







Java面试核心知识点笔记
其中囊括了JVM、锁、并发、Java反射、Spring原理、微服务、Zookeeper、数据库、数据结构等大量知识点。
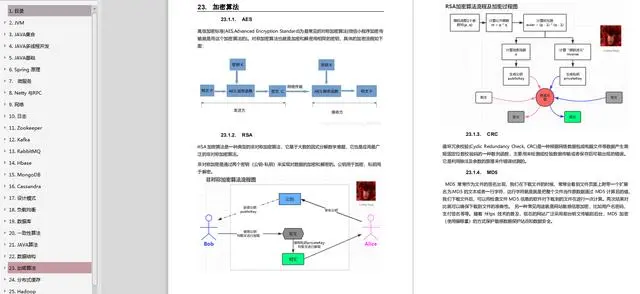
Java中高级面试高频考点整理

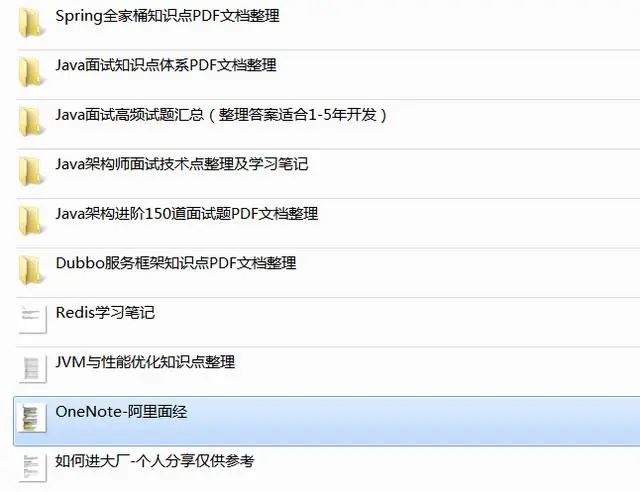
最后分享Java进阶学习及面试必备的视频教学
现在互联网公司一般都具备与之规模相对应的大数据服务或者平台,那么作为业务开发者要善于应用公司大数据能力,减轻业务数据库压力。
3.1 消息队列
这些海量数据可以存储至Kafka,因为其本质上就是分布式的流数据存储系统。使用Kafka有如下优点:
第一个优点是Kafka社区活跃功能强大,已经成为了一种事实上的工业标准。大数据很多组件都提供了Kafka接入组件,经过生产验证并且对接成本较小,可以为下游业务提供更多选择。
第二个优点是Kafka具有消息队列本身的优点例如解耦、异步和削峰。

假设这些海量数据都已经存储在Kafka,现在我们希望这些数据可以产生业务价值,这涉及到两种数据分析任务:离线任务和实时任务。
离线任务对实时性要求不高,例如每天、每周、每月的数据报表统计分析,我们可以使用基于MapReduce数据仓库工具Hive进行报表统计。
实时任务对实时性要求高,例如根据用户相关行为推荐用户感兴趣的商品,提高用户购买体验和效率,可以使用Flink进行流处理分析。例如运营后台查询分析,可以将数据同步至ES进行检索。
还有一种分类方式是将任务分为批处理任务和流处理任务,我们可以这么理解:离线任务一般使用批处理技术,实时任务一般使用流处理技术。
3.2 API
上一个章节我们使用了Kafka进行海量数据存储,由于其强大兼容性和集成度,可以作为数据中介将数据进行中转和解耦。
当然我们并不是必须使用Kafka进行中转,例如我们直接可以使用相关Java API将数据存入Hive、ES、HBASE等。
但是我并不推荐这种做法,因为将保存流水这样操作耦合进业务代码并不合适,违反了高内聚低耦合的原则,尽量不要使用。
3.3 缓存
从广义上理解换这个字,我们还可以引入Redis远程缓存,把Redis放在MySQL前面,拦下一些高频读请求,但是要注意缓存穿透和击穿问题。
缓存穿透和击穿从最终结果上来说都是流量绕过缓存打到了数据库,可能会导致数据库挂掉或者系统雪崩,但是仔细区分还是有一些不同,我们分析一张业务读取缓存一般流程图。
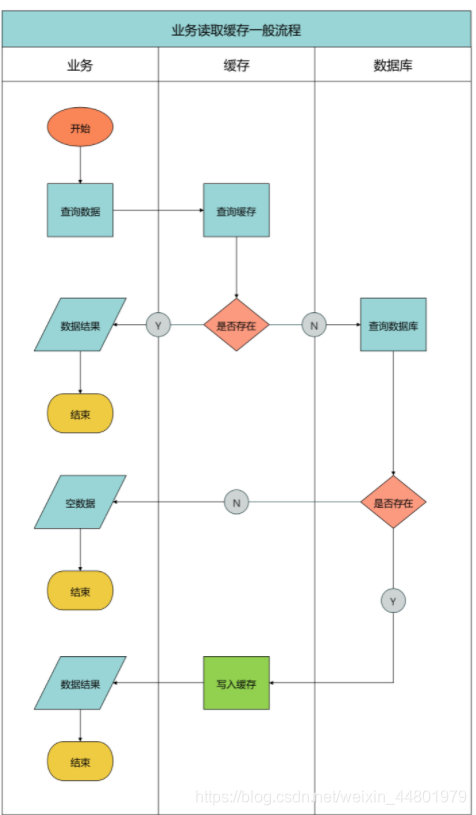
我们用文字简要描述这张图:
(1) 业务查询数据时首先查询缓存,如果缓存存在数据则返回,流程结束
(2) 如果缓存不存在数据则查询数据库,如果数据库不存在数据则返回空数据,流程结束
(3) 如果数据库存在数据则将数据写入缓存并返回数据给业务,流程结束
假设业务方要查询A数据,缓存穿透是指数据库根本不存在A数据,所以根本没有数据可以写入缓存,导致缓存层失去意义,大量请求会频繁访问数据库。
缓存击穿是指请求在查询数据库前,首先查缓存看看是否存在,这是没有问题的。但是并发量太大,导致第一个请求还没有来得及将数据写入缓存,后续大量请求已经开始访问缓存,这是数据在缓存中还是不存在的,所以瞬时大量请求会打到数据库。
我们可以使用分布式锁加上自旋解决这个问题,本文给出一段示例代码:
/**
-
业务回调
-
@author 今日头条号「JAVA前线」
*/
public interface RedisBizCall {
/**
-
业务回调方法
-
@return 序列化后数据值
*/
String call();
}
/**
-
安全缓存管理器
-
@author 今天头条号「JAVA前线」
*/
@Service
public class SafeRedisManager {
@Resource
private RedisClient RedisClient;
@Resource
private RedisLockManager redisLockManager;
public String getDataSafe(String key, int lockExpireSeconds, int dataExpireSeconds, RedisBizCall bizCall, boolean alwaysRetry) {
boolean getLockSuccess = false;
try {
while(true) {
String value = redisClient.get(key);
if (StringUtils.isNotEmpty(value)) {
return value;
}
/** 竞争分布式锁 **/
if (getLockSuccess = redisLockManager.tryLock(key, lockExpireSeconds)) {
value = redisClient.get(key);
if (StringUtils.isNotEmpty(value)) {
return value;
}
/** 查询数据库 **/
value = bizCall.call();
/** 数据库无数据则返回**/
if (StringUtils.isEmpty(value)) {
return null;
}
/** 数据存入缓存 **/
redisClient.setex(key, dataExpireSeconds, value);
return value;
} else {
if (!alwaysRetry) {
logger.warn(“竞争分布式锁失败,key={}”, key);
return null;
}
Thread.sleep(100L);
logger.warn(“尝试重新获取数据,key={}”, key);
}
}
} catch (Exception ex) {
logger.error(“getDistributeSafeError”, ex);
return null;
} finally {
if (getLockSuccess) {
redisLockManager.unLock(key);
}
}
}
}
我们首先看一个概念:读写比。互联网场景中一般是读多写少,例如浏览20次订单列表信息才会进行1次确认收货,此时读写比例就是20:1。面对读多写少这种情况我们可以做什么呢?
我们可以部署多台MySQL读库专门用来接收读请求,主库接收写请求并通过binlog实时同步的方式将数据同步至读库。MySQL官方即提供这种能力,进行简单配置即可。
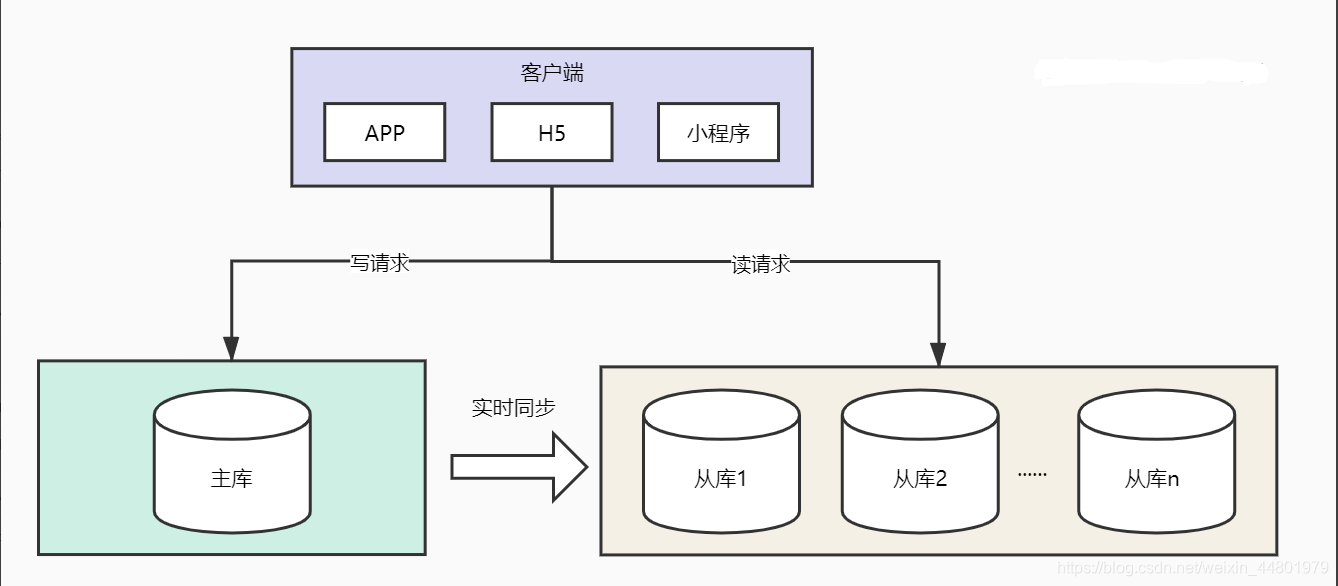
那么客户端怎么知道访问读库还是写库呢?推荐使用ShardingSphere组件,通过配置将读写请求分别路由至读库或者写库。
如果删除了历史数据并采用了其它存储介质,也用了读写分离,但是单表压力还是太大怎么办?这时我们只能拆分数据表,即把单库单表数据迁移到多库多张表中。
假设有一个电商数据库存放订单、商品、支付三张业务表。随着业务量越来越大,这三张业务数据表也越来越大,我们就以这个例子进行分析。
5.1 垂直拆分
垂直拆分就是按照业务拆分,我们将电商数据库拆分成三个库,订单库、商品库。支付库,订单表在订单库,商品表在商品库,支付表在支付库。这样每个库只需要存储本业务数据,物理隔离不会互相影响。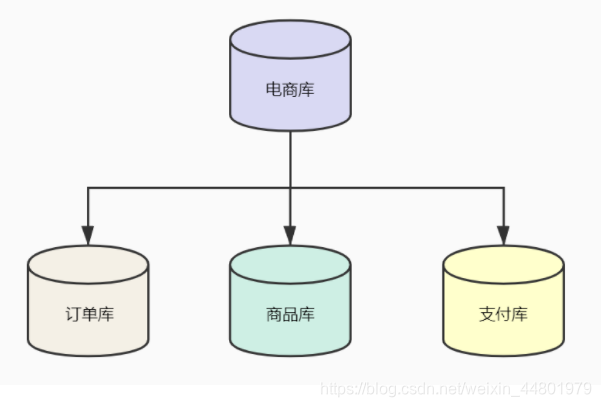
5.2 水平拆分
按照垂直拆分方案,现在我们已经有三个库了,平稳运行了一段时间。但是随着业务增长,每个单库单表的数据量也越来越大,逐渐到达瓶颈。
这时我们就要对数据表进行水平拆分,所谓水平拆分就是根据某种规则将单库单表数据分散到多库多表,从而减小单库单表的压力。
水平拆分策略有很多方案,最重要的一点是选好ShardingKey,也就是按照哪一列进行拆分,怎么分取决于我们访问数据的方式。
5.2.1 范围分片
现在我们要对订单库进行水平拆分,我们选择的ShardingKey是订单创建时间,拆分策略如下:
(1) 拆分为四个数据库,分别存储每个季度的数据
(2) 每个库三张表,分别存储每个月的数据
上述方法优点是对范围查询比较友好,例如我们需要统计第一季度的相关数据,查询条件直接输入时间范围即可。
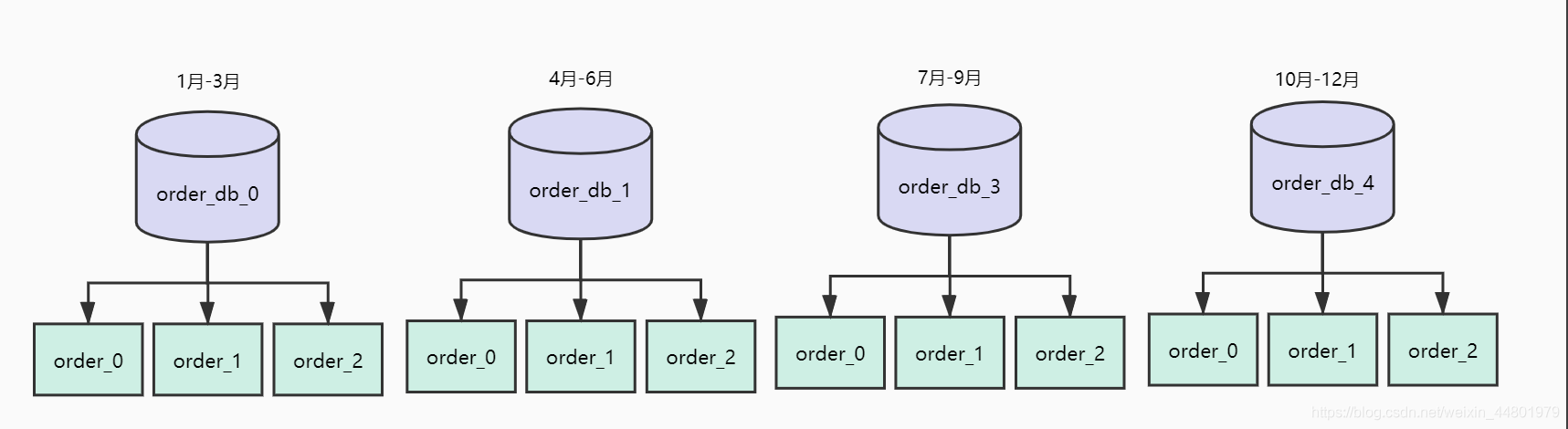
但是这个方案问题是容易产生热点数据。例如双11当天下单量特别大,就会导致11月这张表数据量特别大从而造成访问压力。
5.2.2 查表分片
查表法是根据一张路由表决定ShardingKey路由到哪一张表,每次路由时首先到路由表里查到分片信息,再到这个分片去取数据。
我们分析一个查表法实际案例。Redis官方在3.0版本之后提供了集群方案Redis Cluster,其中引入了哈希槽(slot)这个概念。
一个集群固定有16384个槽,在集群初始化时这些槽会平均分配到Redis集群节点上。每个key请求最终落到哪个槽计算公式是固定的:
SLOT = CRC16(key) mod 16384
那么问题来了:一个key请求过来怎么知道去哪台Redis节点获取数据?这就要用到查表法思想。
(1) 客户端连接任意一台Redis节点,假设随机访问到为节点A
(2) 节点A根据key计算出slot值
(3) 每个节点都维护着slot和节点映射关系表
(4) 如果节点A查表发现该slot在本节点则直接返回数据给客户端
(5) 如果节点A查表发现该slot不在本节点则返回给客户端一个重定向命令,告诉客户端应该去哪个节点上请求这个key的数据
(6) 客户端再向正确节点发起连接请求
查表法优点是可以灵活制定路由策略,如果我们发现有的分片已经成为热点则修改路由策略。缺点是多一次查询路由表操作增加耗时,而且路由表如果是单点也可能会有单点问题。
5.2.3 哈希分片
现在比较流行的分片方法是哈希分片,相较于范围分片,哈希分片可以较为均匀将数据分散在数据库中。
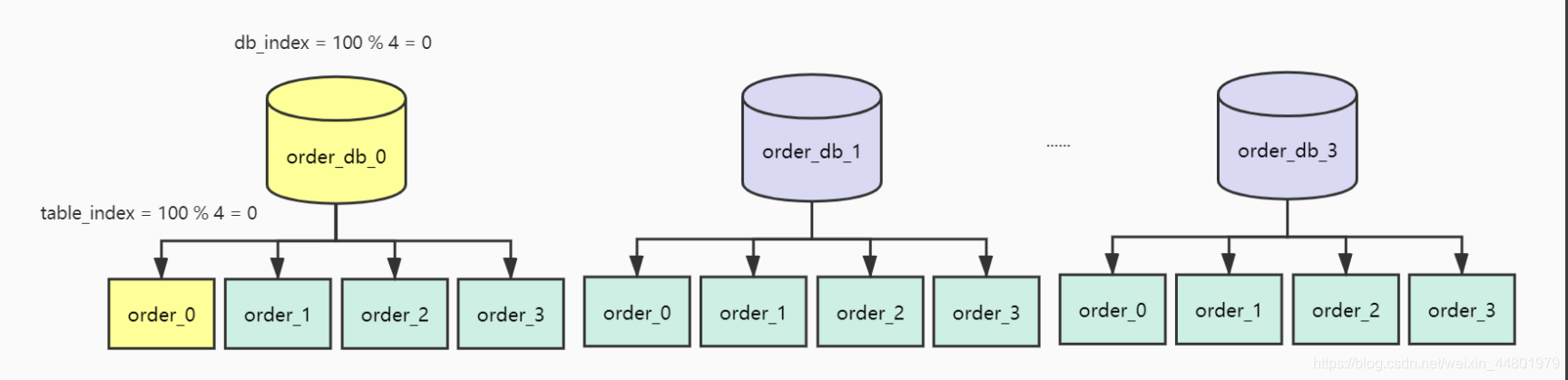
我们现在将订单库拆分为4个库编号为[0,3],每个库4张表编号为[0,3],如下图如所示:
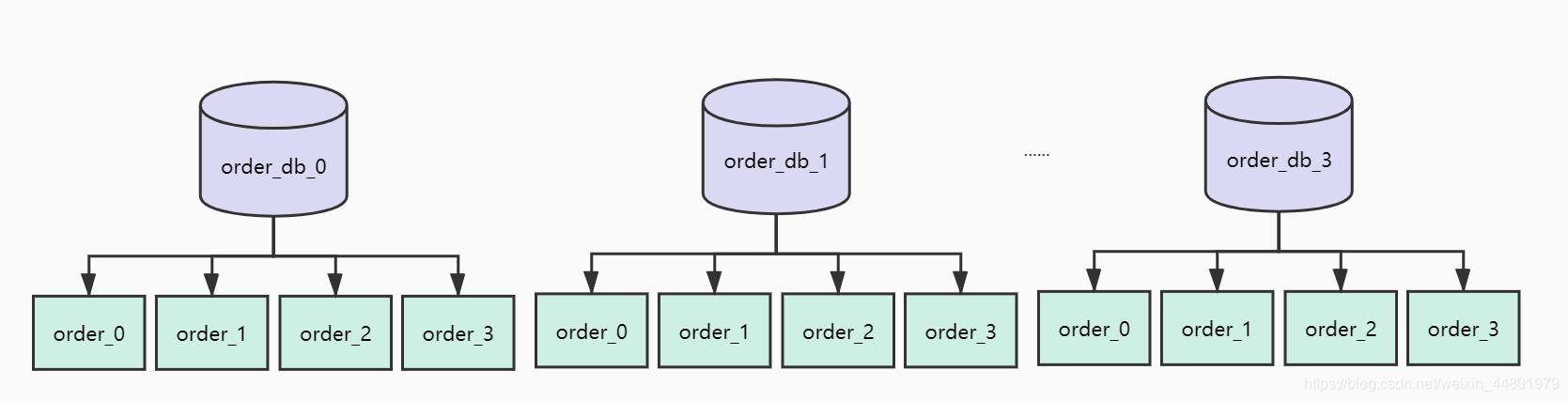
现在使用orderId作为ShardingKey,那么orderId=100的订单会保存在哪张表?我们来计算一下:由于是分库分表,首先确定路由到哪一个库,取模计算得到序号为0表示路由到db[0]
db_index = 100 % 4 = 0
库确定了接着在db[0]进行取模表路由
table_index = 100 % 4 = 0
最终这条数据应该路由至下表
db[0]_table[0]
最终计算结果如下图所示:
在实际开发中最终路由到哪张表,并不需要我们自己算,因为有许多开源框架就可以完成路由功能,例如ShardingSphere、TDDL等等。
最后
整理的这些资料希望对Java开发的朋友们有所参考以及少走弯路,本文的重点是你有没有收获与成长,其余的都不重要,希望读者们能谨记这一点。

其实面试这一块早在第一个说的25大面试专题就全都有的。以上提及的这些全部的面试+学习的各种笔记资料,我这差不多来回搞了三个多月,收集整理真的很不容易,其中还有很多自己的一些知识总结。正是因为很麻烦,所以对以上这些学习复习资料感兴趣,
收获与成长,其余的都不重要,希望读者们能谨记这一点。
[外链图片转存中…(img-lchSIzG9-1715718912390)]
[外链图片转存中…(img-uqOOeEAr-1715718912390)]
其实面试这一块早在第一个说的25大面试专题就全都有的。以上提及的这些全部的面试+学习的各种笔记资料,我这差不多来回搞了三个多月,收集整理真的很不容易,其中还有很多自己的一些知识总结。正是因为很麻烦,所以对以上这些学习复习资料感兴趣,

















 691
691

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









