







最后
经过日积月累, 以下是小编归纳整理的深入了解Java虚拟机文档,希望可以帮助大家过关斩将顺利通过面试。
由于整个文档比较全面,内容比较多,篇幅不允许,下面以截图方式展示 。






由于篇幅限制,文档的详解资料太全面,细节内容太多,所以只把部分知识点截图出来粗略的介绍,每个小节点里面都有更细化的内容!
向user表中插入信息,row key为rk0001,列族data中添加名为pic的列,值为picture
HBase(main):014:0> put ‘user’, ‘rk0001’, ‘data:pic’, ‘picture’

④ 查询数据操作一
查询方式一 使用get命令通过rowkey进行查询
获取user表中row key为rk0001的所有信息(即所有cell的数据)
使用get命令
HBase(main):015:0> get ‘user’, ‘rk0001’

使用get命令查看rowkey下某个列族的信息
获取user表中row key为rk0001,info列族的所有信息
HBase(main):016:0> get ‘user’, ‘rk0001’, ‘info’

使用get命令查看rowkey指定列族指定字段的值
获取user表中row key为rk0001,info列族的name、age列的信息
HBase(main):017:0> get ‘user’, ‘rk0001’, ‘info:name’, ‘info:age’


使用get命令查看rowkey指定多个列族的信息
获取user表中row key为rk0001,info、data列族的信息
HBase(main):018:0> get ‘user’, ‘rk0001’, ‘info’, ‘data’
或者你也可以这样写
HBase(main):019:0> get ‘user’, ‘rk0001’, {COLUMN => [‘info’, ‘data’]}
或者你也可以这样写,也行
HBase(main):020:0> get ‘user’, ‘rk0001’, {COLUMN => [‘info:name’, ‘data:pic’]}

使用get命令指定rowkey与列值过滤器查询
获取user表中row key为rk0001,cell的值为zhangsan的信息
HBase(main):021:0> get ‘user’, ‘rk0001’, {FILTER => “ValueFilter(=, ‘binary:zhangsan’)”}

使用get命令指定rowkey与列名模糊查询
获取user表中row key为rk0001,列标示符中含有a的信息
HBase(main):022:0> get ‘user’, ‘rk0001’, {FILTER => “QualifierFilter(=,‘substring:a’)”}

继续插入一批数据
HBase(main):023:0> put ‘user’, ‘rk0002’, ‘info:name’, ‘fanbingbing’
HBase(main):024:0> put ‘user’, ‘rk0002’, ‘info:gender’, ‘female’
HBase(main):025:0> put ‘user’, ‘rk0002’, ‘info:nationality’, ‘中国’
HBase(main):026:0> get ‘user’, ‘rk0002’, {FILTER => “ValueFilter(=, ‘binary:中国’)”}

⑤ 查询所有行的数据二
查询user表中的所有信息
使用scan命令
HBase(main):027:0> scan ‘user’

使用scan命令进行列族查询
查询user表中列族为info的信息

scan ‘user’, {COLUMNS => ‘info’}

//当把某些列的值删除后,具体的数据并不会马上从存储文件中删除;查询的时候,不显示被删除的数据;如果想要查询出来的话,RAW => true
scan ‘user’, {COLUMNS => ‘info’, RAW => true, VERSIONS => 5}

scan ‘user’, {COLUMNS => ‘info’, RAW => true, VERSIONS => 3}

使用scan命令进行多列族查询
查询user表中列族为info和data的信息
scan ‘user’, {COLUMNS => [‘info’, ‘data’]}

使用scan命令指定列族与某个列名查询
查询user表中列族为info、列标示符为name的信息
scan ‘user’, {COLUMNS => ‘info:name’}

查询info:name列、data:pic列的数据
scan ‘user’, {COLUMNS => [‘info:name’, ‘data:pic’]}

查询user表中列族为info、列标示符为name的信息,并且版本最新的5个
scan ‘user’, {COLUMNS => ‘info:name’, VERSIONS => 5}

使用scan命令指定多个列族与条件模糊查询
查询user表中列族为info和data且列标示符中含有a字符的信息
scan ‘user’, {COLUMNS => [‘info’, ‘data’], FILTER => “QualifierFilter(=,‘substring:a’)”}

使用scan命令指定rowkey的范围查询
查询user表中列族为info,rk范围是[rk0001, rk0003)的数据
scan ‘user’, {COLUMNS => ‘info’, STARTROW => ‘rk0001’, ENDROW => ‘rk0003’}

使用scan命令指定rowkey模糊查询
查询user表中row key以rk字符开头的数据

使用scan命令指定数据版本的范围查询
查询user表中指定范围的数据(前闭后开)
scan ‘user’, {TIMERANGE => [1392368783980, 1392380169184]}

hbase(main):039:0> scan ‘user’, {TIMERANGE => [1615386788707,1615386809222]}

⑥ 更新数据操作
1 更新数据值
更新操作同插入操作一模一样,只不过有数据就更新,没数据就添加
使用put命令
2 更新版本号
将user表的f1列族版本数改为5
HBase(main):040:0> alter ‘user’, NAME => ‘info’, VERSIONS => 5

⑦ 删除数据以及删除表操作
1 指定rowkey以及列名进行删除
删除user表row key为rk0001,列标示符为info:name的数据(删除一个kv数据)
HBase(main):041:0> delete ‘user’, ‘rk0001’, ‘info:name’

删除整行数据
hbase(main):024:0> deleteall 't\_user\_info','001'
0 row(s) in 0.0090 seconds
hbase(main):025:0> get 't\_user\_info','001'
COLUMN CELL
0 row(s) in 0.0110 seconds
2 指定rowkey,列名以及版本号进行删除
删除user表row key为rk0001,列标示符为info:name,timestamp为1392383705316的数据
hbase(main):042:0> delete ‘user’, ‘rk0001’, ‘info:name’, 1392383705316

3 删除一个列族
删除一个列族:
alter ‘user’, NAME => ‘info’, METHOD => ‘delete’
或 alter ‘user’, ‘delete’ => ‘info’

4 清空表数据
HBase(main):045:0> truncate ‘user’

5 删除表
首先需要先让该表为disable状态,使用命令:
HBase(main):049:0> disable ‘user’
然后使用drop命令删除这个表
HBase(main):050:0> drop ‘user’

(注意:如果直接drop表,会报错:Drop the named table. Table must first be disabled)

⑧ 统计一张表有多少行数据
HBase(main):046:0> count ‘user’

六 HBase的高级shell管理命令
1 status
例如:显示服务器状态
HBase(main):051:0> status ‘node01’

2 whoami
显示HBase当前用户,例如:
HBase> whoami

3 list
显示当前所有的表
HBase > list

4 count
统计指定表的记录数,例如:
HBase> count ‘user’

为了展示下面功能,然后重新创建user表,并插入数据
创建user表,包含info、data两个列族
使用create命令
hbase(main):008:0> create 'user', 'info', 'data'
0 row(s) in 1.3080 seconds
向表中插入数据
使用put命令
向user表中插入信息,row key为rk0001,列族info中添加名为name的列,值为zhangsan
HBase(main):011:0> put 'user', 'rk0001', 'info:name', 'zhangsan'
向user表中插入信息,row key为rk0001,列族info中添加名为gender的列,值为female
HBase(main):012:0> put 'user', 'rk0001', 'info:gender', 'female'
向user表中插入信息,row key为rk0001,列族info中添加名为age的列,值为20
HBase(main):013:0> put 'user', 'rk0001', 'info:age', 20
向user表中插入信息,row key为rk0001,列族data中添加名为pic的列,值为picture
HBase(main):014:0> put 'user', 'rk0001', 'data:pic', 'picture'

5 describe
展示表结构信息
HBase> describe ‘user’

6 exists
检查表是否存在,适用于表量特别多的情况

7 is_enabled、is_disabled
检查表是否启用或禁用
HBase> is_enabled ‘user’
HBase> is_disabled ‘user’

8 alter
该命令可以改变表和列族的模式,例如:
为当前表增加列族:
HBase> alter ‘user’, NAME => ‘CF2’, VERSIONS => 2

为当前表删除列族:
HBase(main):002:0> alter ‘user’, ‘delete’ => ‘CF2’

9 disable/enable
禁用一张表/启用一张表
HBase> disable ‘user’
HBase> enable ‘user’

10 drop
删除一张表,记得在删除表之前必须先禁用
11 truncate
禁用表-删除表-创建表
七 Hive与HBase的集成
Hive提供了与HBase的集成,使得能够在HBase表上使⽤HQL语句进⾏查
询 插⼊操作以及进⾏Join和Union等复杂查询、同时也可以将hive表中的
数据映射到Hbase中。
版本说明:
hbase版本:hbase-1.2.0-cdh5.14.2
hive版本:hive-1.1.0-cdh5.14.2
数据模型:
row,addres,age,username
001,guangzhou,20,alex
002,shenzhen,34,jack
003,beijing,23,lili
创建HBase的数据:
create 'stu20210308','info'
put 'stu20210308','001','info:addres','guangzhou'
put 'stu20210308','001','info:age','20'
put 'stu20210308','001','info:username','alex'
put 'stu20210308','002','info:addres','shenzhen'
put 'stu20210308','002','info:age','34'
put 'stu20210308','002','info:username','jack'
put 'stu20210308','003','info:addres','beijing'
put 'stu20210308','003','info:age','23'
put 'stu20210308','003','info:username','lili'


ps:退出HBASE指令是!quit
创建与HBase集成的Hive的外部表:
CREATE EXTERNAL TABLE stu20210308(
id string,
addres string,
age string,
username string)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES (
"hbase.columns.mapping" =
":key,info:addres,info:age,info:username")
TBLPROPERTIES ("hbase.table.name" = "stu20210308");
hive (test)> CREATE EXTERNAL TABLE stu20210308(
> id string,
> addres string,
> age string,
> username string)
> STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
> WITH SERDEPROPERTIES (
> "hbase.columns.mapping" =
> ":key,info:addres,info:age,info:username")
> TBLPROPERTIES ("hbase.table.name" = "stu20210308");
OK
Time taken: 1.933 seconds
hive (test)> select \* from stu20210308;
OK
stu20210308.id stu20210308.addres stu20210308.age stu20210308.username
001 guangzhou 20 alex
002 shenzhen 34 jack
003 beijing 23 lili
Time taken: 0.09 seconds, Fetched: 3 row(s)

ps:具体这里可查看Hive与HBase的集成
Hive表映射HBase实例二
建HBase表
hbase(main):018:0> create ‘user_info’,‘info’
数据插入HBase
info:order_amt
info:order_id
info:user_id
info:user_name

建hive映射表
create external table wedw_tmp.t_user_info
(
id string
,order_id string
,order_amt string
,user_id string
,user_name string
)
STORED by 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
with serdeproperties("hbase.columns.mapping"=":key,info:order\_id,info:order\_amt,info:user\_id,info:user\_name")
tblproperties("hbase.table.name"="user\_info");
查询映射好的hive表
select * from wedw_tmp.t_user_info;

八 HBase客户端API操作
表创建
增加数据
删除数据
全表扫描
过滤器
匹配
九 phoenix操作HBase
Phoenix,由saleforce.com 开源的一个项目,后又捐给了Apache。它相当于一个Java 中间件,帮助开发者,像
使用jdbc 访问关系型数据库一样,访问NoSql 数据库HBase。
Apache Phoenix 与其他Hadoop 产品完全集成,如Spark,Hive,Pig,Flume 和MapReduce。
1 安装pheonix
1.1 下载pheonix
http://phoenix.apache.org/download.html
注意:下载Phoenix 的时候,请注意对应的版本,其中4.14 版本可以运行在HBase0.98、1.1、1.2、1.3、1.4 上。
下载时也可以直接使用:
wget http://mirrors.shu.edu.cn/apache/phoenix/apache-phoenix-4.14.0-HBase-1.2/bin/apache-phoenix-4.14.0-HBase-1.2-bin.tar.gz
1.2 解压pheonix
tar -zxvf apache-phoenix-4.14.0-HBase-1.2-bin.tar.gz

1.3 整合phoenix到hbase
查看Phoenix 下的所有的文件,将phoenix-4.14.0-HBase-1.2-server.jar 拷贝到所有HBase 节点(包括Hmaster以及HregionServer)的lib 目录下:
重启HBase:
bin/stop-hbase.sh
bin/start-hbase.sh
1.4 使用phoenix SQL命令行
进入Phoenix 的安装包,执行:
bin/sqlline.py bigdata1:2181

1.4.1 创建表
在Phoenix 终端下创建us_population 表:
>> CREATE TABLE IF NOT EXISTS us_population (
state CHAR(2) NOT NULL,
city VARCHAR NOT NULL,
population BIGINT
CONSTRAINT my_pk PRIMARY KEY (state, city));
使用!tables 查看创建的表:
>> !tables

1.4.2 编辑并导入数据
在Phoenix 目录下创建一个data 目录,在data 目录下创建:
vi us_population.csv
NY,New York,8143197
CA,Los Angeles,3844829
IL,Chicago,2842518
TX,Houston,2016582
PA,Philadelphia,1463281
AZ,Phoenix,1461575
TX,San Antonio,1256509
CA,San Diego,1255540
TX,Dallas,1213825
CA,San Jose,912332
执行bin/psql.py data/us_population.csv 导入数据。
除了导入数据外,还可以使用Phoenix 的语法插入数据:upsert into us_population values(‘NY’,‘NewYork’,8143197);
1.4.3 查询数据
方式一:在data 目录下创建us_population_queries.sql 文件:
SELECT state as "State",count(city) as "City Count",sum(population) as "Population Sum"
FROM us_population
GROUP BY state
ORDER BY sum(population) DESC;
执行bin/psql.py data/us_population_queries.sql 检索数据。
方式二:使用命令行终端
bin/sqlline.py bigdata1:2181
>> select \* from us_populcation;

2 Squirrel-sql 连接Phoenix
2.1 下载Squirrel-sql
http://www.squirrelsql.org/#installation
2.2 设置Squirrel-sql 连接Phoenix
拷贝Phoenix Client jar【phoenix-4.14.0-HBase-1.2-client.jar】到Squirrel-sql 的lib 目录;

设置Phoenix 连接的Driver 信息,其中localhost 为zookeeper 所在的主机地址,填写一个即可。



3 Phoenix 映射Hbase 表
进入Hbase 命令行终端bin/hbase shell
创建Hbase 表’phoenix’:
– 创建Hbase 表Phoenix,列族info
create ‘phoenix’,‘info’
– 添加数据
put ‘phoenix’, ‘row001’,‘info:name’,‘phoenix’
put ‘phoenix’, ‘row002’,‘info:name’,‘hbase’
映射HBase 表的方式有两种,一直是视图映射,一种是表映射。
两者的区别就是对HBase 的物理表有没有影响;
删除Phoenix 视图映射不会对Hbase 的表造成影响;
删除Phoenix 表映射会将Hbase 的表也删除;
非必要情况下一般创建视图映射。
3.1 视图映射
在Phoenix 下创建视图映射HBase 表:
-- 创建视图关联映射Hbase 表
create view "phoenix" (
pk VARCHAR primary key,
"info"."name" VARCHAR
);
查询创建好的Phoenix 视图:

– 删除视图后,在hbase shell 终端下查看phoenix 依然存在
drop view "phoenix";
3.2 表映射
在Phoenix 下创建表映射HBase 表:
– 创建表关联映射Hbase 表,4.10 以后Phoenix 优化了列映射,COLUMN_ENCODED_BYTES=0 禁用列映射。
create table "phoenix" (
pk VARCHAR primary key,
"info"."name" VARCHAR
) COLUMN_ENCODED_BYTES = 0;
查询数据:

结语:
本篇文章介绍到此结束,码字不易,如果本篇文章对您有所帮助,麻烦动动发财的小手,三连点赞,关注,收藏支持下。有需要沟通交流的,可随时沟通交流,多谢大家支持!!!



总结
三个工作日收到了offer,头条面试体验还是很棒的,这次的头条面试好像每面技术都问了我算法,然后就是中间件、MySQL、Redis、Kafka、网络等等。
- 第一个是算法
关于算法,我觉得最好的是刷题,作死的刷的,多做多练习,加上自己的理解,还是比较容易拿下的。
而且,我貌似是将《算法刷题LeetCode中文版》、《算法的乐趣》大概都过了一遍,尤其是这本
《算法刷题LeetCode中文版》总共有15个章节:编程技巧、线性表、字符串、栈和队列、树、排序、查找、暴力枚举法、广度优先搜索、深度优先搜索、分治法、贪心法、动态规划、图、细节实现题

《算法的乐趣》共有23个章节:


- 第二个是Redis、MySQL、kafka(给大家看下我都有哪些复习笔记)
基本上都是面试真题解析、笔记和学习大纲图,感觉复习也就需要这些吧(个人意见)
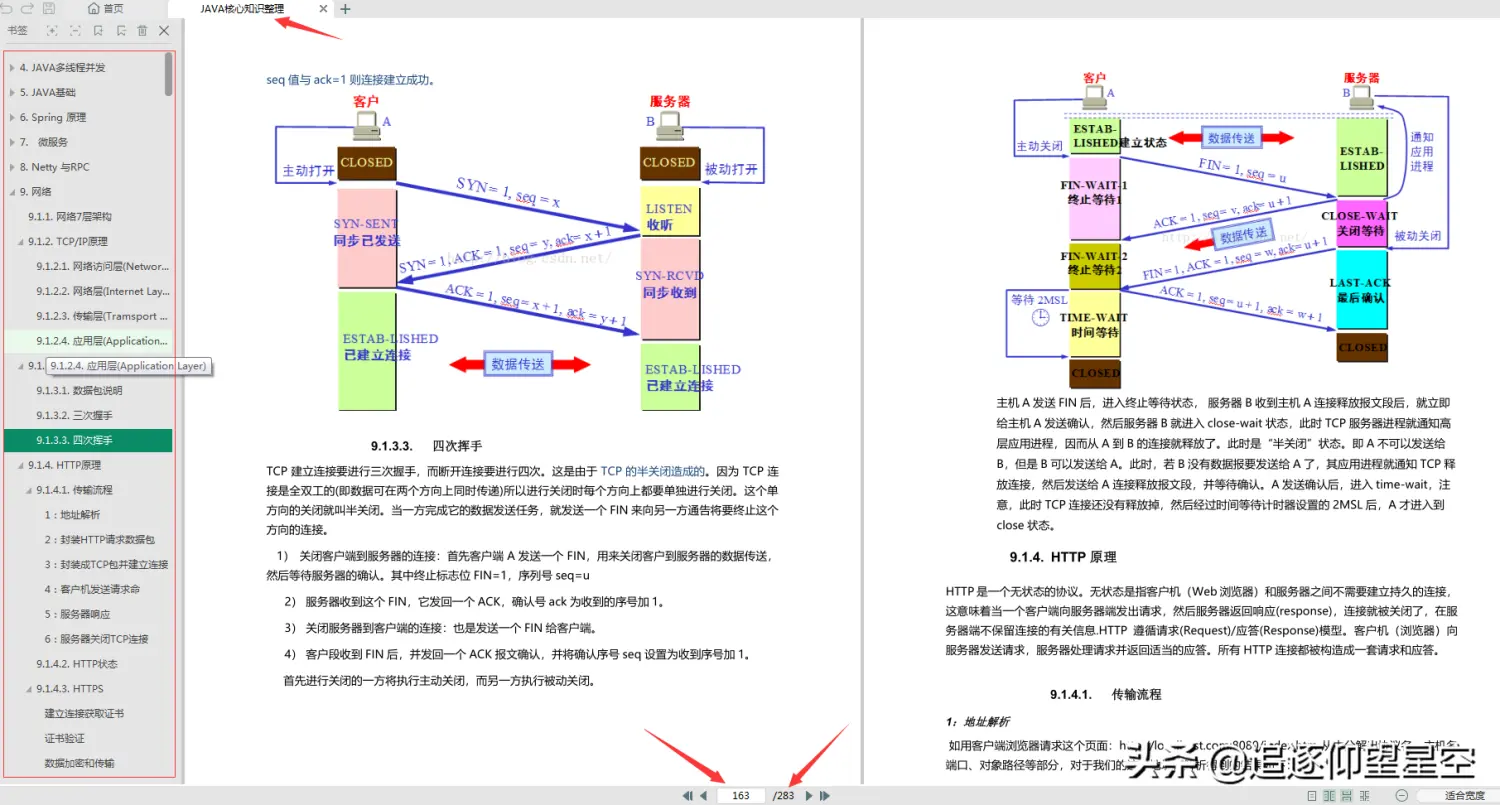
- 第三个是网络(给大家看一本我之前得到的《JAVA核心知识整理》包括30个章节分类,这本283页的JAVA核心知识整理还是很不错的,一次性总结了30个分享的大知识点)
、树、排序、查找、暴力枚举法、广度优先搜索、深度优先搜索、分治法、贪心法、动态规划、图、细节实现题**
[外链图片转存中…(img-IWtXj4zn-1715486705435)]
《算法的乐趣》共有23个章节:
[外链图片转存中…(img-hxCz9sIY-1715486705435)]
[外链图片转存中…(img-hWmNTQBl-1715486705435)]
- 第二个是Redis、MySQL、kafka(给大家看下我都有哪些复习笔记)
基本上都是面试真题解析、笔记和学习大纲图,感觉复习也就需要这些吧(个人意见)
[外链图片转存中…(img-lglZMFbk-1715486705436)]
- 第三个是网络(给大家看一本我之前得到的《JAVA核心知识整理》包括30个章节分类,这本283页的JAVA核心知识整理还是很不错的,一次性总结了30个分享的大知识点)
[外链图片转存中…(img-zoKYsXnh-1715486705436)]


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









