







最后
码字不易,觉得有帮助的可以帮忙点个赞,让更多有需要的人看到
又是一年求职季,在这里,我为各位准备了一套Java程序员精选高频面试笔试真题,来帮助大家攻下BAT的offer,题目范围从初级的Java基础到高级的分布式架构等等一系列的面试题和答案,用于给大家作为参考
以下是部分内容截图
如下图,3的insert结果确实没有被回滚,而是出现在了表中: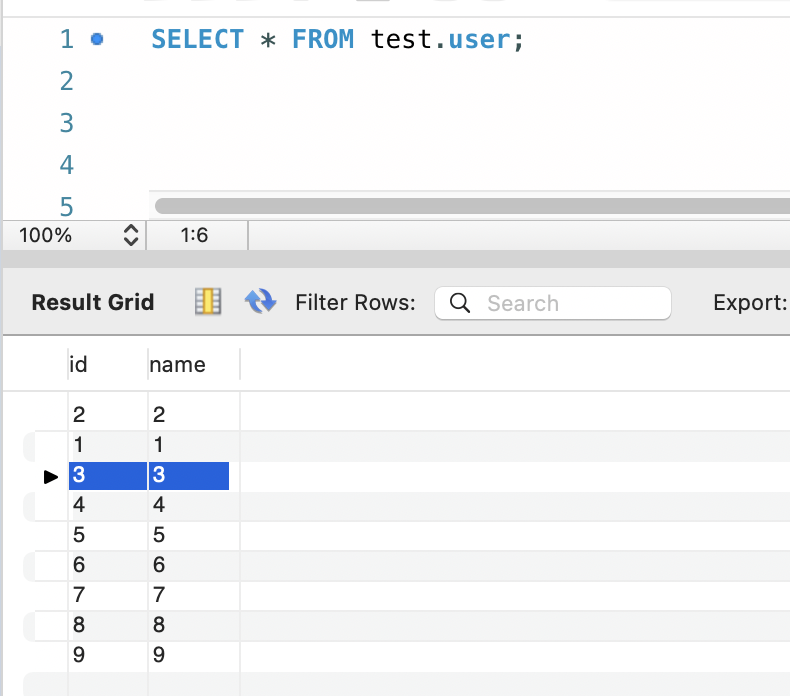
所以,对于知识,大家不能盲目的接收,建议抱些怀疑的态度,还是有必要的。
$ 话说回来,为什么threadlocal对同一个数据库连接不起作用呢?
Connection是什么?
connection可以当成是服务器和数据库的一个会话,而statemant用来在会话的上下文中执行sql以及返回结果。一个connection可以包含多个statement;然而在两者中间,还有一个事务(Translation)的概念,事务用来保证其内部的语句,要么都执行,要么都不执行,如果autoCommit被开启,则默认是一个语句一个事务。
往简单点说,connection是一种共享资源,更简单一点,它是一个共享变量,在被连接池创建之后,在内存中的地址是唯一的一个变量。
ThreadLocal能存共享变量么?
存肯定能存,但不建议,因为将Connection set进ThreadLocalMap,也其实是保存一个内存对象的地址引用而已,真正使用的时候,还是唯一的那个对象在起作用。
ThreadLocal最常用的功能,是为了避免层层传递而提供了对象保存和获取方法。
高中学数学的时候曾经有过一个技巧,叫证难则反,在这里也适用。我们反过来想,如果用threadlocal的副本拷贝能实现connection的隔离,那岂不是只要一个connection就可以了?实时上呢,数据库连接常常会出现不够用的情况,结论就显而易见了~
$ 话又说回来,threadLocal想要完成数据库连接隔离的功能,需要怎么做呢?
如果非要用ThreadLocal实现这个连接隔离的功能,那么,只能是为每个线程创建新的连接,然后保存在Threadlocal中,这样,每个线程在自己的生命周期范围内只会使用这个连接,即可实现线程隔离。
$ 话又又说回来,druid、zadl等一众数据库连接池是怎么进行连接的管理工作的呢?
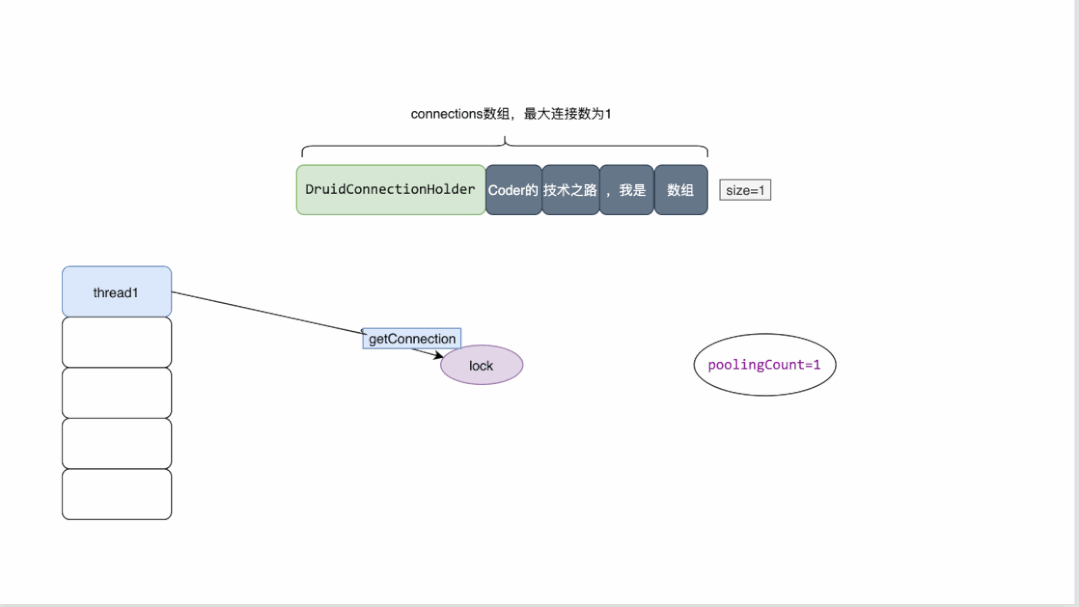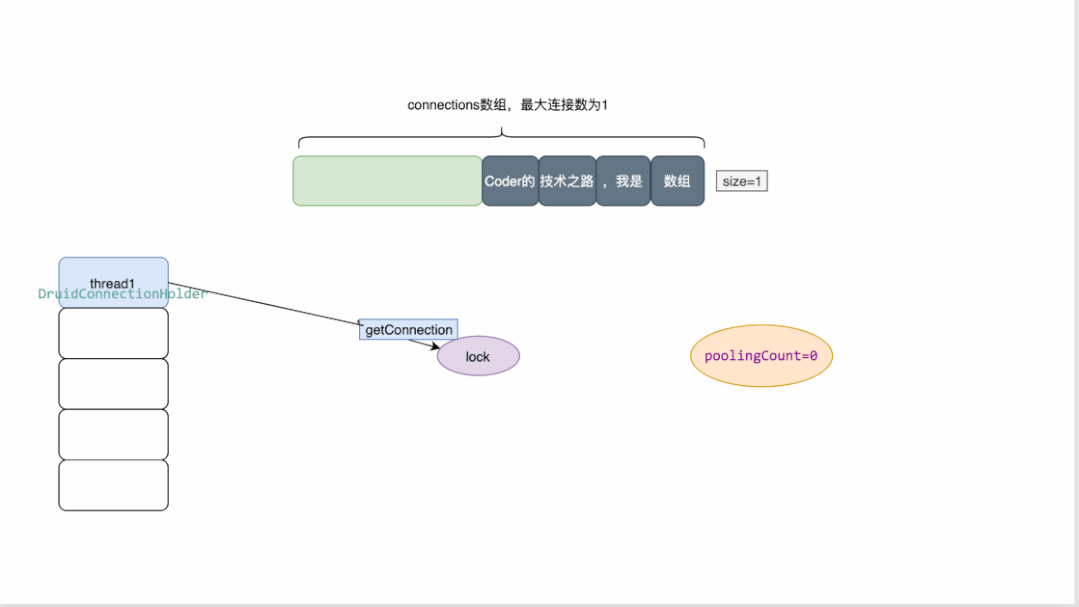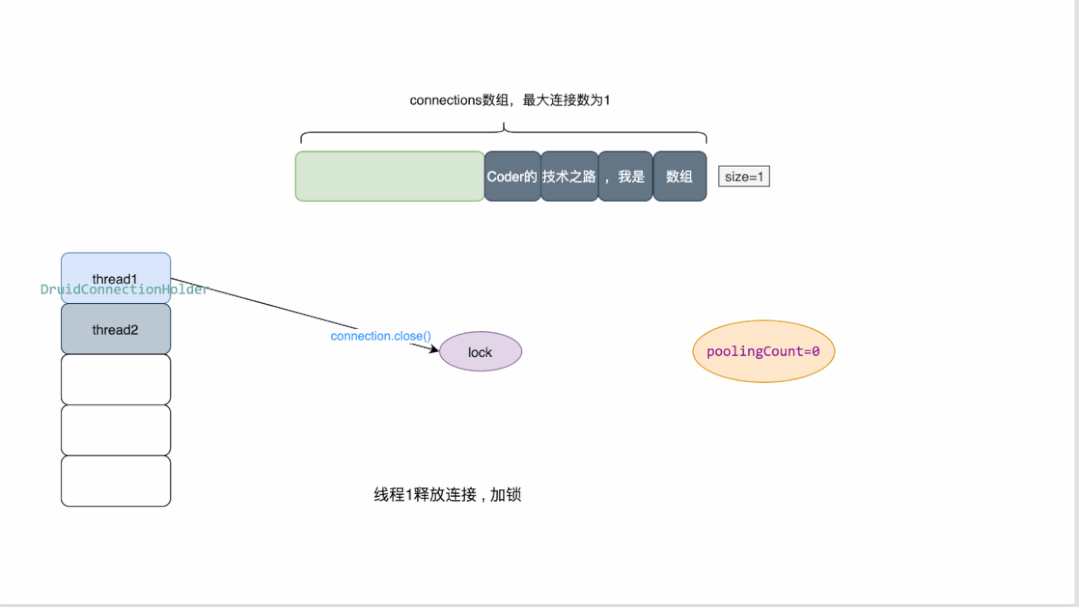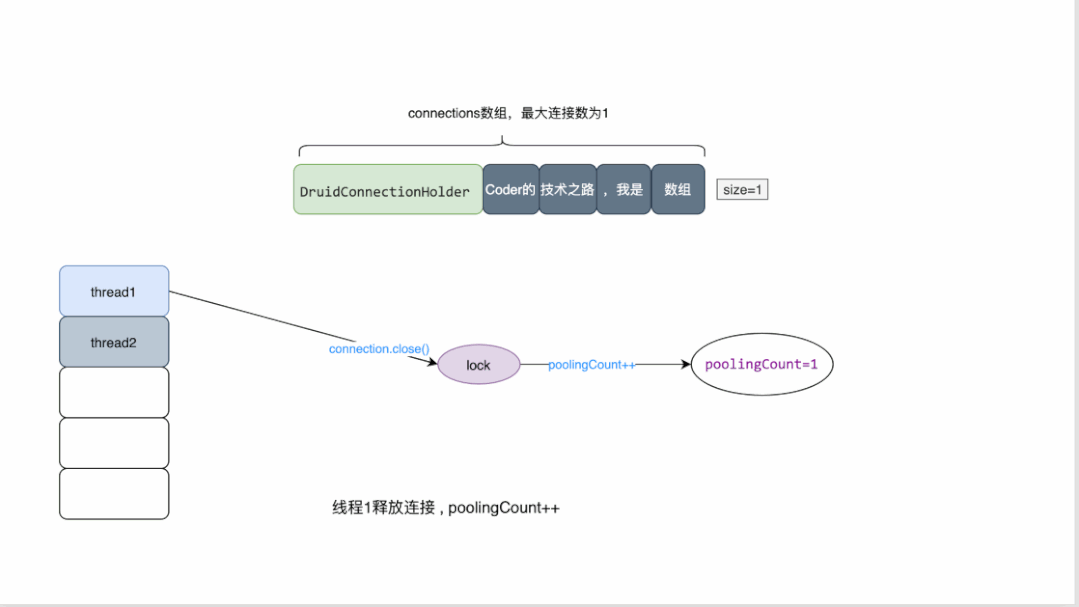
最大连接数为1的druid连接池原理概览:
-
druid维护一个数组来存放连接
-
同时维护了多个变量来检测连接池的状态,其中poolingCount用来表示池中连接的数量
-
当有线程来获取连接时,需要先加锁,对数量进行减一操作。
-
当获取连接时发现数量为0 ,则返回为空
-
当连接关闭时,会将连接资源放回数组,并对数量做加一操作。
*上述只是druid连接池的极简版流程叙述,实际上,还有连接池空等待、满通知、活跃数、异常数等的复杂判断。*有兴趣的同学可以看下源码。
zdal的连接池管理源码一览::
public class InternalManagedConnectionPool{
//最大连接数
private final int maxSize;
//用来存放连接的链表
private final ArrayList connectionListeners;
//内部的信号量,用来控制允许获取资源的线程总数
private final InternalSemaphore permits;
//正在使用的连接数
private volatile int maxUsedConnections = 0;
protected InternalManagedConnectionPool(…){
//构造函数中,初始化了连接池大小和信号量大小
connectionListeners = new ArrayList(this.maxSize);
permits = new InternalSemaphore(this.maxSize);
}
getConnection()方法:
//获取连接
public ConnectionListener getConnection(){
//信号量尝试获取许可
if (permits.tryAcquire(poolParams.blockingTimeout, TimeUnit.MILLISECONDS)) {
ConnectionListener cl = null;
do {
//加锁资源池
synchronized (connectionListeners) {
if (connectionListeners.size() > 0) {
//获取list的最后一个
cl = (ConnectionListener) connectionListeners.remove(connectionListeners.size() - 1);
//最大连接数 减去 正在工作的信号量
int size = (maxSize - permits.availablePermits());
if (size > maxUsedConnections){
maxUsedConnections = size;
}
}
}
if (cl != null) {
return cl;
}
}while(connectionListeners.size() > 0);
//OK, 在连接池中找不到正在工作的连接了. 那就创建个新的
createNewConnection(){…}
}else{
if (this.maxSize == this.maxUsedConnections) {
throw new ResourceException(
"数据源最大连接数已满,并且在超时时间范围内没有新的连接释放,poolName = "
+ poolName
+ " blocking timeout="
+ poolParams.blockingTimeout +
“(ms)”);
}
}
这里把内部连接池的管理类的关键属性和连接获取方法流量进行了简化,连接归还就不弄了,大同小异,仔细看,我们看到了什么
-
volatile 标识的maxUsedConnections用来完成线程间数据可见
-
隶属于AQS系列的Semaphone,用来控制共享资源并发访问量。
都是些常见的八股文,不过组合起来可就了不得~
$ 话又又又说回来,在druid、zdal中,threadlocal的作用体现在哪里呢?
我们知道,诚如druid、zdal等优秀的中间件,可不止是数据库连接池这一个作用。
那么,ThreadLocal能在这里扮演什么角色呢?
就以zdal为例,因为阿里的数据库规模基本都非常大,但又有一套完备的数据库库表拆分规范,因此,分库键、分表键、主键、虚拟表名等在设计和存储时需要遵循规范,而zdal中的解析操作,也需要与之相匹配。
这个解析工作是相对复杂且繁重的,然而,针对同一用户的操作,通常库表的路由是相对固定的,因此,当我们解析过一次sql,通过各个字段和配置规则,计算出了库表路由,那么,可以直接put进线程上下文,供本次请求的后续数据库操作使用。
public Object parse(…){
SimpleCondition simpleCondition = new SimpleCondition();
simpleCondition.setVirtualTableName(“user”);
simpleCondition.put(“age”, 10);
ThreadLocalMap.put(ThreadLocalString.ROUTE_CONDITION, simpleCondition);
}
总结
面试难免让人焦虑不安。经历过的人都懂的。但是如果你提前预测面试官要问你的问题并想出得体的回答方式,就会容易很多。
此外,都说“面试造火箭,工作拧螺丝”,那对于准备面试的朋友,你只需懂一个字:刷!
给我刷刷刷刷,使劲儿刷刷刷刷刷!今天既是来谈面试的,那就必须得来整点面试真题,这不花了我整28天,做了份“Java一线大厂高岗面试题解析合集:JAVA基础-中级-高级面试+SSM框架+分布式+性能调优+微服务+并发编程+网络+设计模式+数据结构与算法等”
且除了单纯的刷题,也得需准备一本【JAVA进阶核心知识手册】:JVM、JAVA集合、JAVA多线程并发、JAVA基础、Spring 原理、微服务、Netty与RPC、网络、日志、Zookeeper、Kafka、RabbitMQ、Hbase、MongoDB、Cassandra、设计模式、负载均衡、数据库、一致性算法、JAVA算法、数据结构、加密算法、分布式缓存、Hadoop、Spark、Storm、YARN、机器学习、云计算,用来查漏补缺最好不过。
、Spark、Storm、YARN、机器学习、云计算,用来查漏补缺最好不过。
[外链图片转存中…(img-MZRhNWfd-1715687271517)]


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









