y, nBytes);
cudaMallocManaged((void**)&z, nBytes);
// 初始化数据
for (int i = 0; i < N; ++i)
{
x[i] = 10.0;
y[i] = 20.0;
}
// 定义kernel的执行配置
dim3 blockSize(256);
dim3 gridSize((N + blockSize.x - 1) / blockSize.x);
// 执行kernel
add << < gridSize, blockSize >> >(x, y, z, N);
// 同步device 保证结果能正确访问
cudaDeviceSynchronize();
// 检查执行结果
float maxError = 0.0;
for (int i = 0; i < N; i++)
maxError = fmax(maxError, fabs(z[i] - 30.0));
std::cout << "最大误差: " << maxError << std::endl;
// 释放内存
cudaFree(x);
cudaFree(y);
cudaFree(z);
return 0;
}
相比之前的代码,使用统一内存更简洁了,值得注意的是kernel执行是与host异步的,由于托管内存自动进行数据传输,这里要用cudaDeviceSynchronize()函数保证device和host同步,这样后面才可以正确访问kernel计算的结果。
### 矩阵乘法实例
最后我们再实现一个稍微复杂一些的例子,就是两个矩阵的乘法,设输入矩阵为 AA 和 BB ,要得到 C=A×BC=A\times B 。实现思路是每个线程计算 CC 的一个元素值 Ci,jC\_{i,j} ,对于矩阵运算,应该选用grid和block为2-D的。首先定义矩阵的结构体:
// 矩阵类型,行优先,M(row, col) = *(M.elements + row * M.width + col)
struct Matrix
{
int width;
int height;
float *elements;
};
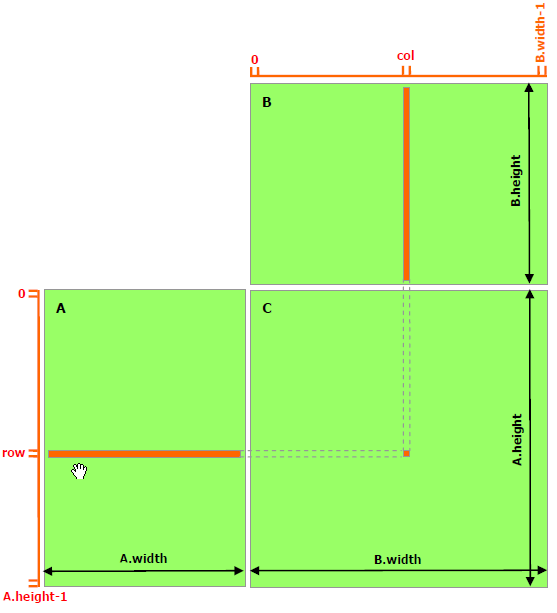
矩阵乘法实现模式
然后实现矩阵乘法的核函数,这里我们定义了两个辅助的`__device__`函数分别用于获取矩阵的元素值和为矩阵元素赋值,具体代码如下:
// 获取矩阵A的(row, col)元素
device f
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









