







网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
小澜觉得,在字节不仅有技术的提升,学到了更加规范的工作流程,也接触到了更多的资源,字节“大厂”的身份也给自己的履历加了分,让自己能有机会获得更高的平台和更多良好的职业发展。
这些是字节作为互联网大厂给到小澜的成长。她也认为,对于年轻人,特别是应届毕业生,去大厂工作还是很有必要的,是一种人生体验,如果不进到大厂里,永远会觉得自己是围城外的人。
02、所有人都适合字节范儿吗?
80后的王希在字节已经不算年轻了。在进字节之前,他在业界也有了一定的能力和名声,用他的话来说,他算是陪着一批互联网公司一起成长起来的。
传闻中字节最卷的三大部门有:飞书、电商、本地生活。
在入职字节飞书后的王希彻底失去了个人的生活和娱乐空间。
“无意义的飞书加急,还有各种‘拉齐’的会议。”王希讲自己每天要参加6-7个会议,离谱的是还会出现“会议套会议”的情况,明明开着一个会,还有在线给另一个会发言,一天就在会议中完结。

而且他发现本质相同的一件事情,经常三四个部门一起干,甚至有的部门已经提前两个月在做,再往下推进的时候,各个部门再开会拉齐,消耗了一天大部分时间。
喜欢和商家与用户待在一起解决问题的王希最终决定离职,再次回到那个“纯粹的”小公司里。
03、留在大厂几年,实现财务自由也很香
同样是打工:有人28岁还在苦苦谋求一份大厂工作,而有的人28岁实现财务自由,选择退休!
知乎一篇《如何看待年仅28岁的郭宇宣布从字节跳动退休》的帖子,近1100多万的浏览量。
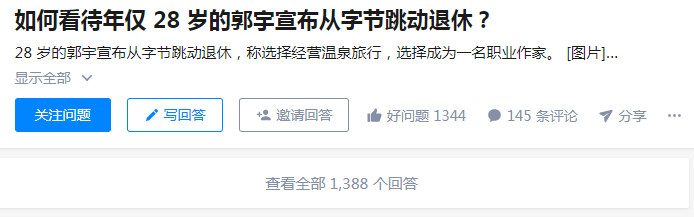
郭宇是前字节跳动资深技术专家。高中就自学代码,大三拿到支付宝offer,后加入字节拿到期权,28岁实现了财务自由从字节退休!
不少人感叹:一样的28岁,不一样的人生。
在那条知乎问题下面,有一篇郭宇朋友的回答文章,从他朋友的回答里,我们可以了解到一位真实的程序员成长路径。
高中就读于深圳名校,全国重点高中,而这所高中腾讯5位创始人,有4位毕业于此。
高考之后考入了暨南大学,他的专业却是政治与行政管理,专业是自己选的但是他不怎么去上课。
旷课的时间他不是像普通学生那样睡觉、打游戏,他利用这些时间去自学编程,在宿舍熬夜学习写代码。
大二开始就已经在找实习,能够早早不拘泥于大学课业的束缚,明确自己的目标,也是他的过人之处。大二面试腾讯,挂在第三面,大三终于拿到支付宝的实习。
非计算机专业出身,全靠自学做到这种程度,叫做逆天。自然郭宇的大厂履历很丰富。
2011年,大三去支付宝实习,留任前端开发工程师,正是在支付宝的这三年为他积累了深厚的互联网经验。
之后他自己创业误打误撞被字节跳动收购了,从此他的字节跳动工作生涯开启。
2014年到2020年,在字节的6年间,他的职位已经是资深技术专家,在这6年间,字节跳动估值暴涨,而他获得了字节跳动的期权。
郭宇后面自己说了他从字节离开,不是辞职是退休,是告别自己的互联网职业生涯,他28岁的理想是旅行在东京开旅馆,泡温泉。
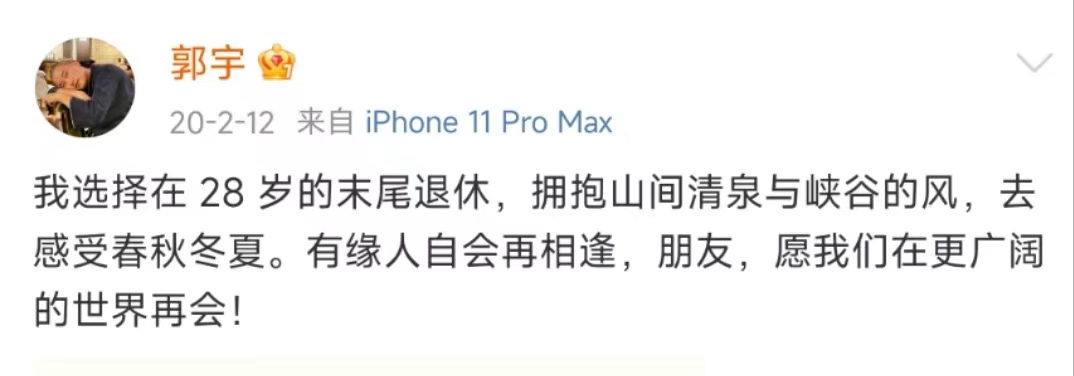
成功的人生往往不可复制,且成功的标准不一,但相同的是,为了实现自己目标或是人生理想为此要付出的汗水与努力。
不管是郭宇还是其他程序员,不断的学习是必不可少的,学好手上的编程技术,踏踏实实做梦,勤勤恳恳敲代码,有了技术的的底气才能更好的一步一步实现自己的目标。
人生短短三万天,郭宇没有选择本专业的工作,而是决定踏入互联网行业,并且追逐到了自己想要的自由。
而现在各大厂的年包价动辄50万+,比起其他行业,IT互联网的天花板依然无疑是最高的。在互联网行业,相信会有更多的人凭技术说话过上自己想要的生活。
为了助力程序员朋友们跳槽面试、升职加薪、职业困境,提高自己的技术,本文给大家整了一套涵盖软件测试面试进阶所有技术栈的快速学习方法和资源。
内容涵盖:测试理论、Linux基础、MySQL基础、Web测试、接口测试、App测试、管理工具、Python基础、Selenium相关、性能测试、LordRunner相关等专题技术点,都是在各个大厂总结出来的面试真题,已经有很多朋友靠这份 PDF 拿下众多大厂的 offer,今天在这里总结分享给到大家!
测试基础(38页)
功能测试(183页)
linux(221页)
Mysql(216页)
接口测试(338页)
Jmeter(41页)
测试工具(35页)
web自动化测试(50页)
selenium(55页)
python编程(27页)
app自动化测试(66页)
性能测试(40页)
安全测试(21页)
测试开发(31页)
简历模板(38页)
注:篇幅有限,资料已整理成文档,整体的内容知识点也是偏多的,截图是截取不完的,所以请各位朋友注意:若是需要下载整个软件测试面试宝典,有需要的读者朋友们可以帮忙三连支持一下,点击文末小卡片传送门即可入手~
一、基础知识–2023版
(包含计算机基础、测试理论、HTML基础、CSS基础、JS基础常见的面试题**)**

二、Linux和数据库 --2023版
(包含 linux、数据库介绍、SQL语言(重点)、数据库高级功能常见的面试题**)**


三、编程+数据结构–2023版
(包含 Python基础、面向对象、异常处理、模块和等等常见的面试题**)**

四、WEB自动化–2023版
(包含 WEB自动化入门、WEB自动化基础、WEB自动化中级、WEB自动化高级、项目实战等等常见的面试题**)**

五、移动自动化 --2023版
(包含 移动自动化基础、移动自动化中级、移动自动化高级等等常见的面试题**)**

六、接口测试–2023版
(包含 接口基础、postman实现接口测试、数据库操作、代码实现接口测试、持续集成、接口测试扩等等常见的面试题**)**

七、接口自动化–2023版
(包含 接口自动化脚本编写、接口自动化测试执行、接口自动化测试报告分析****等等常见的面试题**)**

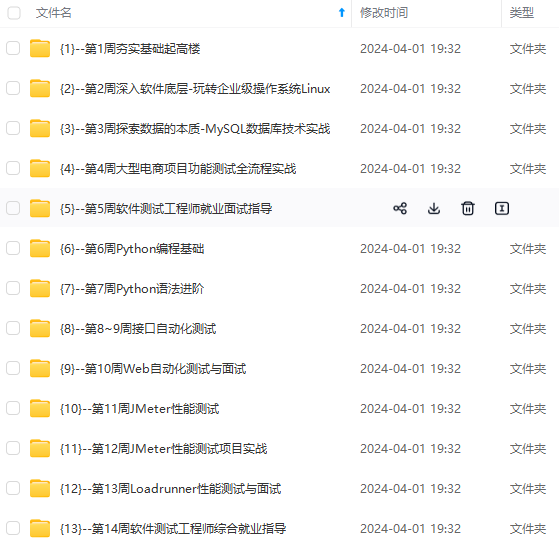
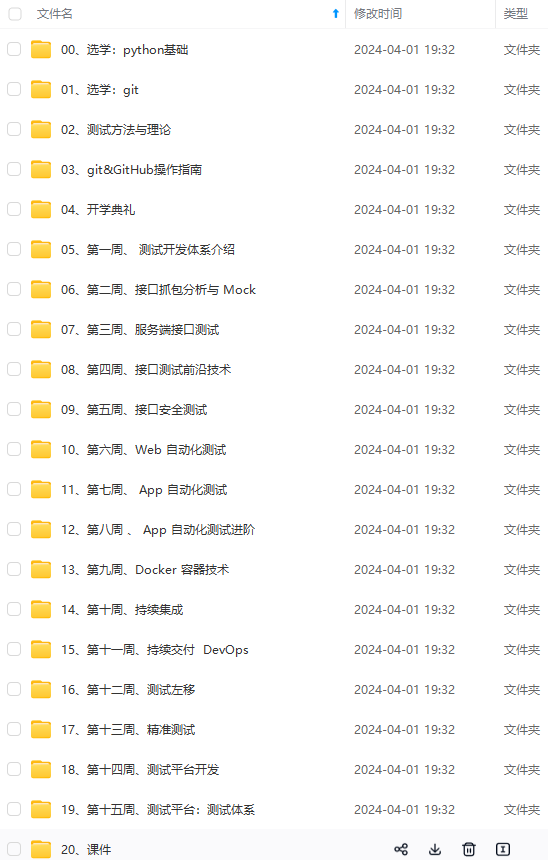
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上软件测试知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上软件测试知识点,真正体系化!**
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新

















 1630
1630

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









