







深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
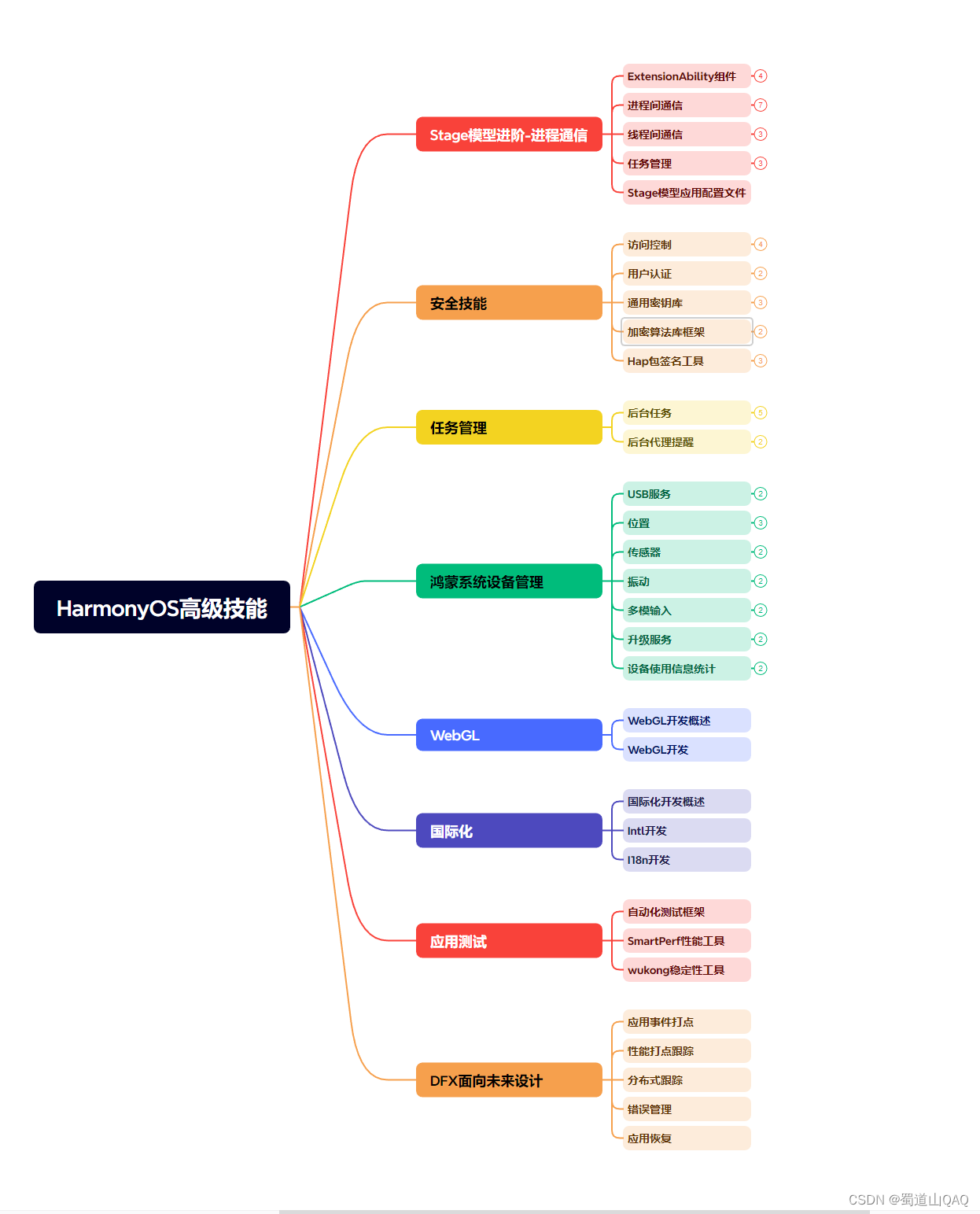

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上鸿蒙开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
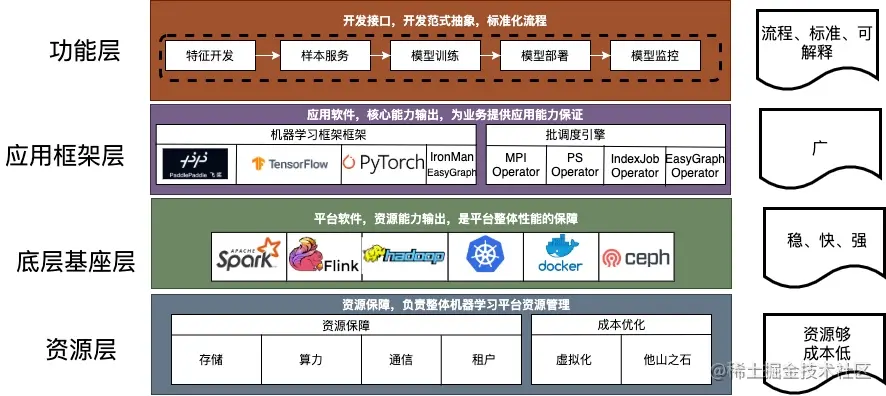
资源层:平台核心能力保障
主要为平台提供资源保障与成本优化的能力,资源保障覆盖了包括算力、存储、通信、租户等各个方面,而成本优化目前我们采用虚拟化,提供资源池的动态分配,另外考虑到某些业务突发性的大算力需求,资源层能够快速、有效地从其他团队、平台资源层调取到足够的资源提供给业务使用。本章以VK与阿里云ECI为例,简述云音乐机器学习平台在资源这块的工作:
Visual Kubelet资源
目前网易内部有很多资源属于不同的集群来管理,有很多的k8s集群, 杭研云计算团队开发kubeMiner网易跨kubernetes集群统一调度系统,能够动态接入其他闲置集群的资源使用。过去一段时间,云音乐机器学习平台和云计算合作,将大部分CPU分布式相关的如图计算、大规模离散和分布式训练,弹性调度至vk资源,在vk资源保障的同时,能够大大增加同时迭代模型的并行度,提升业务迭代效率; 平台使用VK资源可以简单地理解为外部集群被虚拟为k8s集群中的虚拟节点,并在外部集群变化时更新虚拟节点状态,这样就可以直接借助k8s自身的调度能力,支持Pod调度到外部集群的跨集群调度。
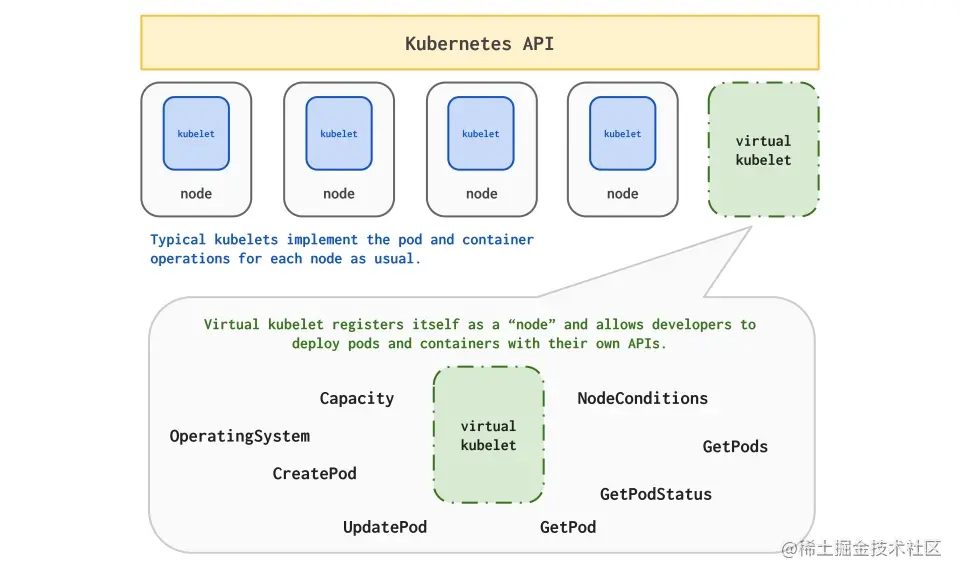
云音乐平台的CPU算力任务主要包括图计算、大规模离散和分布式训练三类,涉及到 tfjob, mpijob, paddlepaddle几种任务类型,任务副本之间均需要网络通信,包括跨集群执行Pod Exec,单副本规格大概在(4c-8c, 12G-20G)之间; 但是因资源算力不足,任务的副本数以及同时可运行的任务并行度很低,所以各个训练业务需忍受长时间的训练和任务执行等待。接入VK后,能够充分利用某些集群的闲置算力, 多副本、多任务并行地完成训练模型的迭代。
阿里云ECI
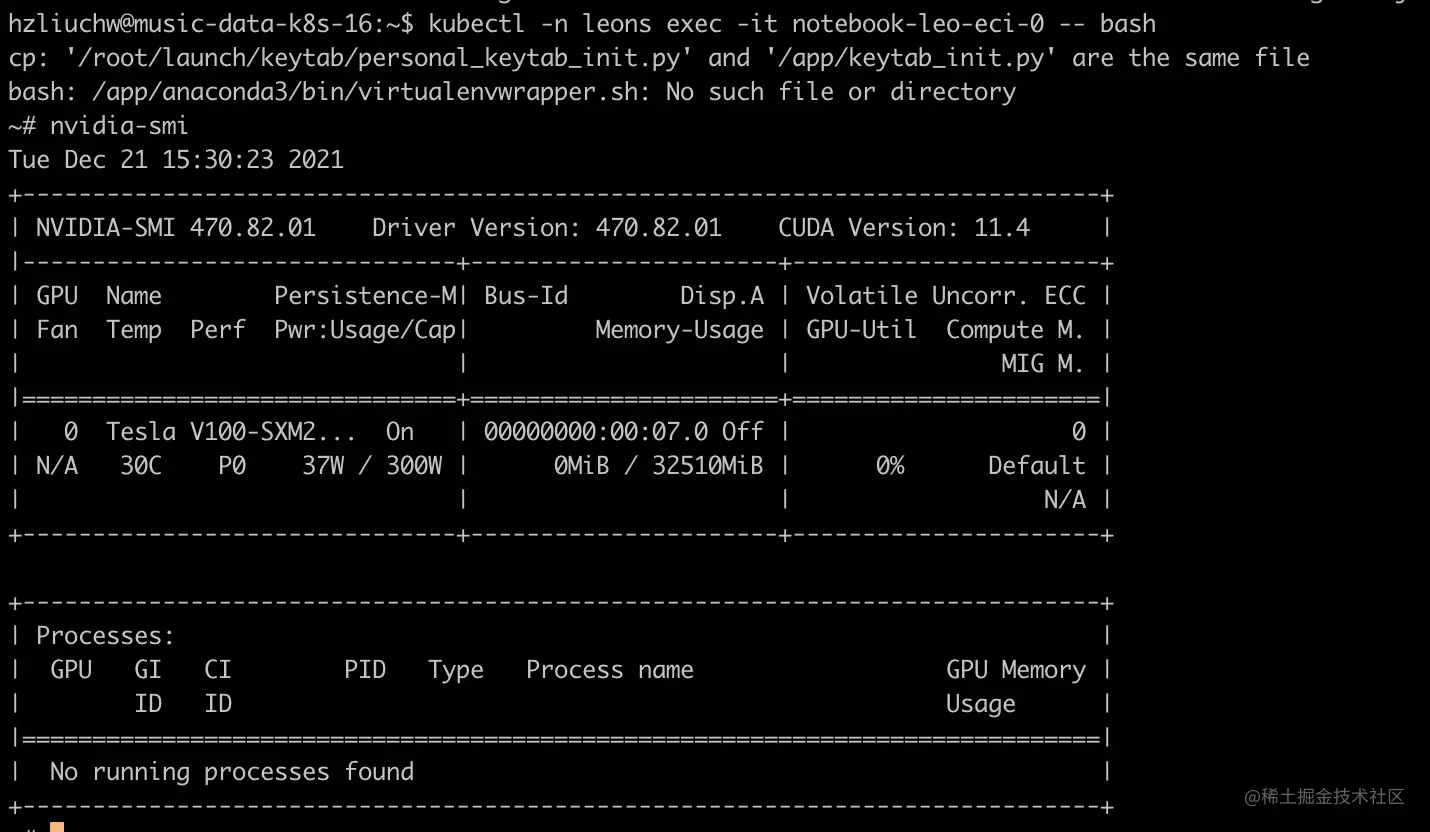
CPU资源可以通过kubeMiner来跨集群调度,但是GPU这块,基本上整个集团都比较紧张,为了防止未来某些时候,需要一定的GPU资源没办法满足。机器学习平台支持了阿里云ECI的调度,以类似VK的方式在我们自己的机器学习平台上调度起对应的GPU资源,如下是云音乐机器学习平台调用阿里云ECI资源,在云音乐机器学习平台上,用户只需要在选择对应的阿里云ECI资源,即可完成对阿里云ECI的弹性调度,目前已有突发性业务在相关能力上使用:

底层基座层:基础能力赋能用户
底层基座层是利用资源层转换为基础的能力,比如 通过spark、hadoop支持大数据基础能力、通过flink支持实时数据处理能力,通过k8s+docker支持海量任务的资源调度能力,这其中我们主要讲下ceph在整个平台的使用以及我们在实践优化中的一些工作。
Ceph
Ceph作为业界所指的一套分布式存储,在机器学习平台的业务中很多使用,比如在开发任务与调度任务中提供同一套文件系统,方便打通开发与调度环境,多读读写能力方便在分布式任务中同用一套文件系统。当然, 从0到1的接入,很多时候是功能性的需求,开源的Ceph存在即满足目标。但是,当越来越多的用户开始使用时,覆盖各种各样的场景,会有不同的需求,这里我们总结Ceph在机器学习平台上的一些待优化点:
- 数据安全性是机器学习平台重中之重功能,虽然CephFS支持多副本存储,但当出现误删等行为时,CephFS就无能为力了;为防止此类事故发生,要求CephFS有回收站功能;
- 集群有大量存储服务器,如果这些服务器均采用纯机械盘,那么性能可能不太够,如果均采用纯SSD,那么成本可能会比较高,因此期望使用SSD做日志盘,机械盘做数据盘这一混部逻辑,并基于此做相应的性能优化;
- 作为统一开发环境&#x
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









