






一、爬取目标
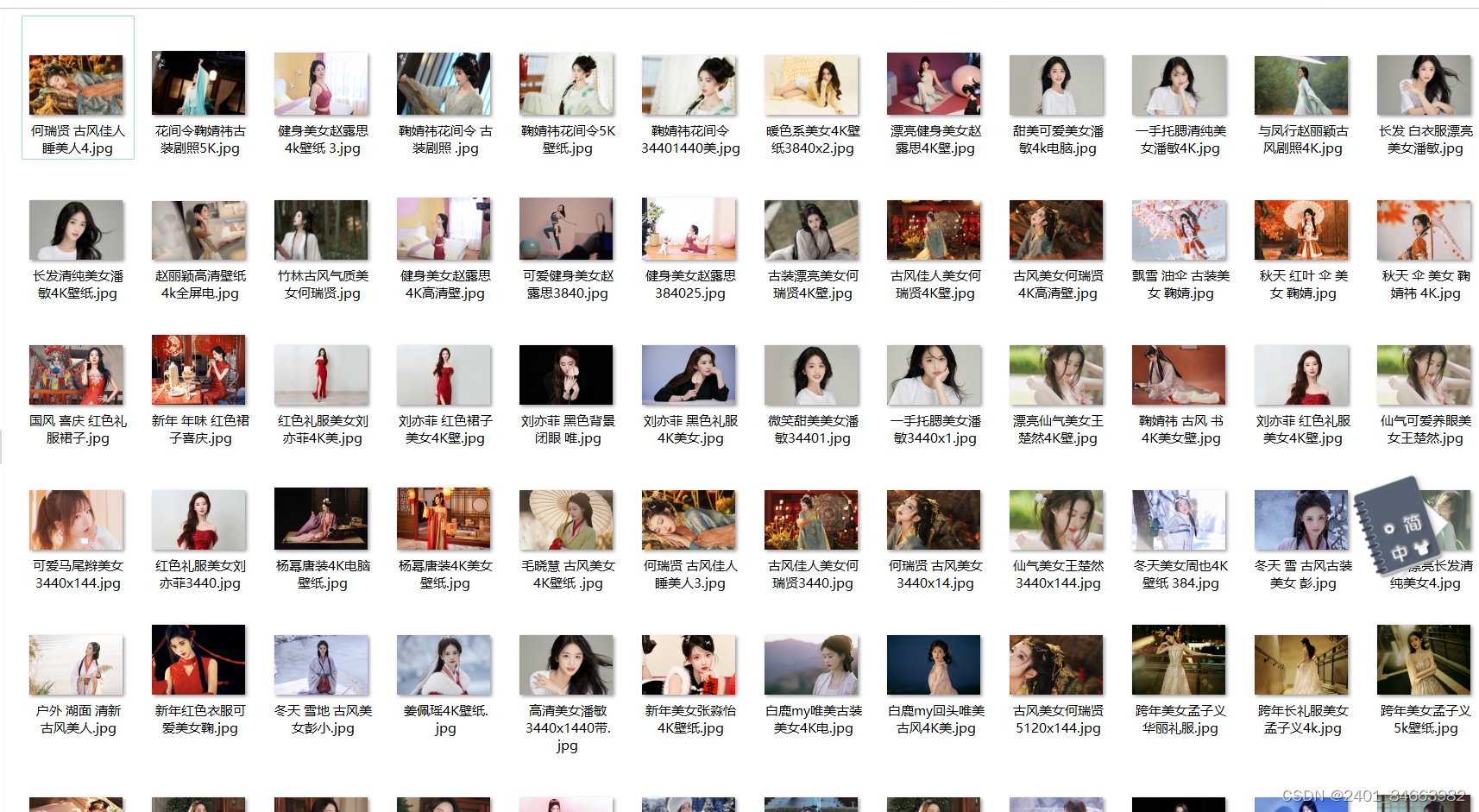
本次的受害者是某网站4K高清小姐姐图片:
二、实现效果:
实现批量下载每一页的图片,存放到指定文件夹中:
三、准备工作:
编辑器:Jupyter Notebook
第三方模块,自行安装:
pip install requests # 网页数据爬取
pip install lxml # 提取网页数据
四、代码实战
4.1导入模块
import requests # python基础爬虫库
from lxml import etree # 可以将网页转换为Elements对象
import re 用来处理图片名称中的特殊字符
import os # 创建文件
import time # 防止爬取过快可以睡眠一秒4.2设置翻页
首先我们来分析一下网页,一共有48页:

根据每一页的url变化,我们可以写一个循环来实现自动翻页来构造所有网页的链接:
# 爬取多页图片
for page in range(1, 48):
url = base_url + f"index_{page}.html"4.3获取图片链接:
可以看到所以图片的url都在ul[@class='clearfix']标签>li标签>a标签>img标签下:
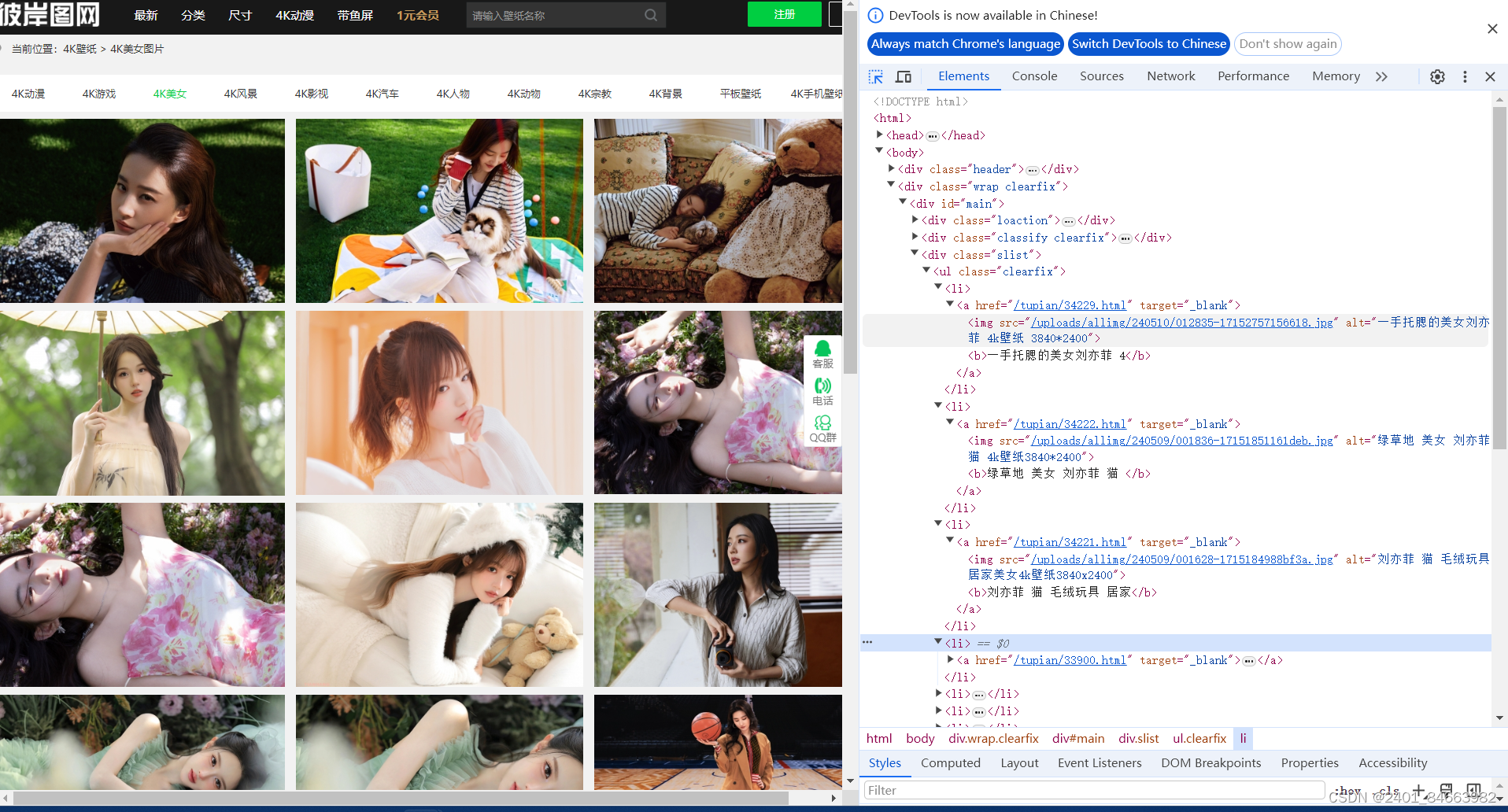
知道图片的URL在哪之后,我们可以用xpath语句获取链接,为后续下载图片做好准备。
# 请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36'
}
# 发送请求
response = requests.get(url=url, headers=headers)
# 设置编码格式
response.encoding = 'gbk'
# 获取网页源码
tree = etree.HTML(response.text)
# 利用xpath语句取到所有图片的URL以及图片名字
img_src = tree.xpath("//ul[@class='clearfix']//li/a/img/@src")
img_name = tree.xpath("//ul[@class='clearfix']//li/a/b/text()")4.4调用主函数,下载图片
图片有了,进入内部循环,遍历当前页面中的每张图片,以及使用正则表达式替换特殊字符,确保图片名称合法,发送HTTP请求下载图片,并休眠一秒,将下载的图片保存到本地文件中,下载完毕打印“图片已下载完毕”字样。
# 爬取多页图片
for page in range(1, 48):
url = base_url + f"index_{page}.html"
response = requests.get(url=url, headers=headers)
response.encoding = 'gbk'
tree = etree.HTML(response.text)
img_src = tree.xpath("//ul[@class='clearfix']//li/a/img/@src")
img_name = tree.xpath("//ul[@class='clearfix']//li/a/b/text()")
for i in range(len(img_src)):
src = "https://pic.netbian.com" + img_src[i]
name = img_name[i]
# 使用正则表达式替换特殊字符
name = re.sub(r'[\\/:*?"<>|]', '', name)
resp = requests.get(src, headers=headers).content
sleep(1)
with open(f"./image1/{name}.jpg", "wb+") as f:
f.write(resp)
print(f"第 {page} 页下载完毕")
print("所有页面下载完毕.")5、完整源码
完整代码如下:
import os
import requests
from lxml import etree
from time import sleep
import re
# 创建文件夹
os.makedirs('image1', exist_ok=True)
# 给定爬取的网站
base_url = "https://pic.netbian.com/4kmeinv/"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36'
}
# 爬取多页图片
for page in range(1, 48):
url = base_url + f"index_{page}.html"
response = requests.get(url=url, headers=headers)
response.encoding = 'gbk'
tree = etree.HTML(response.text)
img_src = tree.xpath("//ul[@class='clearfix']//li/a/img/@src")
img_name = tree.xpath("//ul[@class='clearfix']//li/a/b/text()")
for i in range(len(img_src)):
src = "https://pic.netbian.com" + img_src[i]
name = img_name[i]
# 使用正则表达式替换特殊字符
name = re.sub(r'[\\/:*?"<>|]', '', name)
resp = requests.get(src, headers=headers).content
sleep(1)
with open(f"./image1/{name}.jpg", "wb+") as f:
f.write(resp)
print(f"第 {page} 页下载完毕")
print("所有页面下载完毕.")
运行结果:
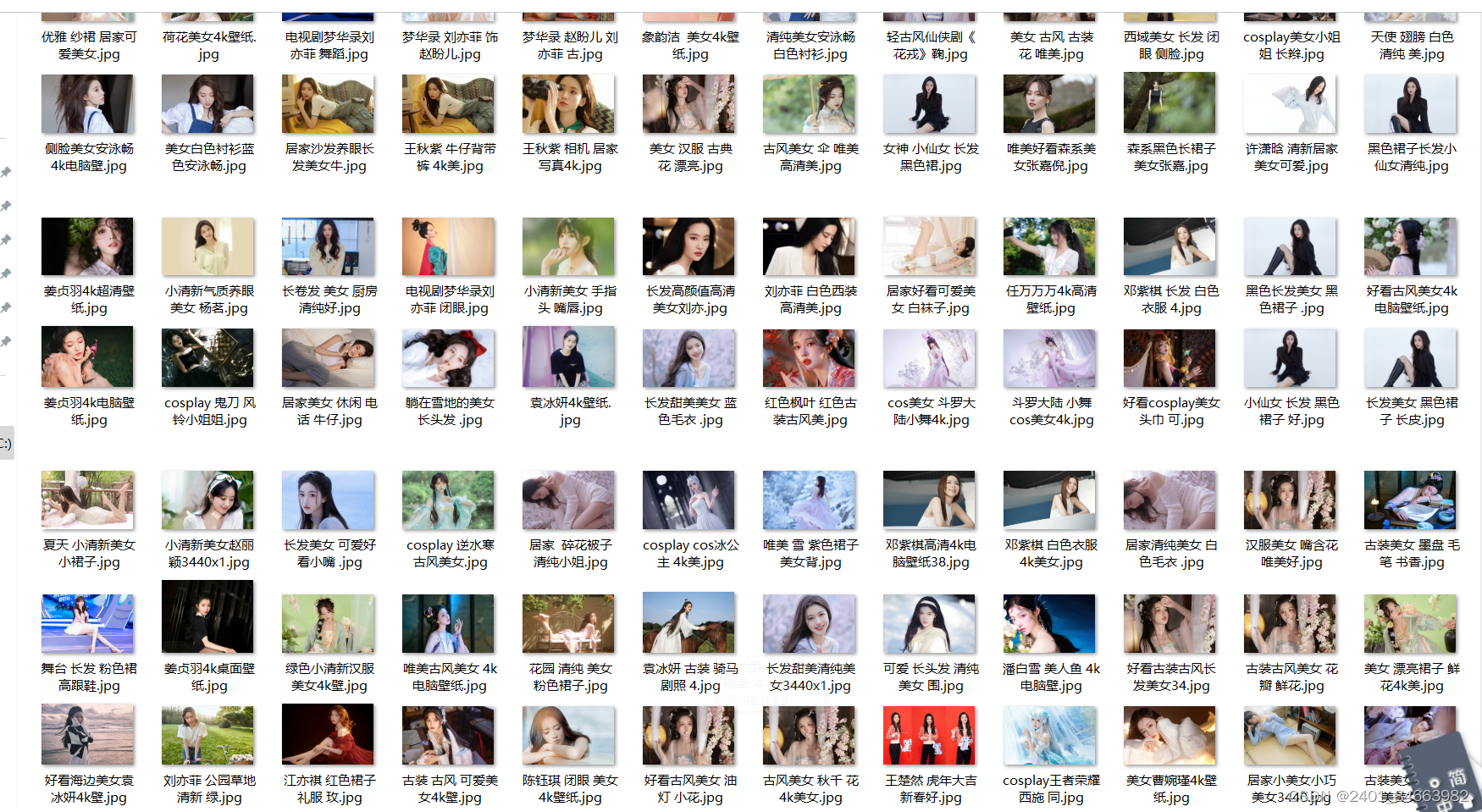
下载成功没有报错!!!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









